Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Surveillance des métriques OpenSearch du cluster avec Amazon CloudWatch
Amazon OpenSearch Service publie les données de vos domaines sur Amazon CloudWatch. CloudWatch vous permet de récupérer des statistiques sur ces points de données sous la forme d'un ensemble ordonné de séries chronologiques, appelées métriques. OpenSearch Le service envoie la plupart des métriques CloudWatch à des intervalles de 60 secondes. Si vous utilisez des EBS volumes à usage général ou magnétiques, les statistiques de EBS volume ne sont mises à jour que toutes les cinq minutes. Toutes les métriques cumulées (par exempleThreadpoolWriteRejected,ThreadpoolSearchRejected) sont en mémoire et perdront leur état. Les métriques seront réinitialisées lors d'une chute d'un nœud, d'un rebond d'un nœud, d'un remplacement de nœud et d'un déploiement bleu/vert. Pour plus d'informations sur Amazon CloudWatch, consultez le guide de CloudWatch l'utilisateur Amazon.
La console OpenSearch de service affiche une série de graphiques basés sur les données brutes provenant de CloudWatch. Selon vos besoins, vous préférerez peut-être afficher les données du cluster dans la console CloudWatch plutôt que dans les graphiques. Le service archive les métriques pendant deux semaines avant de les supprimer. Les statistiques sont fournies sans frais supplémentaires, mais la création de tableaux de bord et d'alarmes CloudWatch reste facturée. Pour plus d'informations, consultez les CloudWatchtarifs Amazon
OpenSearch Le service publie les métriques suivantes pour CloudWatch :
Afficher les métriques dans CloudWatch
CloudWatch les métriques sont regroupées d'abord en fonction de l'espace de noms du service, puis en fonction des différentes combinaisons de dimensions au sein de chaque espace de noms.
Pour afficher les métriques à l'aide de la CloudWatch console
-
Ouvrez la CloudWatch console à l'adresse https://console.aws.amazon.com/cloudwatch/
. -
Dans le panneau de navigation de gauche, localisez Metrics (Métriques), puis choisissez All metrics (Toutes les métriques). Sélectionnez l'espace de OpenSearchService noms ES/.
-
Choisissez une dimension pour afficher les métriques correspondantes. Les métriques correspondant aux nœuds individuels se trouvent dans la dimension
ClientId, DomainName, NodeId. Les métriques de cluster se trouvent dans la dimensionPer-Domain, Per-Client Metrics. Certaines métriques de nœud sont agrégées au niveau du cluster et sont donc incluses dans les deux dimensions. Les métriques de partition se trouvent dans la dimensionClientId, DomainName, NodeId, ShardRole.
Pour afficher une liste de mesures à l'aide du AWS CLI
Exécutez la commande suivante :
aws cloudwatch list-metrics --namespace "AWS/ES"
Interprétation des cartes de santé en OpenSearch service
Pour consulter les métriques dans OpenSearch Service, utilisez les onglets État du cluster et État de l'instance. L'onglet État de l'instance utilise des diagrammes à cases pour fournir at-a-glance une visibilité sur l'état de santé de chaque OpenSearch nœud :
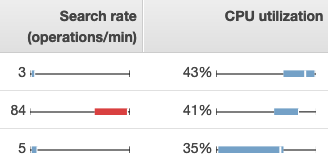
-
Chaque zone colorée indique la plage de valeurs pour le nœud au cours de la période spécifiée.
-
Les zones bleues représentent les valeurs qui sont cohérentes avec les autres nœuds. Les zones rouges représentent des valeurs hors normes.
-
La ligne blanche dans chaque zone représente la valeur actuelle du nœud.
-
Les « moustaches » des deux côtés de chaque zone présentent les valeurs minimale et maximale pour tous les nœuds au cours de la période.
Si vous modifiez la configuration de votre domaine, la liste des instances individuelles qui s'affiche dans les onglets État du cluster et État de l'instance double souvent de taille pour une courte période avant de revenir à sa taille appropriée. Pour obtenir une explication de ce comportement, consultez Modifier la configuration dans Amazon OpenSearch Service.
Métriques du cluster
Amazon OpenSearch Service fournit les métriques suivantes pour les clusters.
| Métrique | Description |
|---|---|
ClusterStatus.green |
Une valeur 1 indique que toutes les partitions d'index sont affectées aux nœuds du cluster. Statistiques pertinentes : Maximum |
ClusterStatus.yellow |
Une valeur 1 indique que les partitions principales pour tous les index sont attribuées aux nœuds d'un cluster, sauf pour les partitions de réplica d'au moins un index. Pour de plus amples informations, veuillez consulter Statut de cluster jaune. Statistiques pertinentes : Maximum |
ClusterStatus.red |
Une valeur 1 indique que les partitions primaires et de réplica d'au moins un index ne sont pas allouées aux nœuds du cluster. Pour de plus amples informations, veuillez consulter Statut de cluster rouge. Statistiques pertinentes : Maximum |
Shards.active |
Nombre total de partitions primaires et de partitions de réplica actives. Statistiques pertinentes : Maximum, Somme |
Shards.unassigned |
Nombre de partitions non allouées aux nœuds du cluster. Statistiques pertinentes : Maximum, Somme |
Shards.delayedUnassigned |
Nombre de partitions dont l'allocation de nœud a été retardée par les paramètres d'expiration. Statistiques pertinentes : Maximum, Somme |
Shards.activePrimary |
Nombre de partitions primaires actives. Statistiques pertinentes : Maximum, Somme |
Shards.initializing |
Nombre de partitions en cours d'initialisation. Statistiques pertinentes : somme |
Shards.relocating |
Nombre de partitions en cours de relocalisation. Statistiques pertinentes : somme |
Nodes |
Le nombre de nœuds du cluster de OpenSearch services, y compris les nœuds maîtres et les UltraWarm nœuds dédiés. Pour de plus amples informations, veuillez consulter Modifier la configuration dans Amazon OpenSearch Service. Statistiques pertinentes : Maximum |
SearchableDocuments |
Nombre total de documents consultables sur tous les nœuds de données du cluster. Statistiques pertinentes : minimum, maximum, moyenne |
DeletedDocuments |
Nombre total de documents marqués pour suppression sur tous les nœuds de données du cluster. Ces documents n'apparaissent plus dans les résultats de recherche, mais OpenSearch suppriment uniquement les documents supprimés du disque lors des fusions de segments. Cette métrique augmente après les demandes de suppression et diminue après les fusions de segments. Statistiques pertinentes : minimum, maximum, moyenne |
CPUUtilization |
Pourcentage d'CPUutilisation des nœuds de données du cluster. La valeur maximale indique le nœud le plus CPU utilisé. La moyenne représente tous les nœuds du cluster. Cette métrique est également disponible pour les nœuds individuels. Statistiques pertinentes : Maximum, Moyenne |
FreeStorageSpace |
Espace libre pour les nœuds de données du cluster. La console OpenSearch de service affiche cette valeur en GiB. La CloudWatch console Amazon l'affiche en MiB. Note
Statistiques pertinentes : Minimum, Maximum, Moyenne, Somme |
ClusterUsedSpace |
Espace total utilisé pour le cluster. Vous devez laisser la période à une minute pour obtenir une valeur précise. La console OpenSearch de service affiche cette valeur en GiB. La CloudWatch console Amazon l'affiche en MiB. Statistiques pertinentes : Minimum, Maximum |
ClusterIndexWritesBlocked |
Indique si votre cluster accepte ou bloque les demandes d'écriture entrantes. Une valeur de 0 signifie que le cluster accepte les demandes. Une valeur de 1 signifie qu'il bloque les demandes. Parmi les facteurs les plus fréquents, on retrouve les suivants : Statistiques pertinentes : Maximum |
JVMMemoryPressure |
