Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Groupes de disponibilité distribués
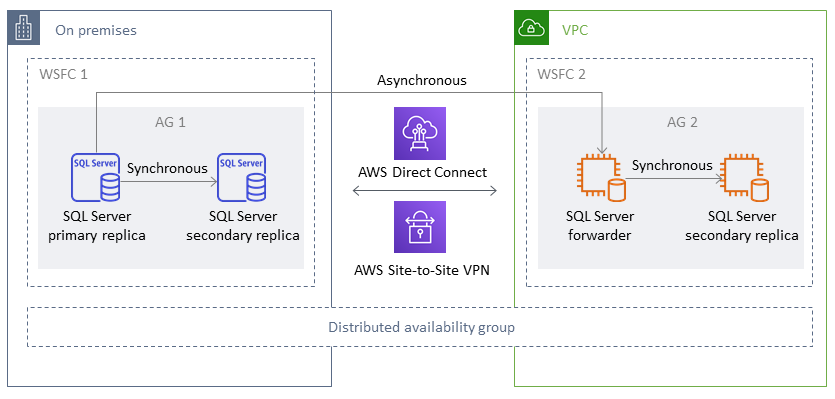
Un groupe de disponibilité distribué couvre deux groupes de disponibilité distincts. Vous pouvez le considérer comme un groupe de disponibilité composé de groupes de disponibilité. Les groupes de disponibilité sous-jacents sont configurés sur deux clusters WSFC différents. Les groupes de disponibilité qui font partie d'un groupe de disponibilité distribué n'ont pas besoin de partager le même emplacement. Ils peuvent être physiques ou virtuels, sur site ou dans le cloud public. Les groupes de disponibilité d'un groupe de disponibilité distribué ne doivent pas nécessairement exécuter la même version de SQL Server. L'instance de base de données cible peut exécuter une version de SQL Server ultérieure à celle de l'instance de base de données source.
Une architecture de groupe de disponibilité distribuée vous permet de réhéberger de manière flexible une instance ou une base de données SQL Server critique. AWS Il fournit une solution hybride pour le levage et le déplacement (ou le levage et la transformation) de vos bases de données SQL Server critiques AWS.
L'utilisation d'une architecture de groupe de disponibilité distribuée est plus efficace que l'extension de clusters WFSC locaux existants à. AWS Les données sont transférées uniquement du serveur principal sur site vers l'une des AWS répliques (le redirecteur). Le redirecteur est chargé d'envoyer les données à d'autres répliques de lecture secondaires. AWS
Dans le schéma suivant, le premier cluster WSFC (WSFC 1) est hébergé sur site et possède un groupe de disponibilité sur site (AG 1). Le second cluster WSFC (WSFC 2) est hébergé sur AWS et possède un groupe de AWS disponibilité (AG 2). Direct Connect
Note
À un moment donné, il n'existe qu'une seule base de données disponible pour les opérations d'écriture. Vous pouvez utiliser les répliques secondaires restantes pour les opérations de lecture. Pour augmenter vos charges de travail de lecture, vous pouvez ajouter d'autres répliques de lecture dans plusieurs zones de disponibilité sur. AWS
Pour plus d'informations sur les groupes de disponibilité distribués, voir :
-
Comment concevoir une solution Microsoft SQL Server hybride à l'aide de groupes de disponibilité distribués
sur le blog AWS Database -
Migrez SQL Server vers des AWS groupes de disponibilité distribués sur le site Web des AWS directives prescriptives
