Nous ne mettons plus à jour le service Amazon Machine Learning et n'acceptons plus de nouveaux utilisateurs pour celui-ci. Cette documentation est disponible pour les utilisateurs existants, mais nous ne la mettons plus à jour. Pour plus d'informations, consultez Qu'est-ce qu'Amazon Machine Learning ?
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Analyse des données
Amazon ML calcule des statistiques descriptives sur vos données d'entrée que vous pouvez utiliser pour comprendre vos données.
Statistiques descriptives
Amazon ML calcule les statistiques descriptives suivantes pour différents types d'attributs :
Numérique:
-
Histogrammes de distribution
-
Nombre de valeurs non valides
-
Valeurs minimale, médiane, moyenne et maximale
Binary (binaire) et Categorical (catégorie) :
-
Nombre (de valeurs distinctes par catégorie)
-
Histogramme de distribution de valeurs
-
Valeurs les plus fréquentes
-
Nombres de valeurs uniques
-
Pourcentage de valeur vraie (binaire uniquement)
-
Mots les plus visibles
-
Mots les plus fréquents
Text:
-
Nom de l'attribut
-
Corrélation avec la cible (si une cible est définie)
-
Total de mots
-
Mots uniques
-
Plage du nombre de mots dans une ligne
-
Plage des longueurs de mot
-
Mots les plus visibles
Accès à Data Insights sur la console Amazon ML
Sur la console Amazon ML, vous pouvez choisir le nom ou l'ID de n'importe quelle source de données pour afficher sa page Data Insights. Cette page fournit des métriques et des visualisations qui vous permettent d'en savoir plus sur les données d'entrée associées à la source de données, y compris les informations suivantes :
-
Récapitulatif des données
-
Distributions cibles
-
Valeurs manquantes
-
Valeurs non valides
-
Statistiques récapitulatives des variables par type de données
-
Distributions des variables par type de données
Les sections suivantes décrivent les métriques et les visualisations de manière plus détaillée.
Récapitulatif des données
Le rapport récapitulatif des données d'une source de données affiche des informations récapitulatives, y compris l'ID de la source de données, son nom, l'emplacement où elle a été élaborée, l'état actuel, l'attribut cible, les informations de saisie de données (emplacement du compartiment S3, format des données, nombre d'enregistrements traités et nombre d'enregistrements incorrects rencontrés lors du traitement) ainsi que le nombre de variables par type de données.
Distributions cibles
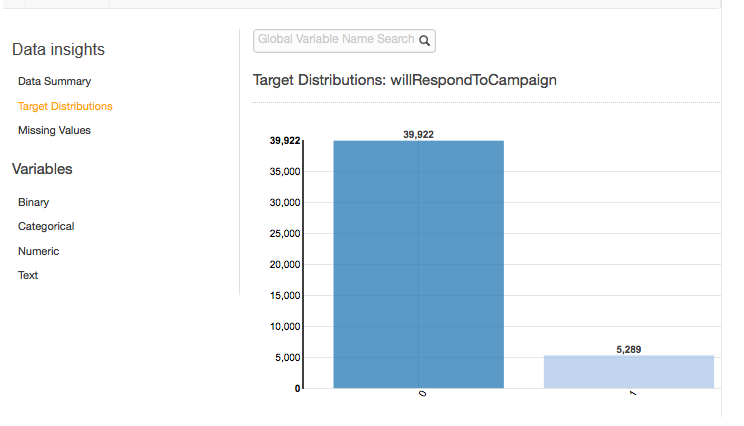
Le rapport des distributions cibles montre la distribution de l'attribut cible de la source de données. Dans l'exemple suivant, il existe 39 922 observations pour lesquelles l'attribut will RespondToCampaign target est égal à 0. Il s'agit du nombre de clients qui n'ont pas répondu à la campagne d'e-mail. Il y a 5 289 observations où will RespondToCampaign est égal à 1. Il s'agit du nombre de clients qui ont répondu à la campagne d'e-mail.
Valeurs manquantes
Le rapport des valeurs manquantes répertorie les attributs dans les données d'entrée pour lesquels des valeurs sont manquantes. Seuls les attributs d'un type de données numérique peuvent avoir des valeurs manquantes. Etant donné que des valeurs manquantes peuvent affecter la qualité de formation d'un modèle d'apprentissage-machine, nous vous recommandons de fournir les valeurs manquantes, si possible.
