Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Gestion des autorisations sur les ensembles de données qui utilisent des métastores externes
Grâce à la fédération des AWS Glue Data Catalog métadonnées (fédération du catalogue de données), vous pouvez connecter le catalogue de données à des métastores externes qui stockent les métadonnées de vos données Amazon S3 et gérer en toute sécurité les autorisations d'accès aux données à l'aide de. AWS Lake Formation Il n'est pas nécessaire de migrer les métadonnées du métastore externe vers le catalogue de données.
Le catalogue de données fournit un référentiel de métadonnées centralisé qui facilite la gestion et la découverte de données sur des systèmes disparates. Lorsque votre organisation gère les données du catalogue de données, vous pouvez les utiliser AWS Lake Formation pour contrôler l'accès à vos ensembles de données dans Amazon S3.
Note
Actuellement, nous prenons uniquement en charge la fédération de métastores Apache Hive (version 3 et supérieure).
Pour configurer la fédération de catalogues de données, nous fournissons une application AWS Serverless Application Model (AWS SAM) appelée GlueDataCatalogFederation- HiveMetastore
L'implémentation de référence est fournie GitHub sous forme de projet open source sur AWS Glue Data Catalog Federation - Hive Metastore
L' AWS SAM application crée et déploie les ressources suivantes qui sont nécessaires pour connecter le catalogue de données au métastore Hive :
Une AWS Lambda fonction : héberge l'implémentation du service de fédération qui communique entre le catalogue de données et le métastore Hive. AWS Glue invoque cette fonction Lambda pour récupérer des objets de métadonnées depuis le métastore Hive.
Amazon API Gateway— Le point de connexion de votre métastore Hive qui agit comme un proxy pour acheminer toutes les invocations vers la fonction Lambda.
Rôle IAM : rôle doté des autorisations nécessaires pour créer la connexion entre le catalogue de données et le métastore Hive.
AWS Glue connection — Amazon API Gateway Type de AWS Glue connexion qui stocke le Amazon API Gateway point de terminaison et un rôle IAM pour l'invoquer.
Lorsque vous interrogez des tables, le AWS Glue service effectue un appel d'exécution vers le métastore Hive et récupère les métadonnées. La fonction Lambda agit comme un traducteur entre le métastore Hive et le catalogue de données.
Après avoir établi la connexion, afin de synchroniser les métadonnées du métastore Hive avec le catalogue de données, vous devez créer une base de données fédérée dans le catalogue de données à l'aide des détails de connexion du métastore Hive, et mapper cette base de données à la base de données Hive. Une base de données est qualifiée de base de données fédérée lorsqu'elle pointe vers une entité extérieure au catalogue de données.
Vous pouvez appliquer les autorisations de Lake Formation à l'aide du contrôle d'accès basé sur des balises et de la méthode des ressources nommées sur la base de données fédérée Comptes AWS AWS Organizations, et les partager entre plusieurs unités organisationnelles (UO). Vous pouvez également partager la base de données fédérée directement avec les principaux IAM depuis un autre compte.
Vous pouvez définir des autorisations détaillées au niveau des colonnes, des lignes et des cellules à l'aide des filtres de données Lake Formation sur les tables Hive externes. Vous pouvez utiliser Amazon Athena, Amazon Redshift ou Amazon EMR pour interroger les tables Hive externes gérées par Lake Formation.
Pour plus d'informations sur le partage de données entre comptes et le filtrage des données, voir :
Étapes générales de fédération des métadonnées du catalogue de données
-
Vous créez des utilisateurs et des rôles IAM dotés des autorisations appropriées pour déployer l' AWS SAM application et créer des bases de données fédérées.
-
Vous enregistrez l'emplacement des données Amazon S3 auprès de Lake Formation en sélectionnant l'
Enable Data Catalog federationoption pour les ensembles de données qui utilisent un métastore Hive externe. Vous configurez les paramètres de l' AWS SAM application (nom de AWS Glue connexion, URL du métastore Hive et paramètres de la fonction Lambda) et déployez l'application. AWS SAM
-
L' AWS SAM application déploie les ressources nécessaires pour connecter le métastore Hive externe au catalogue de données.
-
Pour appliquer les autorisations Lake Formation à la base de données et aux tables Hive, vous créez une base de données dans le catalogue de données à l'aide des détails de connexion au métastore Hive, et vous mappez cette base de données à la base de données Hive.
Accordez des autorisations sur les bases de données fédérées aux principaux de votre compte ou d'un autre compte.
