Nous ne mettons plus à jour le service Amazon Machine Learning et n'acceptons plus de nouveaux utilisateurs pour celui-ci. Cette documentation est disponible pour les utilisateurs existants, mais nous ne la mettons plus à jour. Pour plus d'informations, consultez Qu'est-ce qu'Amazon Machine Learning ?
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Fractionnement des données
L'objectif fondamental d'un modèle d'apprentissage-machine est d'effectuer des prédictions précises sur des instances de données futures au-delà de celles utilisées pour former les modèles. Avant d'utiliser un modèle d'apprentissage-machine pour effectuer des prédictions, nous devons évaluer les performances prédictives du modèle. Pour estimer la qualité des prédictions d'un modèle d'apprentissage-machine avec des données qu'il ne connaît pas, nous pouvons réserver, ou fractionner, une partie des données pour lesquelles nous connaissons déjà la réponse comme indicateur pour les données futures, et évaluer la qualité avec laquelle le modèle d'apprentissage-machine prédit les réponses correctes pour ces données. Vous fractionnez la source de données de manière à obtenir une partie pour la source de données de formation et une partie pour la source de données d'évaluation.
Amazon ML propose trois options pour fractionner vos données :
-
Pre-split les données - Vous pouvez diviser les données en deux emplacements de saisie, avant de les télécharger sur Amazon Simple Storage Service (Amazon S3) et de créer deux sources de données distinctes avec elles.
-
Fractionnement séquentiel Amazon ML : vous pouvez demander à Amazon ML de diviser vos données de manière séquentielle lors de la création des sources de données de formation et d'évaluation.
-
Fractionnement aléatoire Amazon ML : vous pouvez demander à Amazon ML de fractionner vos données à l'aide d'une méthode aléatoire prédéfinie lors de la création des sources de données de formation et d'évaluation.
Pre-splitting Vos données
Si vous souhaitez un contrôle explicite des données dans vos sources de données de formation et d'évaluation, fractionnez les données en emplacements de données séparés et créez des sources de données distinctes pour les emplacements d'entrée et d'évaluation.
Fractionnement séquentiel des données
Un moyen simple de fractionner vos données d'entrée pour la formation et l'évaluation consiste à sélectionner des sous-ensembles sans chevauchement de vos données tout en conservant l'ordre des enregistrements de données. Cette approche est utile si vous souhaitez évaluer vos modèles d'apprentissage-machine sur les données pour une date donnée ou au sein d'une période donnée. Par exemple, imaginons que vous disposez des données d'engagement client des cinq derniers mois et que vous souhaitez utiliser ces données historiques pour prédire l'engagement des clients au mois suivant. L'utilisation du début de la période pour la formation et des données de la fin de la période pour l'évaluation peut générer une estimation plus précise de la qualité du modèle que l'utilisation des données d'enregistrement extraites de la plage de données complète.
La figure suivante montre des exemples illustrant quand vous devez utiliser une stratégie de fractionnement séquentiel et quand vous devez utiliser une stratégie aléatoire.