Pendant l'entraînement du modèle ML, si l'attribut cible est absent, Amazon ML rejette l'enregistrement correspondant. Si l'attribut cible est présent dans l'enregistrement, mais qu'une valeur pour un autre attribut numérique est manquante, Amazon ML ignore la valeur manquante. Dans ce cas, Amazon ML crée un attribut de remplacement et le définit sur 1 pour indiquer que cet attribut est manquant. Cela permet à Amazon ML d'apprendre des modèles à partir de l'occurrence de valeurs manquantes.
Valeurs non valides
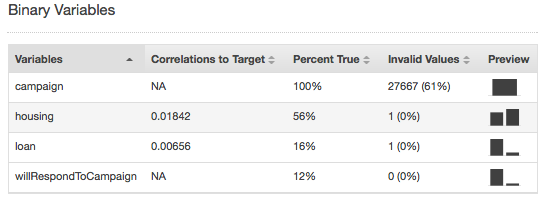
Des valeurs non valides peuvent survenir uniquement avec les types de données Numeric (numérique) et Binary (binaire). Vous pouvez relever des valeurs non valides en affichant les statistiques récapitulatives des variables dans les rapports par type de données. Dans les exemples suivants, il y a une valeur non valide dans l'attribut numérique de durée et deux valeurs non valides de type de données binaire (une dans l'attribut de logement et l'autre dans l'attribut de prêt).

Variable-Target Corrélation
Après avoir créé une source de données, Amazon ML peut évaluer la source de données et identifier la corrélation, ou l'impact, entre les variables et la cible. Par exemple, le prix d'un produit peut avoir un impact significatif sur le fait qu'il compte ou non parmi les meilleures ventes de l'année, tandis que les dimensions du produit peuvent n'avoir qu'une faible valeur prédictive.
Une bonne pratique consiste généralement à inclure autant de variables que possible dans les données de formation. Toutefois, le bruit introduit en incluant de nombreuses variables à faible valeur prédictive peut avoir une incidence négative sur la qualité et l'exactitude de votre modèle d'apprentissage-machine.
Vous pouvez améliorer les performances prédictives de votre modèle en supprimant des variables qui n'ont que peu d'impact lorsque vous formez votre modèle. Vous pouvez définir les variables mises à disposition du processus d'apprentissage automatique dans une recette, qui est un mécanisme de transformation d'Amazon ML. Pour en savoir plus sur les recettes, consultez Transformation des données pour l'apprentissage-machine.
Statistiques récapitulatives des attributs par type de données
Dans le rapport d'analyse des données, vous pouvez visualiser des statistiques récapitulatives d'attribut des types de données suivants :
-
Binaire
-
Categorical (catégorie)
-
Numérique
-
Texte
Les statistiques récapitulatives pour le type de données binaire (Binary) montrent tous les attributs binaires. La colonne Correlations to target (Corrélations avec la cible) montre les informations partagées entre la colonne cible et la colonne d'attribut. La colonne Percent true (Pourcentage true) indique le pourcentage d'observations de valeur 1. La colonne Invalid values (Valeurs non valides) indique le nombre de valeurs non valides, ainsi que le pourcentage de valeurs non valides pour chaque attribut. La colonne Aperçu fournit un lien vers un graphique de distribution pour chaque attribut.
Les statistiques récapitulatives pour le type de données Categorical (catégorie) affichent tous les attributs de catégorie avec le nombre de valeurs uniques, la valeur la plus fréquente et la valeur la moins fréquente. La colonne Aperçu fournit un lien vers un graphique de distribution pour chaque attribut.