Pourcentage maximal du segment de mémoire Java utilisé pour tous les nœuds de données du cluster. OpenSearch Le service utilise la moitié de celle d'une instance RAM pour le tas Java, jusqu'à une taille de tas de 32 GiB. Vous pouvez redimensionner les instances verticalement jusqu'à 64 GiBRAM, puis vous pouvez les redimensionner horizontalement en ajoutant des instances. Consultez CloudWatch Alarmes recommandées pour Amazon OpenSearch Service. Statistiques pertinentes : Maximum NoteLa logique de cette métrique a changé dans le logiciel de service R20220323. Pour plus d'informations, veuillez consulter les notes de mise à jour. |
OldGenJVMMemoryPressure |
Le pourcentage maximum du tas Java utilisé pour l'« ancienne génération » sur tous les nœuds de données dans le cluster. Cette métrique est également disponible au niveau du nœud. Statistiques pertinentes : Maximum |
AutomatedSnapshotFailure |
Nombre d'instantanés automatiques en échec pour le cluster. Une valeur de Statistiques pertinentes : Minimum, Maximum |
CPUCreditBalance |
Les CPU crédits restants disponibles pour les nœuds de données du cluster. Un CPU crédit fournit la performance d'un CPU noyau complet pendant une minute. Pour plus d'informations, consultez les CPUcrédits dans le manuel Amazon EC2 Developer Guide. Cette métrique est disponible uniquement pour les types d'instance T2. Statistiques pertinentes : Minimum |
OpenSearchDashboardsHealthyNodes |
Un bilan de santé pour les OpenSearch tableaux de bord. Si les statistiques minimales, maximales et moyennes sont toutes égales à 1, les Tableaux de bord se comporteront normalement. Si vous avez 10 nœuds avec un maximum de 1, un minimum de 0 et une moyenne de 0,7, cela signifie que 7 nœuds (70 %) sont sains et 3 nœuds (30%) sont non sains. Statistiques pertinentes : minimum, maximum, moyenne |
OpensearchDashboardsReportingFailedRequestSysErrCount |
Nombre de demandes de génération de rapports de tableau de OpenSearch bord qui ont échoué en raison de problèmes de serveur ou de limitations de fonctionnalités. Statistiques pertinentes : somme |
OpensearchDashboardsReportingFailedRequestUserErrCount |
Le nombre de demandes de génération de rapports de tableau de OpenSearch bord qui ont échoué en raison de problèmes avec le client. Statistiques pertinentes : somme |
OpensearchDashboardsReportingRequestCount |
Le nombre total de demandes pour générer des rapports de OpenSearch tableau de bord. Statistiques pertinentes : somme |
OpensearchDashboardsReportingSuccessCount |
Le nombre de demandes réussies pour générer des rapports de OpenSearch tableau de bord. Statistiques pertinentes : somme |
KMSKeyError |
La valeur 1 indique que la AWS KMS clé utilisée pour chiffrer les données au repos a été désactivée. Pour revenir à un fonctionnement normal du domaine, réactivez la clé. La console n'affiche cette métrique que pour les domaines qui chiffrent les données au repos. Statistiques pertinentes : Minimum, Maximum |
KMSKeyInaccessible |
Une valeur de 1 indique que la AWS KMS clé utilisée pour chiffrer les données au repos a été supprimée ou que son octroi au Service a été révoqué. OpenSearch Vous ne pouvez pas récupérer des domaines qui sont à cet état. Par contre, si vous disposez d'un instantané manuel, vous pouvez l'utiliser pour migrer les données du domaine vers un nouveau domaine. La console n'affiche cette métrique que pour les domaines qui chiffrent les données au repos. Statistiques pertinentes : Minimum, Maximum |
InvalidHostHeaderRequests |
Le nombre de HTTP demandes adressées au OpenSearch cluster qui incluaient un en-tête d'hôte non valide (ou manquant). Les demandes valides incluent le nom d'hôte du domaine comme valeur d'en-tête de l'hôte. OpenSearch Le service rejette les demandes non valides pour les domaines d'accès public qui ne sont pas soumis à une politique d'accès restrictive. Nous recommandons d'appliquer une stratégie d'accès restrictive à tous les domaines. Si vous voyez des valeurs importantes pour cette métrique, vérifiez que vos OpenSearch clients incluent le nom d'hôte du domaine (et non, par exemple, son adresse IP) dans leurs demandes. Statistiques pertinentes : somme |
OpenSearchRequests (previously
ElasticsearchRequests) |
Le nombre de demandes adressées au OpenSearch cluster. Statistiques pertinentes : somme |
2xx, 3xx, 4xx, 5xx |
Le nombre de demandes adressées au domaine qui ont abouti au code de HTTP réponse donné (2 xx, 3 xx, 4 xx, 5 xx). Statistiques pertinentes : somme |
ThroughputThrottle |
Indique si les disques ont été limités ou non. L'étranglement se produit lorsque le débit combiné de Pour plus d'informations sur le débit des instances, consultez Amazon EBS —optimized instances. Pour plus d'informations sur le débit des volumes, consultez la section Types de EBS volumes Amazon Statistiques pertinentes : Minimum, Maximum |
IopsThrottle |
Indique si le nombre d'opérations d'entrée/sortie par seconde (IOPS) sur le domaine a été limité. La limitation se produit lorsque le nœud IOPS de données dépasse la limite maximale autorisée du EBS volume ou de l'EC2instance du nœud de données. Pour plus d'informations sur les instancesIOPS, consultez Amazon EBS —optimized instances. Pour plus d'informations sur le volumeIOPS, consultez la section Types de EBS volumes Amazon Statistiques pertinentes : Minimum, Maximum |
HighSwapUsage |
La valeur 1 indique que l'échange dû à des erreurs de page a potentiellement provoqué des pics d'utilisation du disque sous-jacent au cours d'une période donnée. Statistiques pertinentes : Maximum |
Métriques du nœud principal dédié
Amazon OpenSearch Service fournit les métriques suivantes pour les nœuds maîtres dédiés.
| Métrique | Description |
|---|---|
MasterCPUUtilization |
Pourcentage maximal de CPU ressources utilisées par les nœuds maîtres dédiés. Nous vous recommandons d'augmenter la taille du type d'instance lorsque cette métrique atteint 60 %. Statistiques pertinentes : Maximum |
MasterFreeStorageSpace |
Cette métrique n'est pas pertinente et peut être ignorée. Le service n'utilise pas de nœuds principaux comme nœuds de données. |
MasterJVMMemoryPressure |
Pourcentage maximal du tas Java utilisé pour tous les nœuds maîtres dédiés dans le cluster. Nous vous recommandons de migrer vers un type d'instance plus grand lorsque cette métrique atteint 85 %. Statistiques pertinentes : Maximum NoteLa logique de cette métrique a changé dans le logiciel de service R20220323. Pour plus d'informations, veuillez consulter les notes de mise à jour. |
MasterOldGenJVMMemoryPressure |
Le pourcentage maximum du tas Java utilisé pour l'« ancienne génération » par nœud principal. Statistiques pertinentes : Maximum |
MasterCPUCreditBalance |
Les CPU crédits restants sont disponibles pour les nœuds maîtres dédiés du cluster. Un CPU crédit fournit la performance d'un CPU noyau complet pendant une minute. Pour plus d'informations, consultez les CPUcrédits dans le manuel Amazon EC2 Developer Guide. Cette métrique est disponible uniquement pour les types d'instance T2. Statistiques pertinentes : Minimum |
MasterReachableFromNode |
Vérification de l'état pour les exceptions Les défaillances signifient que le nœud principal est inaccessible depuis le nœud source. Ils sont généralement le résultat d'un problème de connectivité réseau ou d'un problème de AWS dépendance. Statistiques pertinentes : Maximum |
MasterSysMemoryUtilization |
Pourcentage de mémoire du nœud principal actuellement utilisée. Statistiques pertinentes : Maximum |
Métriques des nœuds de coordination dédiés
Amazon OpenSearch Service fournit les métriques suivantes pour les nœuds de coordination dédiés.
