Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Réglage des requêtes Gremlin à l'aide d'explain et de profile
Vous pouvez souvent ajuster vos requêtes Gremlin dans Amazon Neptune pour obtenir de meilleures performances, en utilisant les informations mises à votre disposition dans les rapports fournis par le biais de l'explication et du profil de Neptune. APIs Pour ce faire, il est utile de comprendre comment Neptune traite les traversées Gremlin.
Important
Une modification a été apportée à TinkerPop la version 3.4.11 qui améliore l'exactitude du traitement des requêtes, mais qui, pour le moment, peut parfois avoir un impact sérieux sur les performances des requêtes.
Par exemple, une requête de ce type peut être beaucoup plus lente :
g.V().hasLabel('airport'). order(). by(out().count(),desc). limit(10). out()
Les sommets après le pas de limite sont désormais récupérés de manière non optimale en raison de la modification 3.4.11. TinkerPop Pour éviter cela, vous pouvez modifier la requête en ajoutant l'étape barrier() à tout moment après order().by(). Par exemple :
g.V().hasLabel('airport'). order(). by(out().count(),desc). limit(10). barrier(). out()
TinkerPop La version 3.4.11 a été activée dans la version 1.0.5.0 du moteur Neptune.
Comprendre le traitement des traversées Gremlin dans Neptune
Lorsqu'une traversée Gremlin est envoyée à Neptune, trois processus principaux la convertissent en un plan d'exécution sous-jacent à exécuter par le moteur. Il s'agit de l'analyse, de la conversion et de l'optimisation :
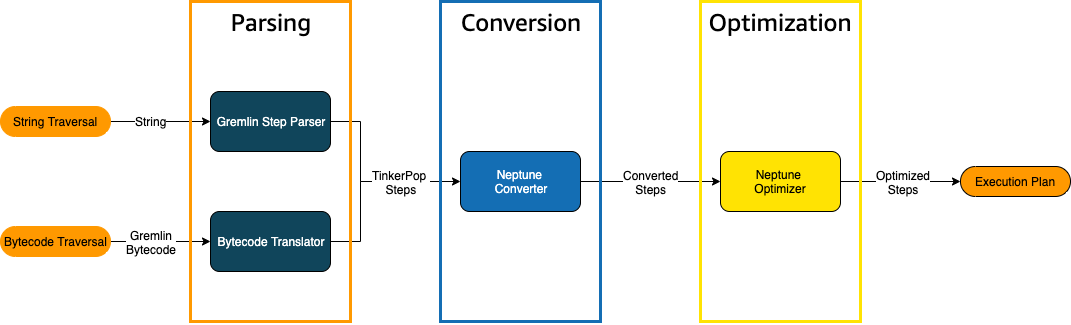
Processus d'analyse des traversées
La première étape du traitement d'une traversée consiste à l'analyser dans un langage commun. Dans Neptune, ce langage commun est l'ensemble des TinkerPop étapes qui font partie de l'TinkerPopAPI.
Vous pouvez envoyer une traversée Gremlin à Neptune sous forme de chaîne ou de bytecode. Le point de terminaison REST et la méthode submit() du pilote client Java envoient des traversées sous forme de chaînes, comme dans cet exemple :
client.submit("g.V()")
Les applications et les pilotes de langage utilisant les variantes du langage Gremlin (GLV)
Processus de conversion des traversées
La deuxième étape du traitement d'une traversée consiste à convertir ses TinkerPop étapes en un ensemble d'étapes Neptune converties et non converties. La plupart des étapes du langage de requête TinkerPop Apache Gkremlin sont converties en étapes spécifiques à Neptune optimisées pour s'exécuter sur le moteur Neptune sous-jacent. Lorsqu'une TinkerPop étape sans équivalent Neptune est rencontrée dans une traversée, cette étape et toutes les étapes suivantes de la traversée sont traitées par le moteur de requête. TinkerPop
Pour plus d'informations sur les étapes qui peuvent être converties et dans quelles circonstances, consultez Prise en charge des étapes Gremlin.
Processus d'optimisation des traversées
La dernière étape du traitement des traversées consiste à exécuter la série d'étapes converties et non converties via l'optimiseur, afin de déterminer le meilleur plan d'exécution. Le résultat de cette optimisation est le plan d'exécution traité par le moteur Neptune.
