Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Caractéristiques et limites de la recherche vectorielle
Disponibilité de la recherche vectorielle
La configuration MemoryDB activée par la recherche vectorielle est prise en charge sur les types de nœuds R6g, R7g et T4g et est disponible dans toutes les régions où MemoryDB est disponible. AWS
Les clusters existants ne peuvent pas être modifiés pour permettre la recherche. Toutefois, les clusters activés pour la recherche peuvent être créés à partir de clichés de clusters dont la recherche est désactivée.
Restrictions paramétriques
Le tableau suivant indique les limites applicables aux différents éléments de recherche vectorielle :
| Élément | Valeur maximale |
|---|---|
| Nombre de dimensions dans un vecteur | 32768 |
| Nombre d'index pouvant être créés | 10 |
| Nombre de champs dans un index | 50 |
| Clause FT.SEARCH et FT.AGGREGATE TIMEOUT (millisecondes) | 10 000 |
| Nombre d'étapes du pipeline dans la commande FT.AGGREGATE | 32 |
| Nombre de champs dans la clause FT.AGGREGATE LOAD | 1 024 |
| Nombre de champs dans la clause FT.AGGREGATE GROUPBY | 16 |
| Nombre de champs dans la clause FT.AGGREGATE SORTBY | 16 |
| Nombre de paramètres dans la clause FT.AGGREGATE PARAM | 32 |
| Paramètre HNSW M | 512 |
| Paramètre HNSW EF_CONSTRUCTION | 4096 |
| Paramètre HNSW EF_RUNTIME | 4096 |
Limites d'échelle
La recherche vectorielle pour MemoryDB est actuellement limitée à une seule partition et la mise à l'échelle horizontale n'est pas prise en charge. La recherche vectorielle prend en charge le dimensionnement vertical et le dimensionnement des répliques.
Restrictions opérationnelles
Persistance de l'indice et remblayage
La fonction de recherche vectorielle conserve la définition des index et le contenu de l'index. Cela signifie que lors de toute demande ou événement opérationnel entraînant le démarrage ou le redémarrage d'un nœud, la définition et le contenu de l'index sont restaurés à partir du dernier instantané et toutes les transactions en attente sont lues dans le journal des transactions multi-AZ. Aucune action de l'utilisateur n'est requise pour lancer cette opération. La reconstruction est effectuée sous forme d'opération de remblayage dès que les données sont restaurées. Cela équivaut fonctionnellement à l'exécution automatique par le système d'une commande FT.CREATE pour chaque index défini. Notez que le nœud devient disponible pour les opérations des applications dès que les données sont restaurées, mais probablement avant la fin du remplissage des index, ce qui signifie que les remplissages redeviendront visibles pour les applications. Par exemple, les commandes de recherche utilisant des index de remblayage peuvent être rejetées. Pour plus d'informations sur le remblayage, voirAperçu de la recherche vectorielle.
L'achèvement du remplissage de l'index n'est pas synchronisé entre un index principal et un réplica. Ce manque de synchronisation peut devenir visible de manière inattendue pour les applications. Il est donc recommandé aux applications de vérifier que le remblayage est terminé sur les primaires et sur toutes les répliques avant de lancer des opérations de recherche.
Instantané import/export et migration en direct
La présence d'index de recherche dans un fichier RDB limite la transportabilité compatible de ces données. Le format des index vectoriels défini par la fonctionnalité de recherche vectorielle de MemoryDB n'est compris que par un autre cluster activé par les vecteurs de MemoryDB. De plus, les fichiers RDB des clusters de prévisualisation peuvent être importés par la version GA des clusters MemoryDB, qui reconstruira le contenu de l'index lors du chargement du fichier RDB.
Toutefois, les fichiers RDB qui ne contiennent pas d'index ne sont pas restreints de cette manière. Ainsi, les données d'un cluster de prévisualisation peuvent être exportées vers des clusters non prévisualisés en supprimant les index avant l'exportation.