| Métrique | Description |
|---|---|
CoordinatorCPUUtilization |
Pourcentage maximal de CPU ressources utilisées par les nœuds de coordination dédiés. Nous recommandons d'augmenter la taille du type d'instance lorsque cette métrique atteint 80 %. Statistiques pertinentes : Maximum |
CoordinatorJVMMemoryPressure |
Pourcentage maximal du segment de mémoire Java utilisé pour tous les nœuds de coordination dédiés du cluster. Nous vous recommandons de migrer vers un type d'instance plus grand lorsque cette métrique atteint 85 %. Statistiques pertinentes : Maximum |
CoordinatorOldGenJVMMemoryPressure |
Le pourcentage maximum du tas Java utilisé pour l'« ancienne génération » par nœud principal. Statistiques pertinentes : Maximum |
CoordinatorSysMemoryUtilization |
Pourcentage de mémoire du nœud coordinateur utilisé. Statistiques pertinentes : Maximum |
CoordinatorFreeStorageSpace |
Cette métrique indique que le service n'utilise pas de nœuds coordinateurs comme nœuds de données. |
EBSmétriques de volume
Amazon OpenSearch Service fournit les mesures suivantes pour les EBS volumes.
| Métrique | Description |
|---|---|
ReadLatency |
Latence, en secondes, pour les opérations de lecture sur les EBS volumes. Cette métrique est également disponible pour les nœuds individuels. Statistiques pertinentes : minimum, maximum, moyenne |
WriteLatency |
Latence, en secondes, pour les opérations d'écriture sur les EBS volumes. Cette métrique est également disponible pour les nœuds individuels. Statistiques pertinentes : minimum, maximum, moyenne |
ReadThroughput |
Débit, en octets par seconde, pour les opérations de lecture sur les EBS volumes. Cette métrique est également disponible pour les nœuds individuels. Statistiques pertinentes : minimum, maximum, moyenne |
ReadThroughputMicroBursting |
Débit, en octets par seconde, pour les opérations de lecture sur des EBS volumes lorsque le microbursting Statistiques pertinentes : minimum, maximum, moyenne |
WriteThroughput |
Débit, en octets par seconde, pour les opérations d'écriture sur des EBS volumes. Cette métrique est également disponible pour les nœuds individuels. Statistiques pertinentes : minimum, maximum, moyenne |
WriteThroughputMicroBursting |
Débit, en octets par seconde, pour les opérations d'écriture sur des EBS volumes lorsque le microbursting Statistiques pertinentes : minimum, maximum, moyenne |
DiskQueueDepth |
Nombre de demandes d'entrée et de sortie (E/S) en attente pour un EBS volume. Statistiques pertinentes : minimum, maximum, moyenne |
ReadIOPS |
Nombre d'opérations d'entrée et de sortie (E/S) par seconde pour les opérations de lecture sur des EBS volumes. Cette métrique est également disponible pour les nœuds individuels. Statistiques pertinentes : minimum, maximum, moyenne |
ReadIOPSMicroBursting |
Nombre d'opérations d'entrée et de sortie (E/S) par seconde pour les opérations de lecture sur des EBS volumes lorsque le microbursting Statistiques pertinentes : minimum, maximum, moyenne |
WriteIOPS |
Nombre d'opérations d'entrée et de sortie (E/S) par seconde pour les opérations d'écriture sur des EBS volumes. Cette métrique est également disponible pour les nœuds individuels. Statistiques pertinentes : minimum, maximum, moyenne |
WriteIOPSMicroBursting |
Nombre d'opérations d'entrée et de sortie (E/S) par seconde pour les opérations d'écriture sur des EBS volumes lorsque le microbursting Statistiques pertinentes : minimum, maximum, moyenne |
BurstBalance |
Pourcentage de crédits d'entrée et de sortie (E/S) restant dans le bucket burst d'un EBS volume. Une valeur de 100 signifie que le volume a accumulé le nombre maximum de crédits. Si ce pourcentage tombe en dessous de 70 %, consultez Solde de débordement EBS faible. Le solde de rafale reste à 0 pour les domaines avec des types de volumes gp3 et les domaines avec des volumes gp2 dont la taille de volume est supérieure à 1 000 Gio. Statistiques pertinentes : minimum, maximum, moyenne |
Métriques des instances
Amazon OpenSearch Service fournit les métriques suivantes pour chaque instance d'un domaine. OpenSearch Le service agrège également ces métriques d'instance pour fournir un aperçu de l'état général du cluster. Vous pouvez vérifier ce comportement à l'aide de la statistique Nombre d'échantillons dans la console. Notez que chaque métrique du tableau suivant inclut des statistiques concernant le nœud et le cluster.
Important
Les différentes versions d'Elasticsearch utilisent différents pools de threads pour traiter les appels au. _index API Elasticsearch 1.5 et 2.3 utilisent le groupe de threads d'index. Elasticsearch 5. x, 6.0 et 6.2 utilisent le pool de threads en masse. OpenSearch et Elasticsearch 6.3 et versions ultérieures utilisent le pool de threads d'écriture. Actuellement, la console OpenSearch de service n'inclut pas de graphique pour le pool de threads en masse.
Utilisez GET _cluster/settings?include_defaults=true pour vérifier la taille du groupe de threads et de la file d'attente de votre cluster.