Note
Vous pouvez connecter le catalogue de données à un mestastore Hive externe, créer des bases de données fédérées et exécuter des requêtes et des scripts ETL sur des bases de données et des tables Hive sans appliquer les autorisations de Lake Formation. Pour les données source dans Amazon S3 qui ne sont pas enregistrées auprès de Lake Formation, l'accès est déterminé par les politiques d'autorisation IAM pour Amazon S3 et AWS Glue les actions.
Pour connaître les limitations, veuillez consulter Considérations et limites relatives au partage des données du magasin de métadonnées Hive.
Rubriques
Flux de travail
Le schéma suivant montre le flux de travail pour connecter le AWS Glue Data Catalog à un métastore Hive externe.
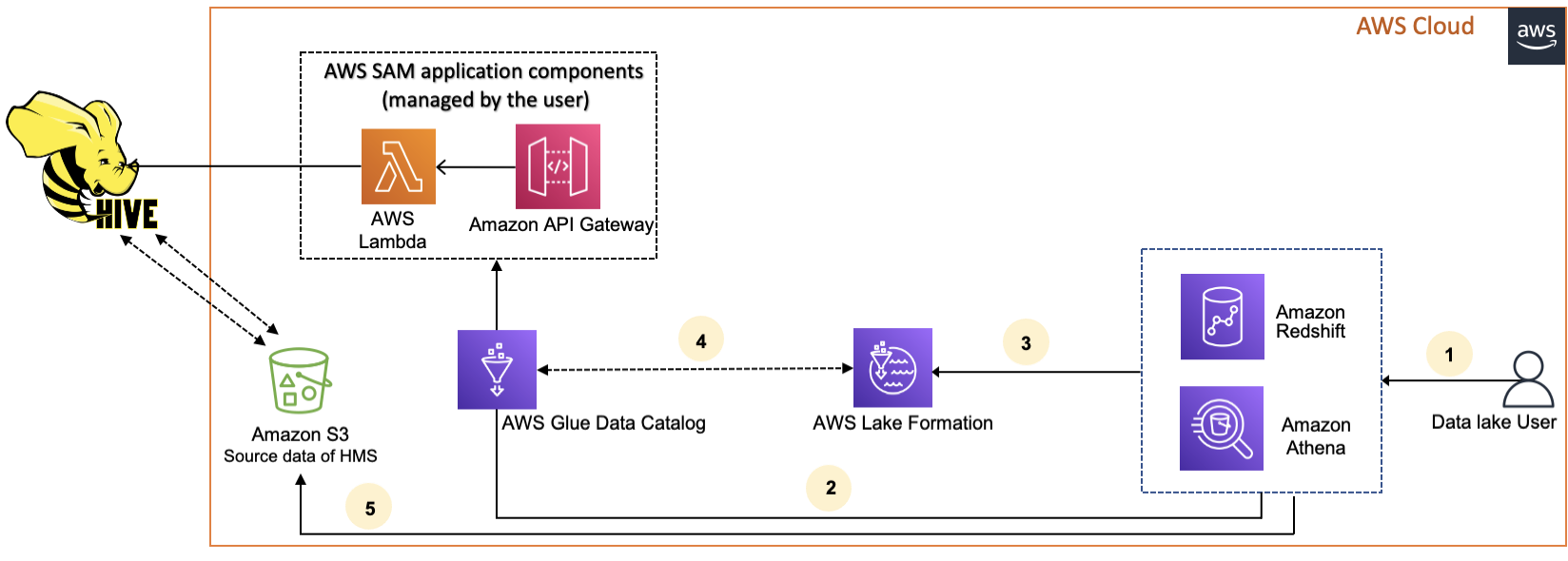
-
Un directeur soumet une requête à l'aide d'un service intégré tel qu'Athena ou Redshift Spectrum.
Le service intégré appelle le catalogue de données pour obtenir les métadonnées, qui à son tour appelle le point de terminaison du métastore Hive disponible derrière Amazon API Gateway et reçoit les réponses aux demandes de métadonnées.
-
Le service intégré envoie la demande à Lake Formation pour vérifier les informations de la table et les informations d'identification pour accéder à la table.
-
Lake Formation autorise la demande et fournit des informations d'identification temporaires à l'application intégrée, qui permet l'accès aux données.
À l'aide des informations d'identification temporaires reçues de Lake Formation, le service intégré lit les données d'Amazon S3 et partage les résultats avec le principal.
