Nous ne mettons plus à jour le service Amazon Machine Learning et n'acceptons plus de nouveaux utilisateurs pour celui-ci. Cette documentation est disponible pour les utilisateurs existants, mais nous ne la mettons plus à jour. Pour plus d'informations, consultez Qu'est-ce qu'Amazon Machine Learning ?
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Ajustement du modèle : sous-ajustement et surajustement
Comprendre l'ajustement du modèle est important pour comprendre la cause profonde de la mauvaise précision du modèle. Cette analyse vous guidera pour prendre des mesures correctives. Nous pouvons déterminer si un modèle prédictif constitue un sous-ajustement ou un surajustement des données de formation en examinant l'erreur de prédiction sur les données de formation et les données d'évaluation.
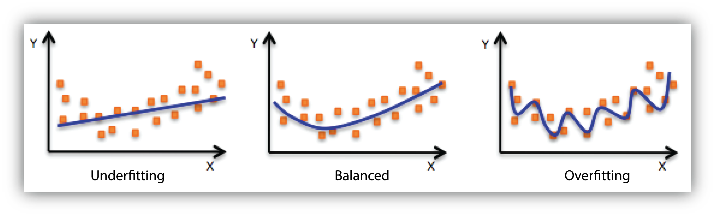
Votre modèle constitue un sous-ajustement des données de formation lorsque le modèle donne des résultats médiocres sur les données de formation. Cela est dû au fait que le modèle n'est pas en mesure de saisir la relation entre les exemples en entrée (souvent appelés X) et les valeurs cibles (souvent appelées Y). Votre modèle constitue un surajustement de vos données de formation lorsque vous constatez que le modèle offre de bons résultats sur les données de formation mais des résultats médiocres sur les données d'évaluation. Cela est dû au fait que le modèle mémorise les données qu'il a vues et n'est pas en mesure de généraliser aux exemples nouveaux.
Des performances médiocres sur les données de formation peuvent être dues à un modèle trop simple (les entités en entrée ne sont pas suffisamment expressives) pour décrire correctement la cible. Il est possible d'améliorer les performances en augmentant la flexibilité du modèle. Pour augmenter la flexibilité du modèle, essayez la procédure suivante :
Ajoutez de nouvelles entités spécifiques au domaine et d'autres produits cartésiens d'entités, puis changez le type de traitement d'entités utilisé (par exemple, en augmentant la taille des n-grammes).
Diminuez le degré de régularisation utilisé.
Si votre modèle constitue un surajustement des données de formation, il est logique d'entreprendre des actions qui réduisent la flexibilité du modèle. Pour réduire la flexibilité du modèle, essayez la procédure suivante :
Sélection des entités : envisagez d'utiliser moins de combinaisons d'entités, de diminuer la taille des n-grammes et de réduire le nombre d'intervalles des attributs numériques.
Augmentez le degré de régularisation utilisé.
La mauvaise précision sur les données de formation et de test peut provenir du fait que l'algorithme d'apprentissage ne disposait pas de suffisamment de données d'apprentissage. Vous pouvez améliorer les performances en procédant comme suit :
Augmentez le nombre d'exemples de données de formation.
Augmentez le nombre de passages sur les données de formation existantes.