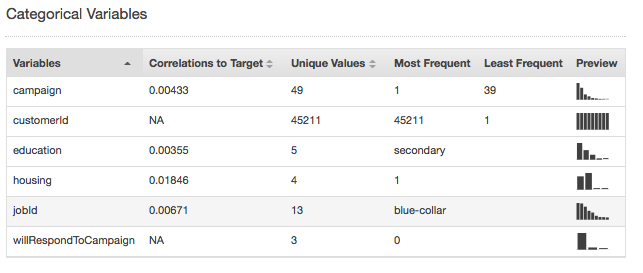
Les statistiques récapitulatives pour le type de données Numeric (numérique) montrent tous les attributs numériques avec le nombre de valeurs manquantes, les valeurs non valides, la plage de valeurs, la moyenne et la valeur médiane. La colonne Aperçu fournit un lien vers un graphique de distribution pour chaque attribut.
Les statistiques récapitulatives pour le type de données Text (texte) montrent tous les attributs texte, le nombre total de mots dans cet attribut, le nombre de mots uniques dans cet attribut, la plage de mots dans un attribut, la plage des longueurs de mot et les mots les plus visibles. La colonne Aperçu fournit un lien vers un graphique de distribution pour chaque attribut.

L'exemple suivant montre les statistiques du type de données Text pour une variable texte appelée revue, avec quatre enregistrements.
1. The fox jumped over the fence. 2. This movie is intriguing. 3. 4. Fascinating movie.
Pour cet exemple, les colonnes indiquent les informations suivantes.
-
La colonne Attributes indique le nom de la variable. Dans cet exemple, cette colonne indique « revue ».
-
La colonne Correlations to target existe uniquement si une cible est spécifiée. La corrélation mesure la quantité d'informations que cet attribut fournit sur la cible. Plus la corrélation est élevée, plus cet attribut vous donne d'informations sur la cible. La corrélation est mesurée en termes d'informations mutuelles entre une représentation simplifiée de l'attribut texte et la cible.
-
La colonne Total words indique le nombre de mots générés lors de la segmentation (génération de jetons) de chaque enregistrement, les mots étant délimités par des espaces. Dans cet exemple, cette colonne indique « 12 ».
-
La colonne Unique words indique le nombre de mots uniques pour un attribut. Dans cet exemple, cette colonne indique « 10 ».
-
La colonne Words in attribute (range) indique le nombre de mots dans les lignes individuelles de l'attribut. Dans cet exemple, cette colonne indique « 0-6 ».
-
La colonne Word length (range) indique la plage des nombres de caractères dans les mots. Dans cet exemple, cette colonne indique « 2-11 ».
-
La colonne Most prominent words affiche une liste classant les mots qui figurent dans l'attribut. S'il y a un attribut cible, les mots sont classés en fonction de leur corrélation avec la cible, ce qui signifie que les mots de plus forte corrélation sont les premiers répertoriés. Si aucune cible n'est présente dans les données, les mots sont classés en fonction de leur entropie.
Présentation de la distribution des attributs binaires et de catégorie
En cliquant sur le lien Aperçu associé à un attribut binaire ou de catégorie, vous pouvez afficher la distribution de cet attribut, ainsi que les exemples de données issus du fichier d'entrée pour chaque valeur de catégorie de l'attribut.
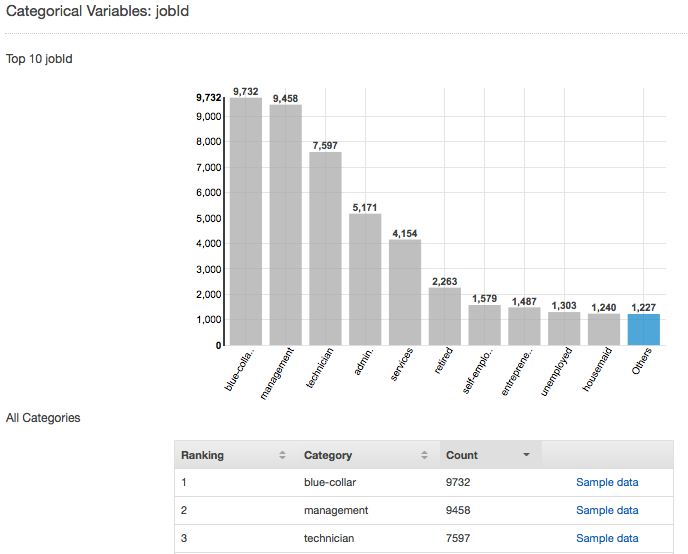
Par exemple, la capture d'écran suivante illustre la distribution de l'attribut de catégorie JobId. Cette distribution affiche les 10 valeurs de catégorie les plus élevées, avec toutes les autres valeurs regroupées dans « Autres ». Elle classe chacune des 10 valeurs de catégorie les plus élevées avec le nombre d'observations dans le fichier d'entrée qui contiennent cette valeur, ainsi qu'un lien pour afficher les exemples d'observations à partir du fichier de données d'entrée.