Utilisation de l'API Neptune Gremlin explain pour ajuster les requêtes
L'API Neptune explain n'est pas identique à l'étape Gremlin explain(). Elle renvoie le plan d'exécution final que le moteur Neptune peut traiter lors de l'exécution de la requête. Comme elle n'effectue aucun traitement, elle renvoie le même plan quels que soient les paramètres utilisés, et sa sortie ne contient aucune statistique sur l'exécution réelle.
Prenons l'exemple de la traversée simple suivante qui permet de trouver tous les sommets de l'aéroport pour Anchorage :
g.V().has('code','ANC')
Il existe deux façons d'exécuter cette traversée via l'API Neptune explain. La première méthode consiste à effectuer un appel REST au point de terminaison explain, comme suit :
curl -X POST https://your-neptune-endpoint:port/gremlin/explain -d '{"gremlin":"g.V().has('code','ANC')"}'
La deuxième méthode consiste à utiliser la magie cellulaire %%gremlin du workbench Neptune avec le paramètre explain. Cela transmet le parcours contenu dans le corps de la cellule à l'API Neptune explain, puis affiche le résultat obtenu lorsque vous exécutez la cellule :
%%gremlin explain g.V().has('code','ANC')
La sortie d'API explain qui en résulte décrit le plan d'exécution de Neptune pour la traversée. Comme vous pouvez le voir sur l'image ci-dessous, le plan inclut chacune des trois étapes du pipeline de traitement :

Réglage d'une traversée en examinant les étapes qui ne sont pas converties
L'une des premières choses à rechercher dans la sortie de l'API Neptune explain concerne les étapes Gremlin qui ne sont pas converties en étapes natives Neptune. Dans un plan de requête, lorsqu'une étape ne peut pas être convertie en étape native Neptune, elle est traitée par le serveur Gremlin, ainsi que toutes les étapes suivantes du plan.
Dans l'exemple ci-dessus, toutes les étapes de la traversée ont été converties. Examinons la sortie d'API explain pour cette traversée :
g.V().has('code','ANC').out().choose(hasLabel('airport'), values('code'), constant('Not an airport'))
Comme vous pouvez le voir sur l'image ci-dessous, Neptune n'a pas pu convertir l'étape choose() :

Il existe plusieurs façons d'ajuster les performances de la traversée. La première consiste à la réécrire de manière à éliminer l'étape qui n'a pas pu être convertie. Une autre solution consiste à déplacer l'étape vers la fin de la traversée afin que toutes les autres étapes puissent être converties en étapes natives.
Un plan de requête dont les étapes ne sont pas converties n'a pas toujours besoin d'être ajusté. Si les étapes qui ne peuvent pas être converties se situent à la fin de la traversée et sont liées à la mise en forme de la sortie plutôt qu'à la manière dont le graphe est parcouru, elles peuvent avoir peu d'effet sur les performances.
Lorsque vous examinez la sortie de l'API Neptune explain, tenez aussi compte des étapes qui n'utilisent pas d'index. La traversée suivante permet de trouver tous les aéroports dont les vols atterrissent à Anchorage :
g.V().has('code','ANC').in().values('code')
La sortie de l'API explain pour cette traversée est la suivante :
******************************************************* Neptune Gremlin Explain ******************************************************* Query String ============ g.V().has('code','ANC').in().values('code') Original Traversal ================== [GraphStep(vertex,[]), HasStep([code.eq(ANC)]), VertexStep(IN,vertex), PropertiesStep([code],value)] Converted Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <~label>, ?2, <~>) . project distinct ?1 .] PatternNode[(?1, <code>, "ANC", ?) . project ask .] PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .] PatternNode[(?3, <~label>, ?4, <~>) . project ask .] PatternNode[(?3, ?7, ?8, <~>) . project ?3,?8 . ContainsFilter(?7 in (<code>)) .] }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Optimized Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <code>, "ANC", ?) . project ?1 .], {estimatedCardinality=1} PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .], {estimatedCardinality=INFINITY} PatternNode[(?3, ?7=<code>, ?8, <~>) . project ?3,?8 .], {estimatedCardinality=7564} }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Predicates ========== # of predicates: 26 WARNING: reverse traversal with no edge label(s) - .in() / .both() may impact query performance
Le message WARNING au bas de la sortie apparaît parce que l'étape in() de la traversée ne peut pas être gérée à l'aide de l'un des trois index gérés par Neptune (voir Comment les instructions sont indexées dans Neptune et Déclarations Gremlin dans Neptune). Comme l'étape in() ne contient aucun filtre d'arête, elle ne peut pas être résolue à l'aide de l'index SPOG, POGS ou GPSO. À la place, Neptune doit effectuer une analyse d'union pour trouver les sommets demandés, ce qui est beaucoup moins efficace.
