Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
AWS ParallelClusterprocessus
Cette section s'applique uniquement aux clusters HPC déployés avec l'un des planificateurs de tâches traditionnels pris en charge (SGE, Slurm or Torque). Lorsqu'il est utilisé avec ces planificateurs, il AWS ParallelCluster gère le provisionnement et la suppression des nœuds de calcul en interagissant à la fois avec le groupe Auto Scaling et le planificateur de tâches sous-jacent.
Pour les clusters HPC basés surAWS Batch, AWS ParallelCluster s'appuie sur les fonctionnalités fournies par le AWS Batch pour la gestion des nœuds de calcul.
Note
À partir de la version 2.11.5, AWS ParallelCluster il n'est pas possible d'utiliser des planificateursSGE. Torque Vous pouvez continuer à les utiliser dans les versions antérieures à la version 2.11.4, mais elles ne sont pas éligibles aux futures mises à jour ni à l'assistance pour la résolution des problèmes de la part des équipes de AWS service et de AWS support.
SGE and Torque integration processes
Note
Cette section s'applique uniquement aux AWS ParallelCluster versions antérieures à la version 2.11.4. À partir de la version 2.11.5, AWS ParallelCluster elle ne prend pas en charge l'utilisation des Torque planificateurs, d'Amazon SNS SGE et d'Amazon SQS.
Vue d'ensemble générale
Le cycle de vie d'un cluster commence après sa création par un utilisateur. En règle générale, un cluster est créé à partir de l'interface de ligne de commande (CLI). Une fois qu'il a été créé, un cluster existe jusqu'à ce qu'il soit supprimé. Les démons AWS ParallelCluster s'exécutent sur les nœuds du cluster, principalement pour gérer l’élasticité du cluster HPC. Le schéma suivant illustre un flux de travail utilisateur et le cycle de vie du cluster. Les sections qui suivent décrivent les démons AWS ParallelCluster qui sont utilisés pour gérer le cluster.
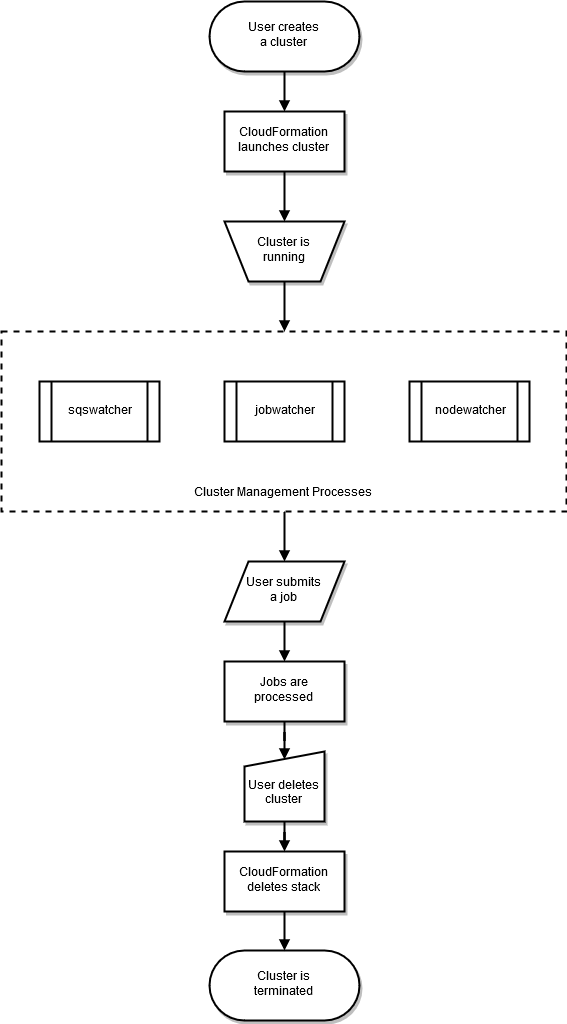
Avec SGE et Torque planificateurs nodewatcherjobwatcher, AWS ParallelCluster utilisations et sqswatcher processus.
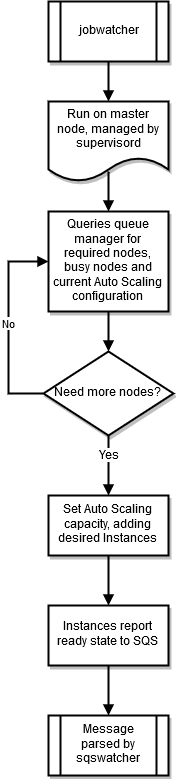
jobwatcher
Lorsqu'un cluster est en cours d'exécution, un processus appartenant à l'utilisateur root surveille le planificateur (SGEouTorque) configuré. Chaque minute, il évalue la file d'attente afin de décider quand passer à la vitesse supérieure.