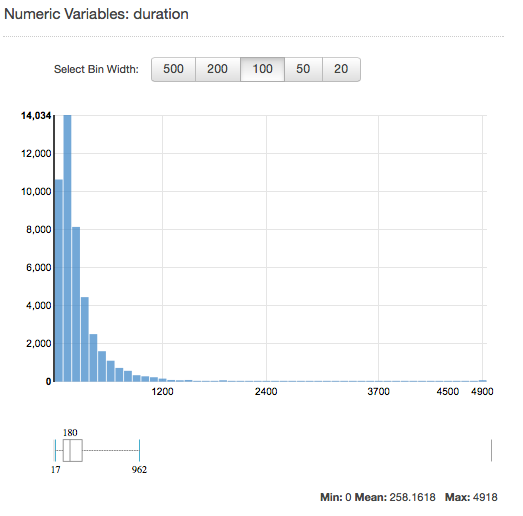
Présentation de la distribution des attributs numériques
Pour afficher la distribution d'un attribut numérique, cliquez sur le lien Aperçu de cet attribut. Lorsque vous consultez la distribution d'un attribut numérique, vous pouvez choisir une taille de compartiment de 500, 200, 100, 50 ou 20. Plus la taille de compartiment est élevée, plus le nombre de barres de graphique affichées sera bas. De plus, la résolution de la distribution est grossière pour de grandes tailles de compartiment. Au contraire, la configuration d'une taille de compartiment de 20 augmente la résolution de la distribution affichée.
Les valeurs minimale, moyenne et maximale sont également affichées, comme illustré dans la capture d'écran ci-dessous.
Présentation de la distribution des attributs texte
Pour afficher la distribution d'un attribut texte, cliquez sur le lien Aperçu de cet attribut. Lorsque vous consultez la distribution d'un attribut texte, vous voyez les informations suivantes.
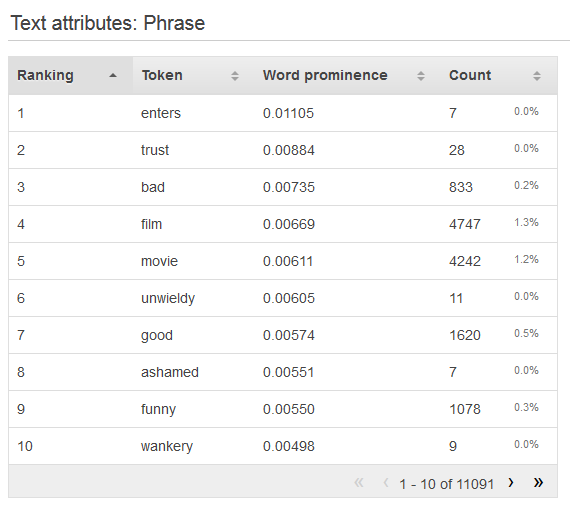
- Ranking (classement)
-
Les jetons de texte sont classés en fonction de la quantité d'informations qu'ils convoient, des plus informatifs aux moins informatifs.
- Jeton
-
La colonne Token indique le mot issu du texte d'entrée auquel se rapporte la ligne de statistiques.
- Word prominence (Prédominance du mot)
-
S'il y a un attribut cible, les mots sont classés en fonction de leur corrélation avec la cible, de sorte que les mots de plus forte corrélation sont les premiers répertoriés. Si les données ne contiennent pas de cible, les mots sont classés en fonction de leur entropie, c'est-à-dire de la quantité d'informations qu'ils peuvent communiquer.
- Count (décompte)
-
Ce nombre indique le nombre d'enregistrements d'entrée dans lesquels le jeton apparaît.
- Pourcentage
-
Ce pourcentage indique le pourcentage des lignes de données d'entrée où le jeton apparaît.