| Métrique | Description |
|---|---|
ConcurrentSearchRate |
Nombre total de demandes de recherche utilisant une recherche par segment simultanée par minute pour toutes les partitions d'un nœud de données. Un seul appel au Statistiques pertinentes concernant le nœud : Moyenne Statistiques pertinentes concernant le cluster : Moyenne, Maximum, Somme |
ConcurrentSearchLatency |
Différence de temps total, en millisecondes, prise par toutes les recherches utilisant une recherche par segment simultanée dans un nœud entre la minute N et la minute (N-1). Statistiques pertinentes concernant le nœud : Moyenne Statistiques pertinentes concernant le cluster : Moyenne, Maximum |
IndexingLatency |
Différence de temps total, en millisecondes, prise par toutes les opérations d'indexation dans un nœud entre la minute N et la minute (N-1). Statistiques pertinentes concernant le nœud : Moyenne Statistiques pertinentes concernant le cluster : Moyenne, Maximum |
IndexingRate |
Nombre d'opérations d'indexation par minute. Un seul appel au Statistiques pertinentes concernant le nœud : Moyenne Statistiques pertinentes concernant le cluster : Moyenne, Maximum, Somme |
SearchLatency |
Différence de temps total, en millisecondes, prise par toutes les recherches dans un nœud entre la minute N et la minute (N-1). Statistiques pertinentes concernant le nœud : Moyenne Statistiques pertinentes concernant le cluster : Moyenne, Maximum |
SearchRate |
Nombre total de demandes de recherche par minute pour toutes les partitions d'un nœud de données. Un seul appel au Statistiques pertinentes concernant le nœud : Moyenne Statistiques pertinentes concernant le cluster : Moyenne, Maximum, Somme |
SegmentCount |
Nombre de segments sur un nœud de données. Plus vous avez de segments, plus chaque recherche est longue. OpenSearch fusionne parfois des segments plus petits en un plus grand. Statistiques pertinentes concernant le nœud : Maximum, Moyenne Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
SysMemoryUtilization |
Pourcentage de mémoire de l'instance actuellement utilisée. Les valeurs élevées de cette métrique sont normales et ne représentent généralement pas un problème lié à votre cluster. Pour obtenir un meilleur indicateur des éventuels problèmes de performance et de stabilité, veuillez consulter la métrique Statistiques pertinentes concernant le nœud : Minimum, Maximum, Moyenne Statistiques pertinentes concernant le cluster : Minimum, Maximum, Moyenne |
JVMGCYoungCollectionCount |
Nombre de fois que le nettoyage de la « jeune génération » a été exécuté. Un nombre important et évolutif d'exécutions est une part normale des opérations de cluster. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
JVMGCYoungCollectionTime |
Temps, en millisecondes, que le cluster a consacré à l'exécution d'un nettoyage de la « jeune génération ». Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
JVMGCOldCollectionCount |
Nombre de fois que le nettoyage de l'« ancienne génération » a été exécuté. Dans un cluster doté de ressources suffisantes, ce nombre doit rester faible et évoluer peu fréquemment. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
JVMGCOldCollectionTime |
Temps, en millisecondes, que le cluster a consacré à l'exécution d'un nettoyage de l'« ancienne génération ». Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
OpenSearchDashboardsConcurrentConnections |
Le nombre de connexions simultanées actives aux OpenSearch tableaux de bord. Si ce nombre reste élevé, envisagez de mettre votre cluster à l'échelle. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
OpenSearchDashboardsHealthyNode |
Un bilan de santé pour chaque nœud OpenSearch Dashboards. La valeur 1 indique un comportement normal. La valeur 0 indique que les Tableaux de bord sont inaccessibles. Statistiques pertinentes concernant le nœud : Minimum Statistiques pertinentes concernant le cluster : Minimum, Maximum, Moyenne |
OpenSearchDashboardsHeapTotal |
La quantité de mémoire de segment allouée aux OpenSearch tableaux de bord en MiB. Les différents types d'EC2instances peuvent avoir un impact sur l'allocation de mémoire exacte. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
OpenSearchDashboardsHeapUsed |
La quantité absolue de mémoire de segment utilisée par les OpenSearch tableaux de bord en MiB. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
OpenSearchDashboardsHeapUtilization |
Pourcentage maximal de mémoire de segment disponible utilisée par les OpenSearch tableaux de bord. Si cette valeur dépasse 80 %, envisagez de mettre votre cluster à l'échelle. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Minimum, Maximum, Moyenne |
OpenSearchDashboardsOS1MinuteLoad |
CPUCharge moyenne sur une minute pour les OpenSearch tableaux de bord. La CPU charge devrait idéalement rester inférieure à 1,00. Les pics temporaires n'ont rien d'inhabituel, mais nous vous recommandons d'augmenter la taille du type d'instance si cette métrique est systématiquement supérieure à 1,00. Statistiques pertinentes concernant le nœud : Moyenne Statistiques pertinentes concernant le cluster : Moyenne, Maximum |
OpenSearchDashboardsRequestTotal |
Le nombre total de HTTP demandes adressées aux OpenSearch tableaux de bord. Si votre système est lent ou si vous constatez un nombre élevé de demandes des Tableaux de bord, envisagez d'augmenter la taille du type d'instance. Statistiques pertinentes concernant le nœud : Somme Statistiques pertinentes concernant le cluster : Somme |
OpenSearchDashboardsResponseTimesMaxInMillis |
Durée maximale, en millisecondes, nécessaire aux OpenSearch tableaux de bord pour répondre à une demande. Si les demandes mettent systématiquement beaucoup de temps à renvoyer des résultats, envisagez d'augmenter la taille du type d'instance. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Maximum, Moyenne |
SearchTaskCancelled |
Le nombre d'annulations de nœuds coordinateurs. Statistiques pertinentes concernant le nœud : Somme Statistiques pertinentes concernant le cluster : Somme |
SearchShardTaskCancelled |
Le nombre d'annulations de nœuds de données. Statistiques pertinentes concernant le nœud : Somme Statistiques relatives aux clusters pertinentes : somme, |
ThreadpoolForce_mergeQueue |
Nombre de tâches mises en file d'attente dans le groupe de threads de fusion forcée. Si la taille de la file d'attente reste constamment élevée, envisagez de mettre votre cluster à l'échelle. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
ThreadpoolForce_mergeRejected |
Nombre de tâches rejetées dans le groupe de threads de fusion forcée. Si ce nombre augmente constamment, envisagez de mettre votre cluster à l'échelle. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme |
ThreadpoolForce_mergeThreads |
Taille du groupe de threads de fusion forcée. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Moyenne, Somme |
ThreadpoolIndexQueue |
Nombre de tâches mises en file d'attente dans le groupe de threads d'index. Si la taille de la file d'attente reste constamment élevée, envisagez de mettre votre cluster à l'échelle. La taille maximale de la file d'attente d'index est de 200. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
ThreadpoolIndexRejected |
Nombre de tâches rejetées dans le groupe de threads d'index. Si ce nombre augmente constamment, envisagez de mettre votre cluster à l'échelle. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme |
ThreadpoolIndexThreads |
Taille du groupe de threads d'index. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Moyenne, Somme |
ThreadpoolSearchQueue |
Nombre de tâches mises en file d'attente dans le groupe de threads de recherche. Si la taille de la file d'attente reste constamment élevée, envisagez de mettre votre cluster à l'échelle. La taille maximale de la file d'attente de recherche est de 1 000. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
ThreadpoolSearchRejected |
Nombre de tâches rejetées dans le groupe de threads de recherche. Si ce nombre augmente constamment, envisagez de mettre votre cluster à l'échelle. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme |
ThreadpoolSearchThreads |
Taille du groupe de threads de recherche. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Moyenne, Somme |
Threadpoolsql-workerQueue |
Nombre de tâches en file d'attente dans le pool de threads de SQL recherche. Si la taille de la file d'attente reste constamment élevée, envisagez de mettre votre cluster à l'échelle. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
Threadpoolsql-workerRejected |
Le nombre de tâches rejetées dans le pool SQL de fils de recherche. Si ce nombre augmente constamment, envisagez de mettre votre cluster à l'échelle. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme |
Threadpoolsql-workerThreads |
Taille du pool de threads SQL de recherche. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Moyenne, Somme |
ThreadpoolBulkQueue |
Nombre de tâches mises en file d'attente dans le groupe de threads en bloc. Si la taille de la file d'attente reste constamment élevée, envisagez de mettre votre cluster à l'échelle. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
ThreadpoolBulkRejected |
Nombre de tâches rejetées dans le groupe de threads en bloc. Si ce nombre augmente constamment, envisagez de mettre votre cluster à l'échelle. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme |
ThreadpoolBulkThreads |
Taille du groupe de threads en bloc. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Moyenne, Somme |
ThreadpoolIndexSearcherQueue |
Nombre de tâches en file d'attente dans le pool de threads du chercheur d'index. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
ThreadpoolIndexSearcherRejected |
Nombre de tâches rejetées dans le pool de threads du chercheur d'index. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme |
ThreadpoolIndexSearcherThreads |
Taille du pool de threads du chercheur d'index. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Moyenne, Somme |
ThreadpoolWriteThreads |
Taille du groupe de threads d'écriture. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Moyenne, Somme |
ThreadpoolWriteQueue |
Nombre de tâches mises en file d'attente dans le groupe de threads d'écriture. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Moyenne, Somme |
ThreadpoolWriteRejected |
Nombre de tâches rejetées dans le groupe de threads d'écriture. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Moyenne, Somme NoteLa taille de la file d'attente d'écriture par défaut étant passée de 200 à 10 000 dans la version 7.1, cette métrique n'est plus le seul indicateur des rejets du OpenSearch Service. Utilisez les métriques |
CoordinatingWriteRejected |
Le nombre total de rejets se sont produits sur le nœud de coordination en raison de la pression d'indexation depuis le dernier démarrage du processus OpenSearch de service. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Moyenne, Somme Cette métrique est disponible dans la version 7.1 et les versions ultérieures. |
PrimaryWriteRejected |
Le nombre total de rejets se sont produits sur les partitions principales en raison de la pression d'indexation depuis le dernier démarrage du processus de OpenSearch service. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Moyenne, Somme Cette métrique est disponible dans la version 7.1 et les versions ultérieures. |
ReplicaWriteRejected |
Le nombre total de rejets se sont produits sur les répliques en raison de la pression d'indexation depuis le dernier démarrage du processus de OpenSearch service. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Moyenne, Somme Cette métrique est disponible dans la version 7.1 et les versions ultérieures. |
UltraWarm métriques
Amazon OpenSearch Service fournit les métriques suivantes pour les UltraWarmnœuds.
