Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Processus de migration hors ligne : Apache Cassandra vers Amazon Keyspaces
Les migrations hors ligne conviennent lorsque vous pouvez vous permettre une interruption de service pour effectuer la migration. Il est courant dans les entreprises d'avoir des fenêtres de maintenance pour les correctifs, les versions volumineuses ou des temps d'arrêt pour les mises à niveau matérielles ou les mises à niveau majeures. La migration hors ligne peut utiliser cette fenêtre pour copier des données et transférer le trafic de l'application d'Apache Cassandra vers Amazon Keyspaces.
La migration hors ligne réduit les modifications apportées à l'application car elle ne nécessite pas de communication simultanée avec Cassandra et Amazon Keyspaces. De plus, lorsque le flux de données est suspendu, l'état exact peut être copié sans conserver les mutations.
Dans cet exemple, nous utilisons Amazon Simple Storage Service (Amazon S3) comme zone intermédiaire pour les données lors de la migration hors ligne afin de minimiser les temps d'arrêt. Vous pouvez importer automatiquement les données que vous avez stockées au format Parquet dans Amazon S3 dans une table Amazon Keyspaces à l'aide du connecteur Spark Cassandra et. AWS Glue La section suivante va présenter un aperçu général du processus. Vous pouvez trouver des exemples de code pour ce processus sur Github
Le processus de migration hors ligne d'Apache Cassandra vers Amazon Keyspaces à l'aide d'Amazon S3 nécessite AWS Glue les AWS Glue tâches suivantes.
Une tâche ETL qui extrait et transforme les données CQL et les stocke dans un compartiment Amazon S3.
Une deuxième tâche qui importe les données du bucket vers Amazon Keyspaces.
Une troisième tâche pour importer des données incrémentielles.
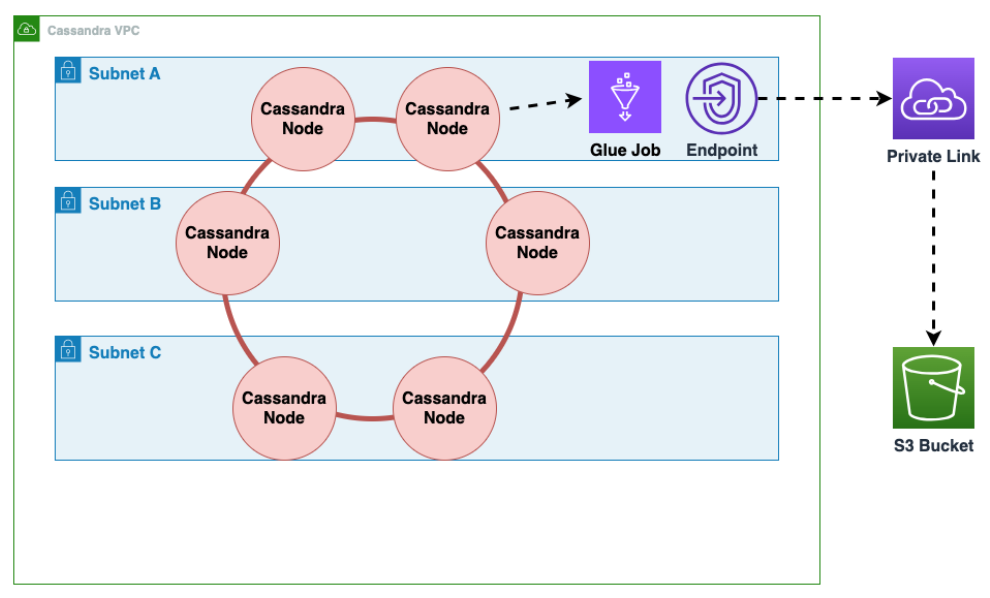
Comment effectuer une migration hors ligne vers Amazon Keyspaces depuis Cassandra exécutée sur Amazon EC2 dans un Amazon Virtual Private Cloud
Vous devez d'abord AWS Glue exporter les données de table de Cassandra au format Parquet et les enregistrer dans un compartiment Amazon S3. Vous devez exécuter une AWS Glue tâche à l'aide d'un AWS Glue connecteur vers un VPC où réside l'instance Amazon EC2 exécutant Cassandra. Ensuite, à l'aide du point de terminaison privé Amazon S3, vous pouvez enregistrer des données dans le compartiment Amazon S3.
Le schéma suivant illustre ces étapes.
Répartissez les données dans le compartiment Amazon S3 pour améliorer la randomisation des données. Les données importées de manière uniforme permettent de répartir davantage le trafic dans la table cible.
Cette étape est requise lors de l'exportation de données depuis Cassandra avec de grandes partitions (partitions de plus de 1 000 lignes) afin d'éviter les raccourcis clavier lors de l'insertion des données dans Amazon Keyspaces. Les principaux problèmes affectent
WriteThrottleEventsAmazon Keyspaces et augmentent le temps de chargement.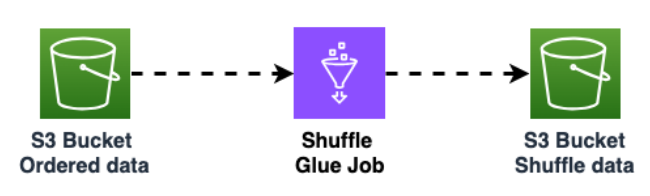
Utilisez une autre AWS Glue tâche pour importer des données depuis le compartiment Amazon S3 vers Amazon Keyspaces. Les données mélangées dans le compartiment Amazon S3 sont stockées au format Parquet.
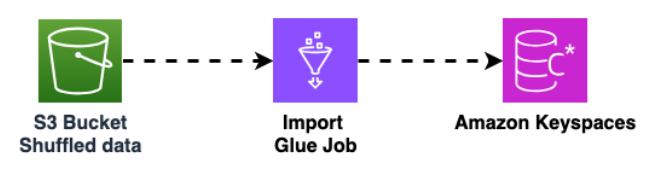
Pour plus d'informations sur le processus de migration hors ligne, consultez l'atelier Amazon Keyspaces