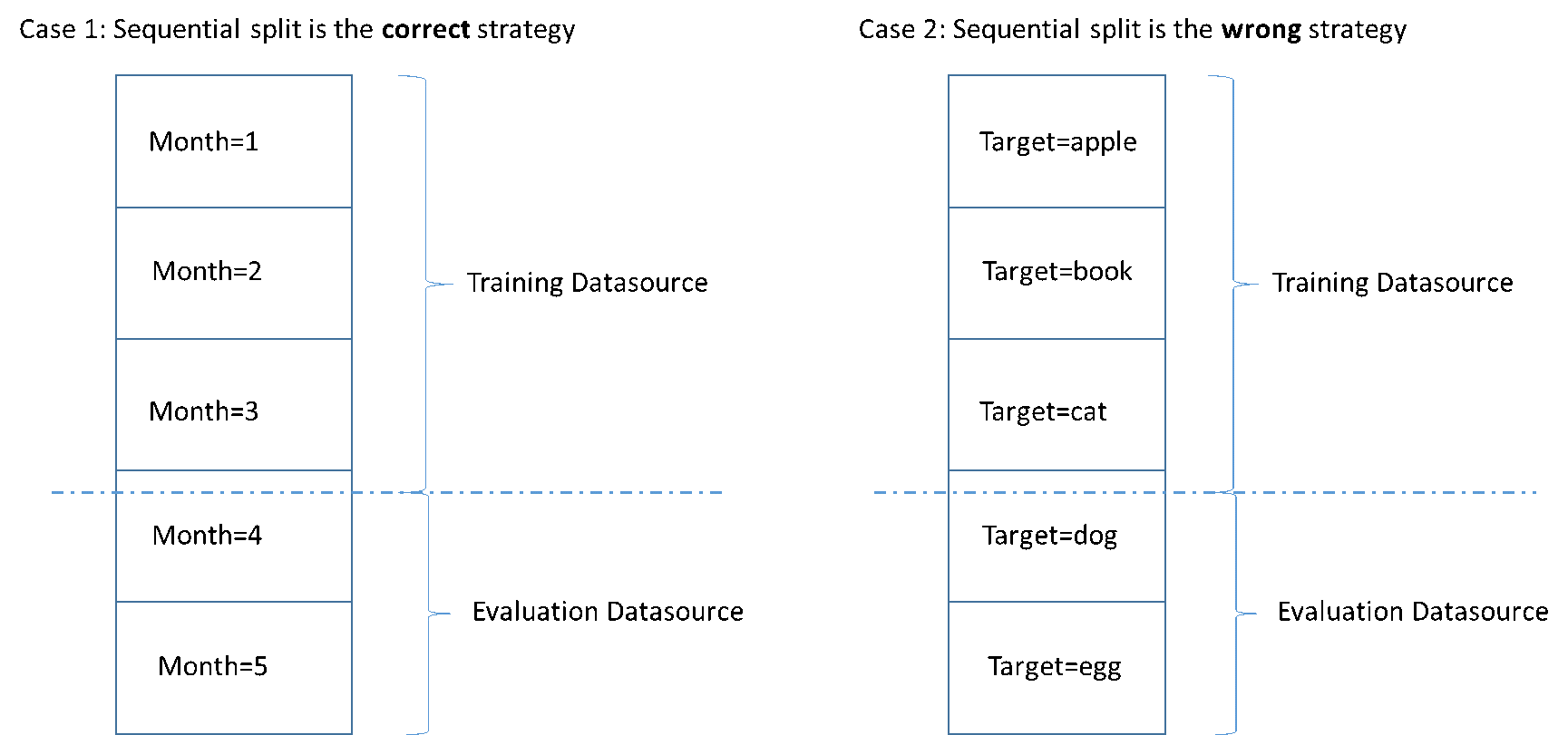
Lorsque vous créez une source de données, vous pouvez choisir de la diviser de manière séquentielle, et Amazon ML utilise les premiers 70 % de vos données pour la formation et les 30 % restants pour l'évaluation. Il s'agit de l'approche par défaut lorsque vous utilisez la console Amazon ML pour diviser vos données.
Fractionnement aléatoire des données
Le fractionnement aléatoire des données d'entrée dans les sources de données de formation et d'évaluation garantit une distribution des données similaire dans les sources de données de formation et d'évaluation. Choisissez cette option lorsque vous n'avez pas besoin de préserver l'ordre de vos données d'entrée.
Amazon ML utilise une méthode de génération de nombres pseudo-aléatoires prédéfinis pour diviser vos données. La valeur initiale est basée en partie sur une valeur de chaîne en entrée et en partie sur le contenu des données lui-même. Par défaut, la console Amazon ML utilise l'emplacement S3 des données d'entrée comme chaîne. Les utilisateurs d'API peuvent fournir une chaîne personnalisée. Cela signifie qu'avec le même compartiment S3 et les mêmes données, Amazon ML divise les données de la même manière à chaque fois. Pour modifier la façon dont Amazon ML divise les données, vous pouvez utiliser l'CreateDatasourceFromRDSAPI CreateDatasourceFromS3CreateDatasourceFromRedshift, ou et fournir une valeur pour la chaîne de départ. Lorsque vous utilisez ces API pour créer des sources de données distinctes pour la formation et l'évaluation, il est important d'utiliser la même valeur de chaîne d'amorçage pour les deux sources de données et l'indicateur de complément pour l'une des sources de données. Cela garantit l'absence de chevauchement entre les données de formation et d'évaluation.
