Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation d'Amazon Neptune avec une base de données mondiale
Une base de données mondiale Amazon Neptune couvre plusieurs bases de données Régions AWS, ce qui permet des lectures globales à faible latence et une restauration rapide dans les rares cas où une panne affecte l'ensemble d'une base de données. Région AWS
Une base de données Neptune globale se compose d'un cluster de bases de données principal dans une région et de jusqu'à cinq clusters de bases de données secondaires dans différentes régions.
Les écritures ne peuvent avoir lieu que dans la région principale. Les régions secondaires ne prennent en charge que les lectures. Chaque région secondaire peut comporter jusqu'à 16 instances de lecteur.
Bases de données mondiales dans Amazon Neptune
En utilisant une base de données Neptune globale, vous pouvez exécuter vos applications distribuées dans le monde entier à l'aide d'une base de données unique couvrant plusieurs régions Régions AWS.
Une base de données Neptune globale se compose d'un cluster de bases de données principal dans une Région AWS principale et de jusqu'à cinq clusters de bases de données en lecture seule dans des Régions AWS secondaires. Lorsque vous effectuez une opération d'écriture dans le cluster de bases de données principal, Neptune réplique les données écrites dans tous les clusters de bases de données secondaires à l'aide d'une infrastructure dédiée, avec une latence généralement inférieure à une seconde.
Le schéma suivant montre un exemple de base de données globale qui couvre deux Régions AWS bases de données :
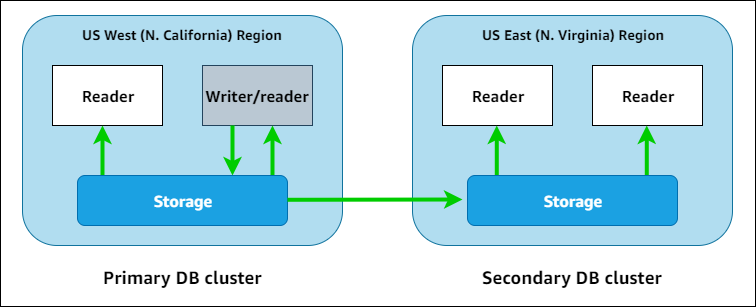
Vous pouvez mettre à l'échelle chaque cluster secondaire indépendamment pour gérer les charges de travail en lecture seule en ajoutant une ou plusieurs instances de réplica en lecture.
Pour effectuer des opérations d'écriture, vous devez vous connecter au point de terminaison du cluster de bases de données principal. Seul le cluster principal peut exécuter les opérations d'écriture. Ensuite, comme le montre le schéma ci-dessus, la réplication est effectuée par le volume de stockage du cluster, et non par le moteur de base de données.
Les bases de données Neptune globales sont conçues pour les applications ayant une empreinte mondiale. Les clusters de bases de données secondaires en lecture seule prennent en charge les opérations de lecture au plus près des utilisateurs de l'application.
Une base de données Neptune globale permet deux approches différentes de basculement.
Pour effectuer une reprise après une panne dans la région principale, utilisez le detach-and-promote processus manuel non planifié, qui consiste à détacher l'un des clusters secondaires, à le transformer en cluster autonome, puis à le promouvoir en tant que nouveau cluster principal.
Pour les procédures opérationnelles planifiées telles que la maintenance, utilisez le basculement planifié géré, dans lequel vous déplacez le cluster principal vers l'une de ses régions secondaires sans perte de données.
Avantages liés à l'utilisation de bases de données globales dans Amazon Neptune
En utilisant une base de données Neptune globale, vous bénéficiez des avantages suivants :
Lectures globales avec latence locale : si vous avez des bureaux répartis dans le monde entier, une base de données globale permet à ceux qui se trouvent dans les régions secondaires d'accéder aux données dans leur propre région avec une latence locale.
Clusters de bases de données Neptune secondaires évolutifs : vous pouvez mettre à l'échelle les clusters secondaires en ajoutant d'autres instances de réplicas en lecture seule. Comme les clusters secondaires sont en lecture seule, ils peuvent chacun prendre en charge jusqu'à 16 réplicas en lecture plutôt que la limite habituelle qui s'élève à 15 réplicas.
Réplication rapide vers les clusters de bases de données secondaires : la réplication des clusters de bases de données principaux vers les clusters secondaires est rapide, avec une latence généralement en dessous d'une seconde et un impact moindre sur les performances du cluster de bases de données principal. La réplication étant effectuée au niveau du stockage, les ressources de l'instance de base de données sont entièrement disponibles pour les charges de travail de lecture et d'écriture des applications.
Restauration après des pannes à l'échelle de la région : les clusters de base de données secondaires vous permettent de déplacer le cluster principal vers une nouvelle région plus rapidement, avec des pertes de données plus faibles RTO (plus faiblesRPO) que les solutions de réplication traditionnelles.
Limitations des bases de données globales Amazon Neptune
Les limitations suivantes s'appliquent actuellement aux bases de données globales :
-
Les bases de données globales Neptune sont disponibles dans les Régions AWS suivantes :
USA Est (Virginie du Nord) :
us-east-1USA Est (Ohio) :
us-east-2USA Ouest (Californie du Nord) :
us-west-1USA Ouest (Oregon) :
us-west-2Europe (Espagne) :
eu-south-2Europe (Irlande) :
eu-west-1Europe (Londres) :
eu-west-2Asie-Pacifique (Tokyo) :
ap-northeast-1
Les bases de données globales Neptune ne prennent pas en charge l'autoscaling pour les clusters de bases de données secondaires.
Vous ne pouvez pas appliquer un groupe de paramètres personnalisés au cluster de bases de données globale pendant que vous effectuez une mise à niveau majeure de la version de cette base de données globale. À la place, créez vos groupes de paramètres personnalisés dans chaque région du cluster global, puis appliquez-les manuellement aux clusters régionaux après la mise à niveau.
Vous ne pouvez pas arrêter ni démarrer les clusters de bases de données dans une base de données globale individuellement.
Les instances de réplication en lecture d'un cluster de base de données secondaire peuvent redémarrer dans certaines circonstances, notamment lors des mises à niveau planifiées pendant votre période de maintenance. Si l'instance d'enregistreur du cluster de bases de données principal redémarre ou bascule, toutes les instances des régions secondaires redémarrent également. Le cluster secondaire n'est pas disponible tant que tous les réplicas ne sont pas de nouveau synchronisés avec l'instance d'enregistreur du cluster de bases de données principal.