Consommation de mémoire
La consommation de mémoire est basée sur le nombre de vecteurs, le nombre de dimensions, la valeur M et la quantité de données non vectorielles, telles que les métadonnées associées au vecteur ou d'autres données stockées dans l'instance.
La mémoire totale requise est une combinaison de l'espace nécessaire pour les données vectorielles réelles et de l'espace requis pour les indices vectoriels. L'espace requis pour les données vectorielles est calculé en mesurant la capacité réelle requise pour stocker les vecteurs dans les structures de données HASH ou JSON et le surdébit jusqu'aux tranches de mémoire les plus proches, pour des allocations de mémoire optimales. Chacun des index vectoriels utilise des références aux données vectorielles stockées dans ces structures de données et utilise des optimisations de mémoire efficaces pour supprimer toute copie dupliquée des données vectorielles dans l'index.
Le nombre de vecteurs dépend de la façon dont vous décidez de représenter vos données sous forme de vecteurs. Par exemple, vous pouvez choisir de représenter un seul document en plusieurs parties, chaque partie représentant un vecteur. Vous pouvez également choisir de représenter l'ensemble du document sous la forme d'un vecteur unique.
Le nombre de dimensions de vos vecteurs dépend du modèle d'intégration que vous choisissez. Par exemple, si vous choisissez d'utiliser le modèle d'intégration AWS Titan
Le paramètre M représente le nombre de liens bidirectionnels créés pour chaque nouvel élément lors de la construction de l'index. MemoryDB définit cette valeur par défaut sur 16 ; vous pouvez toutefois la remplacer. Un paramètre M élevé fonctionne mieux pour des exigences de rappel and/or élevées en dimensionnalité, tandis que des paramètres M faibles fonctionnent mieux pour des exigences de rappel and/or faibles en dimensionnalité. La valeur M augmente la consommation de mémoire à mesure que l'indice augmente, ce qui augmente la consommation de mémoire.
Dans le cadre de l'expérience console, MemoryDB permet de choisir facilement le type d'instance approprié en fonction des caractéristiques de votre charge de travail vectorielle après avoir coché la case Activer la recherche vectorielle dans les paramètres du cluster.
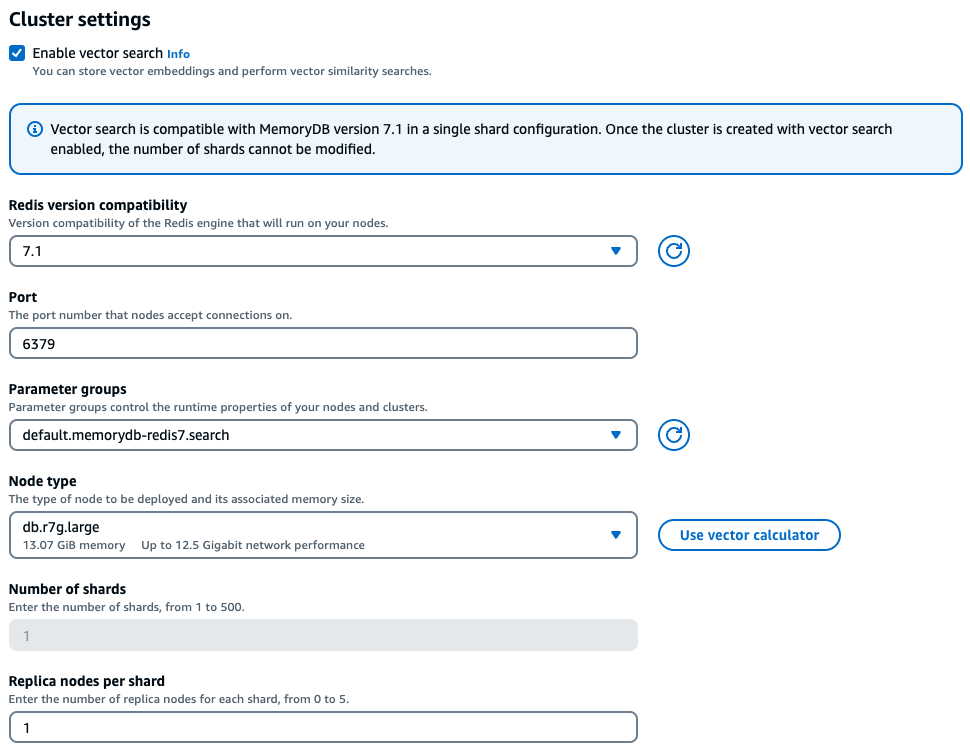
Exemple de charge de travail
Un client souhaite créer un moteur de recherche sémantique basé sur ses documents financiers internes. Ils détiennent actuellement 1 million de documents financiers qui sont découpés en 10 vecteurs par document à l'aide du modèle d'intégration Titan de 1536 dimensions et ne contiennent aucune donnée non vectorielle. Le client décide d'utiliser la valeur par défaut de 16 comme paramètre M.