Dans cette situation, vous pouvez ajuster la traversée de deux façons. La première consiste à ajouter un ou plusieurs critères de filtrage à l'étape in() afin qu'une recherche indexée puisse être utilisée pour résoudre la requête. Concernant l'exemple ci-dessus, cela peut être :
g.V().has('code','ANC').in('route').values('code')
La sortie de l'API Neptune explain pour la traversée révisée ne contient plus le message WARNING :
******************************************************* Neptune Gremlin Explain ******************************************************* Query String ============ g.V().has('code','ANC').in('route').values('code') Original Traversal ================== [GraphStep(vertex,[]), HasStep([code.eq(ANC)]), VertexStep(IN,[route],vertex), PropertiesStep([code],value)] Converted Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <~label>, ?2, <~>) . project distinct ?1 .] PatternNode[(?1, <code>, "ANC", ?) . project ask .] PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) . ContainsFilter(?5 in (<route>)) .] PatternNode[(?3, <~label>, ?4, <~>) . project ask .] PatternNode[(?3, ?7, ?8, <~>) . project ?3,?8 . ContainsFilter(?7 in (<code>)) .] }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Optimized Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <code>, "ANC", ?) . project ?1 .], {estimatedCardinality=1} PatternNode[(?3, ?5=<route>, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .], {estimatedCardinality=32042} PatternNode[(?3, ?7=<code>, ?8, <~>) . project ?3,?8 .], {estimatedCardinality=7564} }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Predicates ========== # of predicates: 26
Si vous exécutez de nombreuses traversées de ce type, vous pouvez également les exécuter dans un cluster de bases de données Neptune dont l'index OSGP facultatif est activé (voir Activation d'un index OSGP). L'activation d'un index OSGP présente des inconvénients :
Elle doit être activée dans un cluster de bases de données avant tout chargement de données.
Les taux d'insertion des sommets et des arêtes peuvent ralentir de jusqu'à 23 %.
L'utilisation du stockage augmente d'environ 20 %.
Les requêtes de lecture qui répartissent les demandes sur tous les index peuvent accroître les temps de latence.
L'utilisation d'un index OSGP est tout à fait justifiée pour un ensemble restreint de modèles de requêtes, mais à moins que vous ne les exécutiez fréquemment, il est généralement préférable de faire en sorte que les traversées que vous écrivez puissent être résolues à l'aide des trois index principaux.
Utilisation d'un grand nombre de prédicats
Neptune traite chaque étiquette d'arête et chaque nom de propriété de sommet ou d'arête distinct dans le graphe comme un prédicat. Il est conçu par défaut pour fonctionner avec un nombre relativement faible de prédicats distincts. Lorsque les données du graphe contiennent plus de quelques milliers de prédicats, les performances peuvent se dégrader.
La sortie Neptune explain vous en avertit si c'est le cas :
Predicates ========== # of predicates: 9549 WARNING: high predicate count (# of distinct property names and edge labels)
S'il n'est pas pratique de retravailler votre modèle de données pour réduire le nombre d'étiquettes et de propriétés, et donc le nombre de prédicats, le meilleur moyen d'ajuster les traversées consiste à les exécuter dans un cluster de bases de données dont l'index OSGP est activé, comme indiqué ci-dessus.
Utilisation de l'API Neptune Gremlin profile pour ajuster les traversées
L'API Neptune profile est très différente de l'étape Gremlin profile(). Comme l'API explain, sa sortie inclut le plan de requête que le moteur Neptune utilisera lors de l'exécution de la traversée. En outre, la sortie profile inclut les statistiques d'exécution réelles de la traversée, compte tenu de la façon dont ses paramètres sont définis.