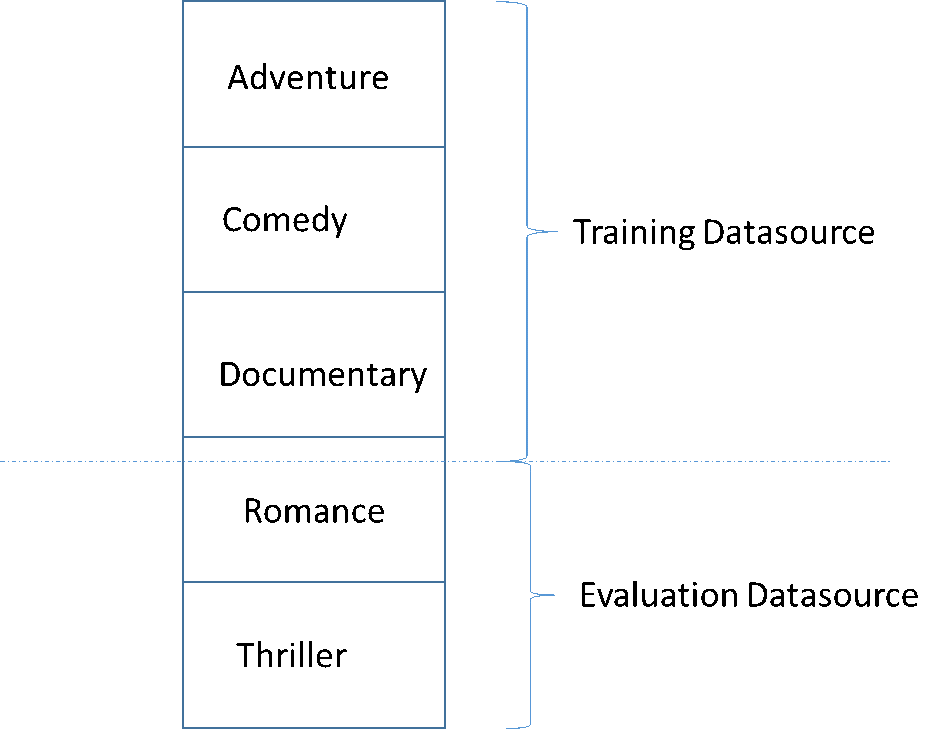
Lors du développement d'un modèle d'apprentissage-machine de haute qualité, un piège courant consiste à évaluer le modèle d'apprentissage-machine sur des données qui ne sont pas similaires à celles utilisées pour la formation. Par exemple, imaginons que vous utilisez l'apprentissage-machine pour prédire le genre de films et que vos données de formation contiennent des films des genres Aventure, Comédie et Documentaire. Toutefois, vos données d'évaluation contiennent uniquement des données des genres Film romantique et Thriller. Dans ce cas, le modèle d'apprentissage-machine n'a appris aucune information sur les genres Film romantique et Thriller, et l'évaluation n'a pas évalué la manière dont le modèle a appris les tendances pour les genres Aventure, Comédie et Documentaire. En conséquence, les informations de genre sont inutiles et la qualité des prédictions du modèle d'apprentissage-machine est compromise pour tous les genres. Le modèle et l'évaluation sont trop dissemblables (ont des statistiques descriptives extrêmement différentes) pour être utiles. Cela peut se produire lorsque les données d'entrée sont triées selon l'une des colonnes du jeu de données, puis fractionnées de manière séquentielle.
Si vos sources de données de formation et d'évaluation ont des distributions de données différentes, vous voyez une alerte d'évaluation dans votre évaluation de modèle. Pour plus d'informations sur les alertes d'évaluation, consultez Alertes d'évaluation.
Il n'est pas nécessaire d'utiliser le découpage aléatoire dans Amazon ML si vous avez déjà randomisé vos données d'entrée, par exemple en les mélangeant de manière aléatoire dans Amazon S3 ou en utilisant une fonction de requête SQL Amazon Redshift random() ou une fonction de requête SQL MySQL lors de la création des sources de rand() données. Dans ces cas, vous pouvez vous appuyer sur l'option de fractionnement séquentiel pour créer des sources de données de formation et d'évaluation avec des distributions similaires.