Vecteurs : 1 M* 10 morceaux = 10 millions de vecteurs
Dimensioni : 1536
Données non vectorielles (Go) : 0 Go
Paramètre M : 16
Avec ces données, le client peut cliquer sur le bouton Utiliser un calculateur vectoriel dans la console pour obtenir un type d'instance recommandé en fonction de ses paramètres :
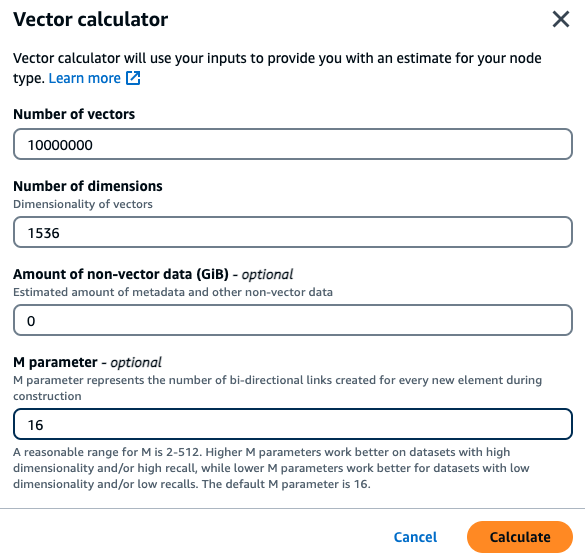

Dans cet exemple, le calculateur vectoriel recherchera le plus petit type de nœud MemoryDB r7g
Sur la base de la méthode de calcul ci-dessus et des paramètres de l'échantillon de charge de travail, ces données vectorielles nécessiteraient 104,9 Go pour stocker les données et un index unique. Dans ce cas, le type d'db.r7g.4xlargeinstance est recommandé car il dispose de 105,81 Go de mémoire utilisable. Le type de nœud le plus petit suivant serait trop petit pour supporter la charge de travail vectorielle.
Comme chacun des index vectoriels utilise des références aux données vectorielles stockées et ne crée pas de copies supplémentaires des données vectorielles dans l'index vectoriel, les index consommeront également relativement moins d'espace. Cela est très utile pour créer plusieurs index, ainsi que dans les situations où des parties des données vectorielles ont été supprimées et où la reconstruction du graphe HNSW permettrait de créer des connexions de nœuds optimales pour des résultats de recherche vectorielle de haute qualité.
Mémoire insuffisante pendant le remblayage
À l'instar des opérations d'écriture de Valkey et Redis OSS, le remplissage d'index est soumis à des limitations. out-of-memory Si la mémoire du moteur est pleine alors qu'un remblayage est en cours, tous les remplissages sont interrompus. Si de la mémoire devient disponible, le processus de remblayage est repris. Il est également possible de supprimer et d'indexer lorsque le remblayage est suspendu en raison d'un manque de mémoire.
Transactions
Les commandesFT.CREATE,FT.DROPINDEX, FT.ALIASADDFT.ALIASDEL, et FT.ALIASUPDATE ne peuvent pas être exécutées dans un contexte transactionnel, c'est-à-dire pas dans un MULTI/EXEC bloc ou dans un script LUA ou FUNCTION.