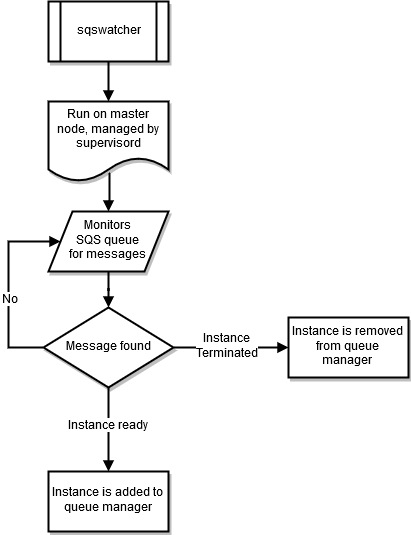
sqswatcher
Le sqswatcher processus surveille les messages Amazon SQS envoyés par Auto Scaling pour vous informer des changements d'état au sein du cluster. Lorsqu'une instance est mise en ligne, elle envoie un message « instance prête » à Amazon SQS. Ce message est capté parsqs_watcher, en cours d'exécution sur le nœud principal. Ces messages permettent d'informer le gestionnaire de file d'attente lorsque de nouvelles instances sont mises en ligne ou résiliées, pour qu'il puisse les ajouter à la file d'attente ou les en supprimer.
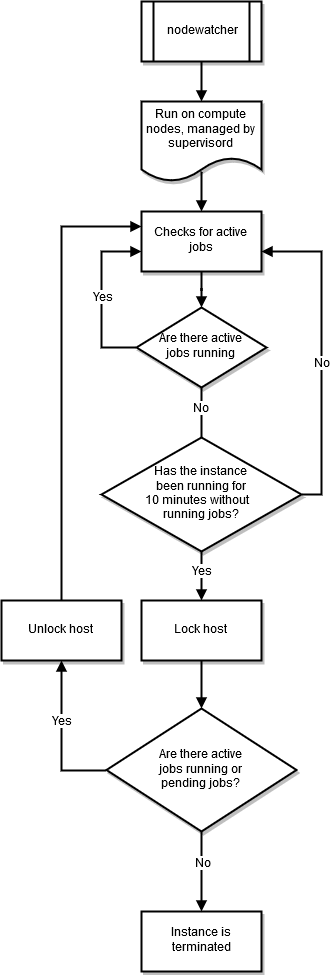
nodewatcher
Le processus nodewatcher s'exécute sur chaque nœud dans le parc d'instances de calcul. Une fois la période scaledown_idletime écoulée, telle que définie par l'utilisateur, l'instance est mise hors service.
Slurm integration processes
Avec des Slurm planificateurs, des AWS ParallelCluster utilisations clustermgtd et des processus. computemgt
clustermgtd
Les clusters qui s'exécutent en mode hétérogène (indiqué par la spécification d'une queue_settings valeur) possèdent un processus daemon de gestion de clusters (clustermgtd) qui s'exécute sur le nœud principal. Ces tâches sont effectuées par le démon de gestion du cluster.
-
Nettoyage des partitions inactives
-
Gestion de la capacité statique : assurez-vous que la capacité statique est toujours active et saine
-
Synchronisez le planificateur avec Amazon EC2.
-
Nettoyage des instances orphelines
-
Restaurez l'état du nœud du planificateur lors de la résiliation d'Amazon EC2 qui se produit en dehors du flux de travail de suspension
-
Gestion défectueuse des instances Amazon EC2 (échec des contrôles de santé Amazon EC2)
-
Gestion des événements de maintenance planifiés
-
Gestion des nœuds du planificateur défectueux (échec des contrôles de santé du planificateur)
computemgtd
Les clusters qui s'exécutent en mode hétérogène (indiqué par la spécification d'une queue_settings valeur) possèdent des processus daemon (computemgtd) de gestion du calcul qui s'exécutent sur chacun des nœuds de calcul. Toutes les cinq (5) minutes, le démon de gestion du calcul confirme que le nœud principal est accessible et qu'il est en bon état. Si cinq (5) minutes s'écoulent pendant lesquelles le nœud principal n'est pas joignable ou n'est pas en bon état, le nœud de calcul est arrêté.