| Métrique | Description |
|---|---|
WarmCPUUtilization |
Pourcentage d'CPUutilisation des UltraWarm nœuds du cluster. La valeur maximale indique le nœud le plus CPU utilisé. La moyenne représente tous les UltraWarm nœuds du cluster. Cette métrique est également disponible pour les UltraWarm nœuds individuels. Statistiques pertinentes : Maximum, Moyenne |
WarmFreeStorageSpace |
Quantité d'espace de stockage à chaud gratuit en Mo. Parce qu'il UltraWarm utilise Amazon S3 plutôt que des disques attachés, Statistiques pertinentes : somme |
WarmSearchableDocuments |
Nombre total de documents consultables sur tous les index à chaud du cluster. Vous devez laisser la période à une minute pour obtenir une valeur précise. Statistiques pertinentes : somme |
WarmSearchLatency
|
Différence de temps total, en millisecondes, prise par toutes les recherches UltraWarm entre la minute N et la minute (N-1). Statistiques pertinentes concernant le nœud : Moyenne Statistiques pertinentes concernant le cluster : Moyenne, Maximum |
WarmSearchRate
|
Le nombre total de demandes de recherche par minute pour toutes les partitions d'un UltraWarm nœud. Un seul appel au Statistiques pertinentes concernant le nœud : Moyenne Statistiques pertinentes concernant le cluster : Moyenne, Maximum, Somme |
WarmStorageSpaceUtilization |
Volume total d'espace de stockage à chaud, en Mio, utilisé par le cluster. Statistiques pertinentes : Maximum |
HotStorageSpaceUtilization
|
Volume total d'espace de stockage hot utilisé par le cluster. Statistiques pertinentes : Maximum |
WarmSysMemoryUtilization |
Pourcentage de mémoire du nœud à chaud actuellement utilisée. Statistiques pertinentes : Maximum |
HotToWarmMigrationQueueSize
|
Nombre d'index actuellement en attente de migration du stockage hot vers le stockage à chaud. Statistiques pertinentes : Maximum |
WarmToHotMigrationQueueSize
|
Nombre d'index actuellement en attente de migration du stockage à chaud vers le stockage hot. Statistiques pertinentes : Maximum |
HotToWarmMigrationFailureCount
|
Nombre total de migrations hot vers à chaud ayant échoué. Statistiques pertinentes : somme |
HotToWarmMigrationForceMergeLatency
|
Latence moyenne de l'étape de fusion forcée du processus de migration. Si cette étape se révèle particulièrement chronophage, envisagez d'augmenter Statistiques pertinentes : Moyenne |
HotToWarmMigrationSnapshotLatency
|
Latence moyenne de l'étape d'instantané du processus de migration. Si cette étape se révèle particulièrement chronophage, assurez-vous que vos partitions sont correctement dimensionnées et distribuées dans tout le cluster. Statistiques pertinentes : Moyenne |
HotToWarmMigrationProcessingLatency
|
Latence moyenne des migrations hot vers à chaud réussies, sans compter le temps passé dans la file d'attente. Cette valeur correspond à la durée nécessaire pour terminer les étapes de fusion forcée, d'instantané et de déplacement de partitions du processus de migration. Statistiques pertinentes : Moyenne |
HotToWarmMigrationSuccessCount
|
Nombre total de migrations hot vers à chaud réussies. Statistiques pertinentes : somme |
HotToWarmMigrationSuccessLatency
|
Latence moyenne des migrations hot vers à chaud, en comptant le temps passé dans la file d'attente. Statistiques pertinentes : Moyenne |
WarmThreadpoolSearchThreads |
Taille du pool de threads UltraWarm de recherche. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Moyenne, Somme |
WarmThreadpoolSearchRejected |
Le nombre de tâches rejetées dans le pool UltraWarm de fils de recherche. Si ce nombre ne cesse d'augmenter, pensez à ajouter d'autres UltraWarm nœuds. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme |
WarmThreadpoolSearchQueue |
Nombre de tâches en file d'attente dans le pool de threads de UltraWarm recherche. Si la taille de la file d'attente est constamment élevée, envisagez d'ajouter d'autres UltraWarm nœuds. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
WarmJVMMemoryPressure |
Pourcentage maximal du tas Java utilisé pour les UltraWarm nœuds. Statistiques pertinentes : Maximum NoteLa logique de cette métrique a changé dans le logiciel de service R20220323. Pour plus d'informations, veuillez consulter les notes de mise à jour. |
WarmOldGenJVMMemoryPressure |
Pourcentage maximal du segment de mémoire Java utilisé pour « l'ancienne génération » par UltraWarm nœud. Statistiques pertinentes : Maximum |
WarmJVMGCYoungCollectionCount |
Le nombre de fois que la collecte des déchets de la « jeune génération » a été exécutée sur UltraWarm des nœuds. Un nombre important et évolutif d'exécutions est une part normale des opérations de cluster. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
WarmJVMGCYoungCollectionTime |
Temps, en millisecondes, passé par le cluster à effectuer le ramassage des déchets de « jeune génération » sur les nœuds. UltraWarm Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
WarmJVMGCOldCollectionCount |
Le nombre de fois que la collecte des déchets « ancienne génération » s'est exécutée sur UltraWarm des nœuds. Dans un cluster doté de ressources suffisantes, ce nombre doit rester faible et évoluer peu fréquemment. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
WarmConcurrentSearchRate |
Nombre total de demandes de recherche utilisant une recherche par segment simultanée par minute pour toutes les partitions d'un UltraWarm nœud. Un seul appel au Statistiques pertinentes concernant le nœud : Moyenne Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
WarmConcurrentSearchLatency |
Différence de temps total, en millisecondes, prise par toutes les recherches utilisant une recherche par segment simultanée dans un UltraWarm nœud entre la minute N et la minute (N-1). Statistiques pertinentes concernant le nœud : Moyenne Statistiques pertinentes concernant le cluster : Maximum, Moyenne |
WarmThreadpoolIndexSearcherQueue |
Nombre de tâches en file d'attente dans le pool de threads du chercheur d' UltraWarm index. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme, Maximum, Moyenne |
WarmThreadpoolIndexSearcherRejected |
Nombre de tâches rejetées dans le pool de threads du chercheur d' UltraWarm index. Statistiques pertinentes concernant le nœud : Maximum Statistiques pertinentes concernant le cluster : Somme |
WarmThreadpoolIndexSearcherThreads |
Taille du pool de threads du chercheur d' UltraWarm index. Statistiques pertinentes concernant le nœud : Maximum Statistiques de cluster pertinentes : somme, moyenne |
Métriques de stockage à froid
Amazon OpenSearch Service fournit les statistiques suivantes pour le stockage à froid.
