Nous ne mettons plus à jour le service Amazon Machine Learning et n'acceptons plus de nouveaux utilisateurs pour ce service. Cette documentation est disponible pour les utilisateurs existants, mais nous ne la mettons plus à jour. Pour plus d'informations, veuillez consulter la rubriqueQu'est-ce qu'Amazon Machine Learning.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Classification binaire
La sortie réelle de nombreux algorithmes de classification binaire est un score de prédiction. Ce score indique la certitude du système que l'observation donnée appartient à la classe positive. Pour décider si l'observation doit être classée comme positive ou négative, en tant que consommateur de ce score, vous devez interpréter le score en sélectionnant une limite de classification, ou seuil, et comparer le score à ce seuil. Toute observation avec un score supérieur au seuil est alors prédite en tant que classe positive et tout score inférieur au seuil en tant que classe négative.
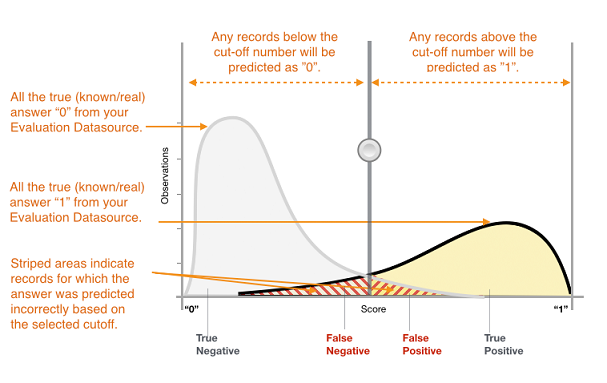
Figure 1 : Distribution des scores pour un modèle de classification binaire
Les prédictions se répartissent désormais en quatre groupes en fonction de la réponse réelle connue et de la réponse prédite : prédictions positives correctes (vrais positifs), prédictions négatives correctes (vrais négatifs), prédictions positives erronées (faux positifs) et prédictions négatives erronées (faux négatifs).
Les métriques de précision de classification binaire quantifient les deux types de prédictions correctes et les deux types d'erreurs. Les métriques standard sont la précision (ACC), le taux de positifs prédits, la sensibilité, le taux de faux négatifs, la mesure F1. Chaque métrique mesure un aspect différent du modèle prédictif. La précision (ACC) mesure la fraction de prédictions correctes. Le taux de positifs prédits mesure la fraction de positifs observés parmi les exemples prédits comme positifs. La sensibilité mesure le nombre de positifs observés qui ont été prédits comme positifs. La mesure F1 représente la moyenne harmonique entre le taux de positifs prédits et la sensibilité.
La métrique AUC est d'un autre type. Elle mesure l'aptitude du modèle à prédire un score plus élevé pour les exemples positifs par rapport aux exemples négatifs. Comme la métrique AUC est indépendante du seuil sélectionné, elle vous permet de vous faire une idée des performances de prédictions de votre modèle, sans choisir de seuil.
En fonction de votre problème, vous pouvez être plus intéressé par un modèle performant pour un sous-ensemble spécifique de ces métriques. Par exemple, deux applications métier peuvent avoir des exigences très différentes en matière de modèles d'apprentissage-machine :
Une application peut avoir besoin d'être extrêmement certaine que les prédictions positives soient effectivement positives (taux de positifs prédits élevé) et peut se permettre de mal classer certains exemples positifs comme négatifs (sensibilité moyenne).
Une autre application peut avoir besoin de prédire correctement autant d'exemples positifs que possible (haute sensibilité) et acceptera que certains exemples négatifs soient mal classés comme positifs (taux de positifs prédits moyen).
Dans Amazon ML, les observations obtiennent un score prédit dans la plage [0,1]. Le score seuil permettant de décider de classer les exemples en tant que 0 ou 1 est défini par défaut à 0,5. Amazon ML vous permet d'examiner les implications attenant au choix de différents scores seuils, et vous permet de choisir un seuil approprié à vos besoins professionnels.