Là aussi, prenons l'exemple de la traversée simple qui permet de trouver tous les sommets de l'aéroport pour Anchorage :
g.V().has('code','ANC')
Comme avec l'API explain, vous pouvez invoquer l'API profile à l'aide d'un appel REST :
curl -X POST https://your-neptune-endpoint:port/gremlin/profile -d '{"gremlin":"g.V().has('code','ANC')"}'
Utilisez également la magie cellulaire %%gremlin du workbench Neptune avec le paramètre profile. Cela transmet le parcours contenu dans le corps de la cellule à l'API Neptune profile, puis affiche le résultat obtenu lorsque vous exécutez la cellule :
%%gremlin profile g.V().has('code','ANC')
La sortie d'API profile qui en résulte contient à la fois le plan d'exécution de Neptune pour la traversée et les statistiques relatives à l'exécution du plan, comme vous pouvez le voir sur cette image :

Dans la sortie profile, la section du plan d'exécution contient uniquement le plan d'exécution final de la traversée, et non les étapes intermédiaires. La section du pipeline contient les opérations physiques du pipeline qui ont été effectuées ainsi que le temps réel (en millisecondes) nécessaire à l'exécution de la traversée. La métrique d'exécution est extrêmement utile pour comparer le temps nécessaire à deux versions différentes d'une traversée lorsque vous les optimisez.
Note
La durée d'exécution initiale d'une traversée est généralement plus longue que celle des exécutions suivantes, car la première entraîne la mise en cache des données pertinentes.
La troisième section de la sortie profile contient les statistiques d'exécution et les résultats de la traversée. Pour voir comment ces informations peuvent être utiles pour ajuster une traversée, prenons l'exemple de la traversée suivante, qui permet de trouver tous les aéroports dont le nom commence par « Anchora » et tous les aéroports accessibles en deux étapes à partir de ces aéroports, en renvoyant le code des aéroports, les itinéraires de vol et les distances :
%%gremlin profile g.withSideEffect("Neptune#fts.endpoint", "{your-OpenSearch-endpoint-URL"). V().has("city", "Neptune#fts Anchora~"). repeat(outE('route').inV().simplePath()).times(2). project('Destination', 'Route'). by('code'). by(path().by('code').by('dist'))
Métriques de traversée dans la sortie de l'API Neptune profile
Le premier ensemble de métriques disponible dans toutes les sorties profile est celui des métriques de traversée. Elles sont similaires aux métriques de l'étape Gremlin profile(), à quelques différences près :
Traversal Metrics ================= Step Count Traversers Time (ms) % Dur ------------------------------------------------------------------------------------------------------------- NeptuneGraphQueryStep(Vertex) 3856 3856 91.701 9.09 NeptuneTraverserConverterStep 3856 3856 38.787 3.84 ProjectStep([Destination, Route],[value(code), ... 3856 3856 878.786 87.07 PathStep([value(code), value(dist)]) 3856 3856 601.359 >TOTAL - - 1009.274 -
La première colonne du tableau des métriques de traversée répertorie les étapes exécutées par la traversée. Les deux premières étapes sont généralement les étapes spécifiques à Neptune, NeptuneGraphQueryStep et NeptuneTraverserConverterStep.
NeptuneGraphQueryStep représente le temps d'exécution pour toute la partie de la traversée qui pourrait être convertie et exécutée nativement par le moteur Neptune.
NeptuneTraverserConverterStepreprésente le processus de conversion de la sortie de ces étapes converties en TinkerPop traverseurs qui permettent de traiter les étapes qui n'ont pas pu être converties, le cas échéant, ou de renvoyer les résultats dans un format TinkerPop compatible.
Dans l'exemple ci-dessus, nous avons plusieurs étapes non converties. Nous voyons donc que chacune de ces TinkerPop étapes (ProjectStep,PathStep) apparaît alors sous forme de ligne dans le tableau.
La deuxième colonne du tableau indique le nombre de traversers représentés qui sont passés par l'étape, tandis que la troisième colonne indique le nombre de traverseurs qui sont passés par cette étape, comme expliqué dans la documentation de l'étape du TinkerPop profilCount Traversers
Dans notre exemple, 3 856 sommets et 3 856 traverseurs sont renvoyés par NeptuneGraphQueryStep, et ces nombres restent les mêmes pendant le reste du traitement car ProjectStep et PathStep mettent en forme les résultats, sans les filtrer.