| Métrique | Description |
|---|---|
ColdStorageSpaceUtilization
|
Volume total d'espace de stockage à froid, en Mio, utilisé par le cluster. Statistiques pertinentes : maximum |
ColdToWarmMigrationFailureCount |
Nombre total de migrations à froid vers à chaud ayant échoué. Statistiques pertinentes : somme |
ColdToWarmMigrationLatency |
Temps nécessaire pour mener à bien les migrations à froid vers à chaud. Statistiques pertinentes : Moyenne |
ColdToWarmMigrationQueueSize |
Nombre d'index actuellement en attente de migration du stockage à froid vers le stockage à chaud. Statistiques pertinentes : Maximum |
ColdToWarmMigrationSuccessCount
|
Nombre total de migrations à froid vers à chaud réussies. Statistiques pertinentes : somme |
WarmToColdMigrationFailureCount
|
Nombre total de migrations à chaud vers à froid ayant échoué. Statistiques pertinentes : somme |
WarmToColdMigrationLatency |
Temps nécessaire pour mener à bien les migrations à chaud vers à froid. Statistiques pertinentes : Moyenne |
WarmToColdMigrationQueueSize |
Nombre d'index actuellement en attente de migration du stockage à chaud vers le stockage à froid. Statistiques pertinentes : Maximum |
WarmToColdMigrationSuccessCount |
Nombre total de migrations à chaud vers à froid réussies. Statistiques pertinentes : somme |
OR1métriques
Amazon OpenSearch Service fournit les statistiques suivantes pour les OR1instances.
| Métrique | Description |
|---|---|
RemoteStorageUsedSpace
|
La quantité totale d'espace Amazon S3, en MiB, utilisée par le cluster. Statistiques pertinentes : somme |
RemoteStorageWriteRejected |
Nombre total de demandes rejetées sur les partitions principales en raison du stockage à distance et de la pression de réplication. Ceci est calculé à partir du dernier démarrage du processus de OpenSearch service. Statistiques pertinentes : somme |
ReplicationLagMaxTime |
Durée, en millisecondes, pendant laquelle les fragments de réplique se trouvent derrière les fragments principaux. Statistiques pertinentes : Maximum |
Métriques d'alerte
Amazon OpenSearch Service fournit les métriques suivantes pour les alertes.
| Métrique | Description |
|---|---|
AlertingDegraded |
Une valeur de 1 signifie que l'index d'alerte est rouge ou qu'un ou plusieurs nœuds ne sont pas prévus. La valeur 0 indique un comportement normal. Statistiques pertinentes : Maximum |
AlertingIndexExists |
Une valeur de 1 signifie que l'index Statistiques pertinentes : Maximum |
AlertingIndexStatus.green |
État de santé de l'index. Une valeur de 1 signifie vert. Une valeur de 0 signifie que l'index n'existe pas ou n'est pas vert. Statistiques pertinentes : Maximum |
AlertingIndexStatus.red |
État de santé de l'index. Une valeur de 1 signifie rouge. Une valeur de 0 signifie que l'index n'existe pas ou n'est pas rouge. Statistiques pertinentes : Maximum |
AlertingIndexStatus.yellow |
État de santé de l'index. Une valeur de 1 signifie jaune. Une valeur de 0 signifie que l'index n'existe pas ou n'est pas jaune. Statistiques pertinentes : Maximum |
AlertingNodesNotOnSchedule |
Une valeur de 1 signifie que certaines tâches ne sont pas exécutées dans les délais prévus. La valeur 0 signifie que tous les travaux d'alerte sont exécutés selon les prévisions (ou qu'il n'existe aucun travail d'alerte). Vérifiez la console OpenSearch de service ou faites une Statistiques pertinentes : Maximum |
AlertingNodesOnSchedule |
La valeur 1 signifie que toutes les tâches d'alerte sont exécutées selon les prévisions (ou qu'il n'existe pas de tâches d'alerte). Une valeur de 0 signifie que certaines tâches ne sont pas exécutées dans les délais prévus. Statistiques pertinentes : Maximum |
AlertingScheduledJobEnabled |
Une valeur de 1 signifie que le paramètre de cluster Statistiques pertinentes : Maximum |
Métriques de détection d'anomalies
Amazon OpenSearch Service fournit les mesures suivantes pour la détection des anomalies.
| Métrique | Description |
|---|---|
ADPluginUnhealthy |
Une valeur de 1 signifie que le plugin de détection d'anomalies ne fonctionne pas correctement, soit en raison d'un nombre élevé de défaillances, soit parce que l'un des indices qu'il utilise est rouge. Une valeur de 0 indique que le plugin fonctionne comme prévu. Statistiques pertinentes : Maximum |
ADExecuteRequestCount |
Nombre de demandes pour détecter des anomalies. Statistiques pertinentes : somme |
ADExecuteFailureCount
|
Nombre de demandes ayant échoué pour détecter des anomalies. Statistiques pertinentes : somme |
ADHCExecuteFailureCount |
Nombre de demandes visant à détecter des anomalies à cardinalité élevée ayant échoué. Statistiques pertinentes : somme |
ADHCExecuteRequestCount |
Nombre de demandes visant à détecter des anomalies à cardinalité élevée. Statistiques pertinentes : somme |
ADAnomalyResultsIndexStatusIndexExists |
Une valeur de 1 signifie l'index vers lequel l'alias Statistiques pertinentes : Maximum |
ADAnomalyResultsIndexStatus.red |
La valeur 1 signifie que l'index vers lequel l'alias Statistiques pertinentes : Maximum |
ADAnomalyDetectorsIndexStatusIndexExists |
Une valeur de 1 signifie que l'index Statistiques pertinentes : Maximum |
ADAnomalyDetectorsIndexStatus.red |
Une valeur de 1 signifie que l'index Statistiques pertinentes : Maximum |
ADModelsCheckpointIndexStatusIndexExists |
Une valeur de 1 signifie que l'index Statistiques pertinentes : Maximum |
ADModelsCheckpointIndexStatus.red |
Une valeur de 1 signifie que l'index Statistiques pertinentes : Maximum |
Métriques de recherche asynchrone
Amazon OpenSearch Service fournit les métriques suivantes pour la recherche asynchrone.
Statistiques de nœud coordinateur de recherche asynchrone (par nœud de coordinateur)
| Métrique | Description |
|---|---|
AsynchronousSearchSubmissionRate |
Nombre de recherches asynchrones envoyées au cours de la dernière minute. |
AsynchronousSearchInitializedRate |
Nombre de recherches asynchrones initialisées au cours de la dernière minute. |
AsynchronousSearchRunningCurrent |
Nombre de recherches asynchrones en cours d'exécution. |
AsynchronousSearchCompletionRate |
Nombre de recherches asynchrones ayant abouti au cours de la dernière minute. |
AsynchronousSearchFailureRate |
Nombre de recherches asynchrones ayant abouti et échoué au cours de la dernière minute. |
AsynchronousSearchPersistRate |
Nombre de recherches asynchrones ayant perduré au cours de la dernière minute. |
AsynchronousSearchPersistFailedRate |
Nombre de recherches asynchrones n'ayant pas perduré au cours de la dernière minute. |
AsynchronousSearchRejected |
Nombre total de recherches asynchrones rejetées depuis le démarrage du nœud. |
AsynchronousSearchCancelled |
Nombre total de recherches asynchrones annulées depuis le démarrage du nœud. |
AsynchronousSearchMaxRunningTime |
Durée de la plus longue recherche asynchrone en cours d'exécution sur un nœud au cours de la dernière minute. |
Statistiques concernant le cluster en matière de recherche asynchrone
| Métrique | Description |
|---|---|
AsynchronousSearchStoreHealth |
L'état de santé du magasin dans l'index persistant (RED/non-RED) au cours de la dernière minute. |
AsynchronousSearchStoreSize |
Taille de l'index système de toutes les partitions au cours de la dernière minute. |
AsynchronousSearchStoredResponseCount |
Nombre de réponses stockées dans l'index système au cours de la dernière minute. |
Réglage automatique des métriques
Amazon OpenSearch Service fournit les statistiques suivantes pour Auto-Tune.
| Métrique | Description |
|---|---|
AutoTuneChangesHistoryHeapSize |
Historique des modifications en MiB pour les valeurs de réglage de la taille des tas. |
AutoTuneChangesHistoryJVMYoungGenArgs |
Historique des modifications apportées aux JVM YongGen arguments. |
AutoTuneFailed |
Un booléen qui indique si le changement Auto-Tune a échoué. |
AutoTuneSucceeded |
Un booléen qui indique si le changement Auto-Tune a réussi. |
AutoTuneValue |
L'historique des modifications de la file d'attente (nombre) et les réglages du cache changent l'historique des modifications (en MiB) pour des modifications non perturbatrices. |
Multi-AZ avec métriques de veille
Amazon OpenSearch Service fournit les mesures suivantes pour le mode Multi-AZ avec mode veille.
