Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Gestion des caches de clusters
La mise en cache est l'une des fonctionnalités les plus importantes de toute base de données (DB) car elle permet de réduire les E/S du disque. Les données les plus fréquemment consultées sont stockées dans une zone mémoire appelée cache tampon. Lorsqu'une requête s'exécute fréquemment, elle extrait les données directement du cache plutôt que du disque. Cette solution est plus rapide et améliore l'évolutivité et les performances des applications. Vous configurez la taille du cache PostgreSQL à l'aide dushared_buffers paramètre. Pour de plus amples informations, veuillez consulter Memory
Après un basculement, la gestion du cache de cluster (CCM) dans l'édition compatible avec Amazon Aurora PostgreSQL est conçue pour améliorer les performances de restauration des applications et des bases de données. Dans une situation de basculement classique sans CCM, vous pouvez constater une dégradation temporaire, mais conséquente, des performances. Cela est dû au fait que le cache des caches de mémoire tampon est vide lorsque l'instance de base de données de basculement démarre. Un cache vide est également appelé cache passif. L'instance de base de données doit lire depuis le disque, ce qui est plus lent que la lecture depuis le cache.
Lorsque vous implémentez CCM, vous choisissez une instance de base de données de lecteur préférée, et CCM synchronise en permanence sa mémoire cache avec celle de l'instance de base de données principale, ou d'écriture. En cas de basculement, l'instance de base de données de lecteur préférée est promue en tant que nouvelle instance de base de données de rédacteur. Comme il possède déjà une mémoire cache, connue sous le nom de cache chaud, cela minimise l'impact du basculement sur les performances de l'application.
Comment fonctionne la gestion du cache du cluster ?
Les instances de base de données de basculement se situent dans des zones de disponibilité différentes de celles de l'instance de base de données d'écriture principale. L'instance de base de données de lecteur préférée est la cible de basculement prioritaire, qui est spécifiée en lui affectant le niveau de priorité de niveau 0.
Note
La priorité du niveau de promotion est une valeur qui spécifie l'ordre dans lequel un lecteur Aurora est promu comme instance de base de données de l'enregistreur après un échec. Les valeurs valides sont comprises dans la plage 0–15, 0 étant la priorité la plus élevée et 15 la priorité la plus faible. Pour plus d'informations sur le niveau de promotion, veuillez consulter Tolérance aux pannes d'un cluster de base de données Aurora. La modification du niveau de promotion n'entraîne pas d'interruption de service.
CCM synchronise le cache de l'instance de base de données de rédacteur à l'instance de base de données de lecteur préférée. L'instance de base de données de lecteur envoie l'ensemble des adresses de mémoire tampon actuellement mises en cache à l'instance de base de données d'écriture sous la forme d'un filtre bloquant. Un filtre Bloom est une structure de données probabiliste économe en mémoire qui est utilisée pour vérifier si un élément fait partie d'un ensemble. L'utilisation d'un filtre Bloom empêche l'instance de base de données de lecteur d'envoyer à plusieurs reprises les mêmes adresses de mémoire tampon à l'instance de base de données d'écriture. Lorsque l'instance de base de données d'écriture reçoit le filtre Bloom, elle compare les blocs de son cache tampon et envoie les tampons fréquemment utilisés à l'instance de base de données de lecture. Par défaut, une mémoire tampon est considérée comme fréquemment utilisée si son nombre d'utilisations est supérieur à trois.
Le schéma suivant montre comment CCM synchronise le cache tampon de l'instance de base de données d'écriture avec l'instance de base de données de lecteur préférée.
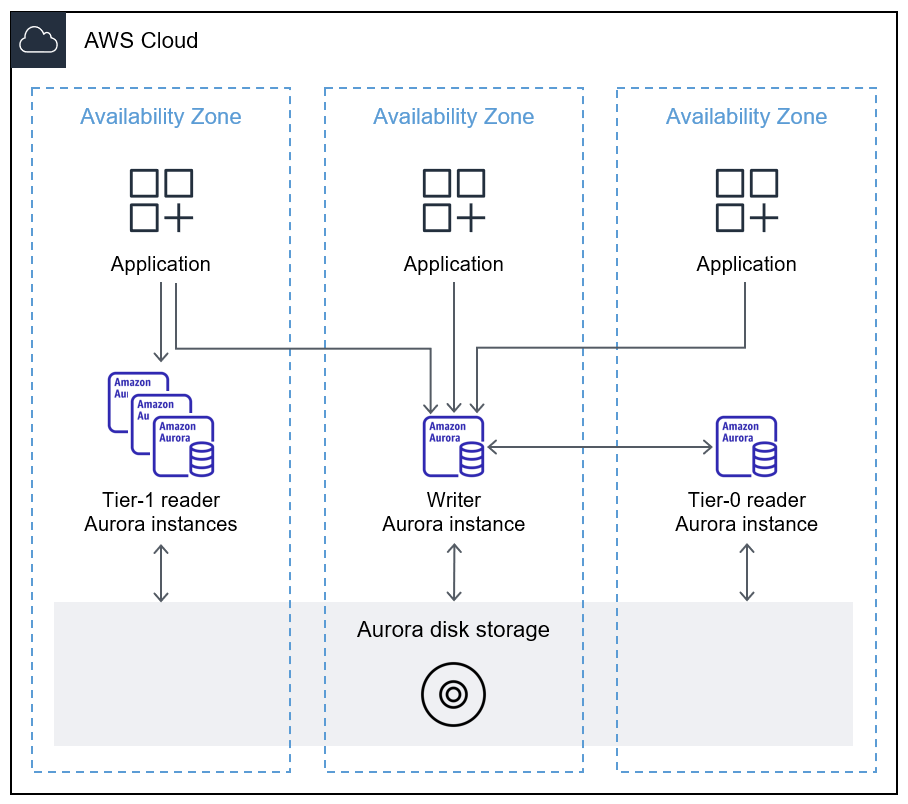
Pour plus d'informations sur CCM, voir Restauration rapide après basculement grâce à la gestion du cache de cluster pour Aurora PostgreSQL (documentation Aurora) et Introduction à la gestion du cache de cluster Aurora PostgreSQL
Limites
La fonction CCM présente les restrictions suivantes :
-
L'instance de base de données de lecteur doit avoir le même type et la même taille de classe d'instance de base de données de base de données que l'instance de base de données de rédacteur, par exemple
r5.2xlargeoudb.r5.xlarge. -
CCM n'est pas pris en charge pour les clusters de base de données Aurora PostgreSQL qui font partie des bases de données globales Aurora.
Cas d'utilisation pour la gestion des caches de clusters
Dans certains secteurs, tels que le commerce de détail, la banque et la finance, des retards de quelques millisecondes seulement peuvent entraîner des problèmes de performance des applications et entraîner une perte d'activité significative. Comme le CCM permet de restaurer les performances des applications et des bases de données en synchronisant en permanence le cache tampon de l'instance de base de données principale avec l'instance de sauvegarde préférée, il peut aider à prévenir les pertes des entreprises liées aux basculements.