Note
Contrairement à cela TinkerPop, le moteur Neptune n'optimise pas les performances en augmentant le nombre de ses étapes et de ses NeptuneGraphQueryStep étapes. NeptuneTraverserConverterStep Le groupage est l' TinkerPopopération qui combine des traverseurs situés sur le même sommet afin de réduire la surcharge opérationnelle, et c'est ce qui explique la différence entre les Traversers nombres Count et. Comme le groupage ne se produit que par étapes déléguées TinkerPop par Neptune, et non par étapes gérées nativement par Neptune, Count les colonnes et diffèrent rarement. Traverser
La colonne Temps indique le nombre de millisecondes que l'étape a duré, tandis que la colonne % Dur indique le pourcentage du temps de traitement total que l'étape a pris. Ces métriques vous indiquent sur quoi concentrer vos efforts de réglage en présentant les étapes qui ont pris le plus de temps.
Métriques d'opérations d'index dans la sortie de l'API Neptune profile
Les opérations d'indexation constituent un autre ensemble de métriques figurant dans les résultats de l'API de profil Neptune :
Index Operations ================ Query execution: # of statement index ops: 23191 # of unique statement index ops: 5960 Duplication ratio: 3.89 # of terms materialized: 0
Ces métriques fournissent les informatons suivantes :
Nombre total de recherches d'index.
Nombre de recherches d'index uniques effectuées.
Ratio entre le nombre total de recherches d'index et le nombre total de recherches uniques. Un ratio inférieur indique une redondance moindre.
Nombre de termes matérialisés à partir du dictionnaire.
Métriques de répétitions dans la sortie de l'API Neptune profile
Si votre traversée utilise une étape repeat() comme dans l'exemple ci-dessus, une section contenant des métriques de répétition apparaît dans la sortie profile :
Repeat Metrics ============== Iteration Visited Output Until Emit Next ------------------------------------------------------ 0 2 0 0 0 2 1 53 0 0 0 53 2 3856 3856 3856 0 0 ------------------------------------------------------ 3911 3856 3856 0 55
Ces métriques fournissent les informatons suivantes :
Nombre de boucles pour une ligne (colonne
Iteration)Nombre d'éléments auxquels la boucle a accédé (colonne
Visited)Nombre d'éléments générés par la boucle (colonne
Output)Dernier élément généré par la boucle (colonne
Until)Nombre d'éléments émis par la boucle (colonne
Emit)Nombre d'éléments étant passés de la boucle à la boucle suivante (colonne
Next)
Ces métriques de répétition sont très utiles pour comprendre le facteur de ramification de la traversée. Elles vous permettent de vous faire une idée de la quantité de travail effectuée par la base de données. Vous pouvez utiliser ces chiffres pour diagnostiquer les problèmes de performances, en particulier lorsqu'une même traversée fonctionne de manière radicalement différente selon les paramètres.
Métriques de recherche en texte intégral dans la sortie de l'API Neptune profile
Lorsqu'une traversée utilise une recherche en texte intégral, comme dans l'exemple ci-dessus, une section contenant les métriques de recherche en texte intégral (FTS) apparaît dans la sortie profile :
FTS Metrics ============== SearchNode[(idVar=?1, query=Anchora~, field=city) . project ?1 .], {endpoint=your-OpenSearch-endpoint-URL, incomingSolutionsThreshold=1000, estimatedCardinality=INFINITY, remoteCallTimeSummary=[total=65, avg=32.500000, max=37, min=28], remoteCallTime=65, remoteCalls=2, joinTime=0, indexTime=0, remoteResults=2} 2 result(s) produced from SearchNode above
Cela montre la requête envoyée au cluster ElasticSearch (ES) et indique plusieurs mesures relatives à l'interaction avec ElasticSearch lesquelles vous pouvez identifier les problèmes de performances liés à la recherche en texte intégral :
-
Informations récapitulatives sur les appels dans l' ElasticSearch index :
Nombre total de millisecondes requis par tous les appels à distance pour satisfaire la requête (
total).Nombre moyen de millisecondes passées dans un appel à distance (
avg).Nombre minimum de millisecondes passées dans un appel à distance (
min).Nombre maximum de millisecondes passées dans un appel à distance (
max).
Durée totale consommée par RemoteCalls to ElasticSearch ()
remoteCallTime.Le nombre d'appels à distance effectués vers ElasticSearch ()
remoteCalls.Le nombre de millisecondes passées à joindre les ElasticSearch résultats ().
joinTimeNombre de millisecondes passées dans les recherches d'index (
indexTime).Le nombre total de résultats renvoyés par ElasticSearch (
remoteResults).