Mesures au niveau des nœuds pour les nœuds de données dans les zones de disponibilité actives
| Métrique | Description |
|---|---|
CPUUtilization |
Pourcentage d'CPUutilisation des nœuds de données du cluster. La valeur maximale indique le nœud le plus CPU utilisé. La moyenne représente tous les nœuds du cluster. Cette métrique est également disponible pour les nœuds individuels. |
FreeStorageSpace |
Espace libre pour les nœuds de données du cluster. La console OpenSearch de service affiche cette valeur en GiB. La CloudWatch console Amazon l'affiche en MiB. |
JVMMemoryPressure |
Pourcentage maximal du segment de mémoire Java utilisé pour tous les nœuds de données du cluster. OpenSearch Le service utilise la moitié de celle d'une instance RAM pour le tas Java, jusqu'à une taille de tas de 32 GiB. Vous pouvez redimensionner les instances verticalement jusqu'à 64 GiBRAM, puis vous pouvez les redimensionner horizontalement en ajoutant des instances. Consultez CloudWatch Alarmes recommandées pour Amazon OpenSearch Service. |
SysMemoryUtilization |
Pourcentage de mémoire de l'instance actuellement utilisée. Les valeurs élevées de cette métrique sont normales et ne représentent généralement pas un problème lié à votre cluster. Pour obtenir un meilleur indicateur des éventuels problèmes de performance et de stabilité, veuillez consulter la métrique JVMMemoryPressure. |
IndexingLatency |
Différence de temps total, en millisecondes, prise par toutes les opérations d'indexation dans un nœud entre la minute N et la minute (N-1). |
IndexingRate |
Nombre d'opérations d'indexation par minute. |
SearchLatency |
Différence de temps total, en millisecondes, prise par toutes les recherches dans un nœud entre la minute N et la minute (N-1). |
SearchRate |
Nombre total de demandes de recherche par minute pour toutes les partitions d'un nœud de données. |
ThreadpoolSearchQueue |
Nombre de tâches mises en file d'attente dans le groupe de threads de recherche. Si la taille de la file d'attente reste constamment élevée, envisagez de mettre votre cluster à l'échelle. La taille maximale de la file d'attente de recherche est de 1 000. |
ThreadpoolWriteQueue |
Nombre de tâches mises en file d'attente dans le groupe de threads d'écriture. |
ThreadpoolSearchRejected |
Nombre de tâches rejetées dans le groupe de threads de recherche. Si ce nombre augmente constamment, envisagez de mettre votre cluster à l'échelle. |
ThreadpoolWriteRejected |
Nombre de tâches rejetées dans le groupe de threads d'écriture. |
Mesures au niveau du cluster pour les clusters situés dans des zones de disponibilité actives
| Métrique | Description |
|---|---|
DataNodes |
Le nombre total de partitions actives et en veille. |
DataNodesShards.active |
Nombre total de partitions primaires et de partitions de réplica actives. |
DataNodesShards.unassigned |
Nombre de partitions non allouées aux nœuds du cluster. |
DataNodesShards.initializing |
Nombre de partitions en cours d'initialisation. |
DataNodesShards.relocating |
Nombre de partitions en cours de relocalisation. |
Mesures de rotation des zones de disponibilité
Si c'est le casActiveReads., la zone est active. Si c'est le casAvailability-Zone = 1ActiveReads., la zone est en veille.Availability-Zone =
0
Mesures ponctuelles
Amazon OpenSearch Service fournit les statistiques suivantes pour les recherches ponctuelles (PIT).
PITstatistiques du nœud coordinateur (par nœud coordinateur)
| Métrique | Description |
|---|---|
CurrentPointInTime |
Nombre de contextes de PIT recherche actifs dans le nœud. |
TotalPointInTime |
Nombre de contextes de PIT recherche expirés depuis le moment de disponibilité du nœud. |
AvgPointInTimeAliveTime |
Durée moyenne des contextes de PIT recherche maintenus en vie depuis le temps de disponibilité du nœud. |
HasActivePointInTime |
Une valeur de 1 indique qu'il existe PIT des contextes actifs sur les nœuds depuis leur disponibilité. Une valeur de 0 signifie qu'il n'y en a pas. |
HasUsedPointInTime |
Une valeur de 1 indique que des PIT contextes ont expiré sur les nœuds depuis leur disponibilité. Une valeur de 0 signifie qu'il n'y en a pas. |
SQLmétriques
Amazon OpenSearch Service fournit les statistiques suivantes pour l'SQLassistance.
| Métrique | Description |
|---|---|
SQLFailedRequestCountByCusErr |
Le nombre de demandes Statistiques pertinentes : somme |
SQLFailedRequestCountBySysErr |
Le nombre de demandes adressées au Statistiques pertinentes : somme |
SQLRequestCount |
Le nombre de demandes adressées au Statistiques pertinentes : somme |
SQLDefaultCursorRequestCount |
Similaire aux demandes de pagination Statistiques pertinentes : somme |
SQLUnhealthy |
Une valeur de 1 indique que, en réponse à certaines demandes, le SQL plugin renvoie 5 xx codes de réponse ou transmet une requête non valide DSL à OpenSearch. Les autres demandes devraient continuer à aboutir avec succès. La valeur 0 indique qu'il n'y a pas de défaillance récente. Si vous voyez une valeur soutenue de 1, résolvez les demandes adressées par vos clients au plugin. Statistiques pertinentes : Maximum |
Métriques k-NN
Amazon OpenSearch Service inclut les mesures suivantes pour le plug-in k-nearest neighbor (k-NN).
| Métrique | Description |
|---|---|
KNNCacheCapacityReached |
Métrique par nœud permettant de déterminer si la capacité du cache a été atteinte. Cette métrique est uniquement pertinente dans le cadre d'une recherche k-NN approximative. Statistiques pertinentes : Maximum |
KNNCircuitBreakerTriggered |
Métrique par cluster permettant de déterminer si le disjoncteur de circuit est déclenché. Si des nœuds renvoient une valeur de 1 pour Statistiques pertinentes : Maximum |
KNNEvictionCount |
Métrique par nœud du nombre de graphiques ayant été expulsés du cache en raison de contraintes de mémoire ou de temps d'inactivité. Les expulsions explicites se produisant en raison de la suppression d'index ne sont pas comptabilisées. Cette métrique est uniquement pertinente dans le cadre d'une recherche k-NN approximative. Statistiques pertinentes : somme |
KNNGraphIndexErrors |
Métrique par nœud du nombre de demandes d'ajout du champ Statistiques pertinentes : somme |
KNNGraphIndexRequests |
Métrique par nœud du nombre de demandes d'ajout du champ Statistiques pertinentes : somme |
KNNGraphMemoryUsage |
Métrique par nœud de la taille actuelle du cache (taille totale de tous les graphes en mémoire) en kilo-octets. Cette métrique est uniquement pertinente dans le cadre d'une recherche k-NN approximative. Statistiques pertinentes : Moyenne |
KNNGraphQueryErrors |
Métrique par nœud du nombre de requêtes de graphe ayant généré une erreur. Statistiques pertinentes : somme |
KNNGraphQueryRequests |
Métrique par nœud du nombre de requêtes de graphe. Statistiques pertinentes : somme |
KNNHitCount |
Métrique par nœud du nombre d'accès au cache. Un accès au cache intervient lorsqu'un utilisateur interroge un graphe déjà chargé en mémoire. Cette métrique est uniquement pertinente dans le cadre d'une recherche k-NN approximative. Statistiques pertinentes : somme |
KNNLoadExceptionCount |
Métrique par nœud indiquant le nombre de fois où une exception s'est produite lors d'une tentative de chargement de graphe dans le cache. Cette métrique est uniquement pertinente dans le cadre d'une recherche k-NN approximative. Statistiques pertinentes : somme |
KNNLoadSuccessCount |
Métrique par nœud indiquant le nombre de fois où le plugin a chargé un graphe dans le cache. Cette métrique est uniquement pertinente dans le cadre d'une recherche k-NN approximative. Statistiques pertinentes : somme |
KNNMissCount |
Métrique par nœud du nombre d'échecs du cache. Un échec du cache intervient lorsqu'un utilisateur interroge un graphe pas encore chargé en mémoire. Cette métrique est uniquement pertinente dans le cadre d'une recherche k-NN approximative. Statistiques pertinentes : somme |
KNNQueryRequests |
Métrique par nœud du nombre de demandes de requête reçues par le plugin k-NN. Statistiques pertinentes : somme |
KNNScriptCompilationErrors |
Métrique par nœud du nombre d'erreurs lors d'une compilation de script. Cette statistique est uniquement pertinente pour la recherche de script de score k-NN. Statistiques pertinentes : somme |
KNNScriptCompilations |
Métrique par nœud indiquant le nombre de fois où le script k-NN a été compilé. Cette valeur doit généralement correspondre à 1 ou 0, mais si le cache contenant les scripts compilés est plein, le script k-NN peut être recompilé. Cette statistique est uniquement pertinente pour la recherche de script de score k-NN. Statistiques pertinentes : somme |
KNNScriptQueryErrors |
Métrique par nœud du nombre d'erreurs lors des requêtes de script. Cette statistique est uniquement pertinente pour la recherche de script de score k-NN. Statistiques pertinentes : somme |
KNNScriptQueryRequests |
Métrique par nœud du nombre total de requêtes de script. Cette statistique est uniquement pertinente pour la recherche de script de score k-NN. Statistiques pertinentes : somme |
KNNTotalLoadTime |
Délai, en nanosecondes, mis par k-NN pour charger les graphes dans le cache. Cette métrique est uniquement pertinente dans le cadre d'une recherche k-NN approximative. Statistiques pertinentes : somme |
Métriques de recherche inter-clusters
Amazon OpenSearch Service fournit les métriques suivantes pour la recherche entre clusters.
Métriques de domaine source
| Métrique | Dimension | Description |
|---|---|---|
CrossClusterOutboundConnections |
|
Nombre de nœuds connectés. Si votre réponse inclut un ou plusieurs domaines ignorés, utilisez cette métrique pour suivre les connexions non saines. Si ce nombre chute jusqu'à 0, la connexion n'est pas saine. |
CrossClusterOutboundRequests |
|
Nombre de demandes de recherche envoyées au domaine de destination. À utiliser pour vérifier si la charge de requêtes de recherche entre clusters submerge votre domaine, corrélez tout pic de cette métrique avec tout picJVM/CPU. |
Métrique de domaine de destination
| Métrique | Dimension | Description |
|---|---|---|
CrossClusterInboundRequests |
|
Nombre de demandes de connexion entrantes reçues du domaine source. |
Ajoutez une CloudWatch alarme au cas où vous perdriez la connexion de façon inattendue. Pour connaître les étapes de création d'une alarme, voir Création CloudWatch d'une alarme basée sur un seuil statique.
Métriques de réplication inter-clusters (CCR)
Amazon OpenSearch Service fournit les métriques suivantes pour la réplication entre clusters.
| Métrique | Description |
|---|---|
ReplicationRate |
Le taux moyen d'opérations de réplication par seconde. Cette métrique est similaire à la métrique |
LeaderCheckPoint |
Pour une connexion spécifique, la somme des valeurs des points de contrôle des principaux pour tous les index de réplication. Vous pouvez utiliser cette métrique pour mesurer la latence de réplication. |
FollowerCheckPoint |
Pour une connexion spécifique, la somme des valeurs des points de contrôle des suiveurs pour tous les index de réplication. Vous pouvez utiliser cette métrique pour mesurer la latence de réplication. |
ReplicationNumSyncingIndices |
Le nombre d'index qui ont un statut de réplication |
ReplicationNumBootstrappingIndices |
Le nombre d'index qui ont un statut de réplication |
ReplicationNumPausedIndices |
Le nombre d'index qui ont un statut de réplication |
ReplicationNumFailedIndices |
Le nombre d'index qui ont un statut de réplication |
|
|
Nombre de demandes de transport de réplication sur le domaine suiveur. Les demandes de transport sont internes et se produisent chaque fois qu'une API opération de réplication est appelée. Ils se produisent également lorsque le domaine suiveur interroge un changement par rapport au domaine leader. |
|
|
Nombre de demandes de transport de réplication sur le domaine principal. Les demandes de transport sont internes et se produisent chaque fois qu'une API opération de réplication est appelée. |
AutoFollowNumSuccessStartReplication |
Le nombre d'index suiveurs qui ont été créés avec succès par une règle de réplication pour une connexion spécifique. |
AutoFollowNumFailedStartReplication |
Le nombre d'index suiveurs qui n'ont pas pu être créés par une règle de réplication alors qu'il existait un modèle correspondant. Ce problème peut survenir en raison d'une avarie du réseau sur le cluster distant ou d'un problème de sécurité (c'est-à-dire que le rôle associé n'a pas l'autorisation de démarrer la réplication). |
AutoFollowLeaderCallFailure |
Indique si des requêtes ont échoué de l'index suiveur vers l'index principal pour extraire de nouvelles données. Une valeur de |
Métriques Learning to Rank
Amazon OpenSearch Service fournit les statistiques suivantes pour Learning to Rank.
| Métrique | Description |
|---|---|
LTRRequestTotalCount |
Nombre total de demandes de classement. |
LTRRequestErrorCount |
Nombre total de demandes ayant échoué. |
LTRStatus.red |
Assure un suivi si l'un des index nécessaires à l'exécution du plugin est rouge. |
LTRMemoryUsage |
Mémoire totale utilisée par le plugin. |
LTRFeatureMemoryUsageInBytes |
Mémoire, en octets, utilisée par les champs des fonctions Learning to Rank. |
LTRFeaturesetMemoryUsageInBytes |
Mémoire, en octets, utilisée par tous les ensembles de fonctions Learning to Rank. |
LTRModelMemoryUsageInBytes |
Mémoire, en octets, utilisée par tous les modèles Learning to Rank. |
Métriques du langage de traitement PPL (Piped Processing Language)
Amazon OpenSearch Service fournit les métriques suivantes pour Piped Processing Language.
| Métrique | Description |
|---|---|
PPLFailedRequestCountByCusErr |
Le nombre de demandes |
PPLFailedRequestCountBySysErr |
Le nombre de demandes adressées au |
PPLRequestCount |
Le nombre de demandes adressées au |
