Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utiliser la mise en cache pour réduire la demande de base de données
Présentation
Vous pouvez utiliser la mise en cache comme stratégie efficace pour réduire les coûts pour votre. NETapplications. De nombreuses applications utilisent des bases de données principales, telles que SQL Server, lorsqu'elles nécessitent un accès fréquent aux données. Le coût de maintenance de ces services principaux pour répondre à la demande peut être élevé, mais vous pouvez utiliser une stratégie de mise en cache efficace pour réduire la charge sur les bases de données principales en réduisant les exigences de dimensionnement et de dimensionnement. Cela peut vous aider à réduire les coûts et à améliorer les performances de vos applications.
La mise en cache est une technique utile pour réduire les coûts liés aux charges de travail lourdes en lecture qui utilisent des ressources plus coûteuses telles SQL que le serveur. Il est important d'utiliser la bonne technique adaptée à votre charge de travail. Par exemple, la mise en cache locale n'est pas évolutive et vous oblige à maintenir un cache local pour chaque instance d'une application. Vous devez évaluer l'impact sur les performances par rapport aux coûts potentiels, afin que le moindre coût de la source de données sous-jacente compense les coûts supplémentaires liés au mécanisme de mise en cache.
Impact sur les coûts
SQLLe serveur vous oblige à prendre en compte les demandes de lecture lors du dimensionnement de votre base de données. Cela peut avoir une incidence sur les coûts, car vous devrez peut-être introduire des répliques de lecture pour faire face à la charge. Si vous utilisez des répliques de lecture, il est important de comprendre qu'elles ne sont disponibles que sur l'édition SQL Server Enterprise. Cette édition nécessite une licence plus onéreuse que l'édition SQL Server Standard.
Le schéma suivant est conçu pour vous aider à comprendre l'efficacité de la mise en cache. Il montre Amazon RDS for SQL Server avec quatre nœuds db.m4.2xlarge exécutant l'édition Server Enterprise. SQL Il est déployé dans une configuration multi-AZ avec une seule réplique en lecture. Le trafic de lecture exclusif (par exemple, SELECT les requêtes) est dirigé vers les répliques de lecture. En comparaison, Amazon DynamoDB utilise un cluster DynamoDB Accelerator () r4.2xlarge à deux nœuds. DAX
Le graphique suivant montre les résultats de la suppression du besoin de répliques de lecture dédiées qui gèrent un trafic de lecture élevé.
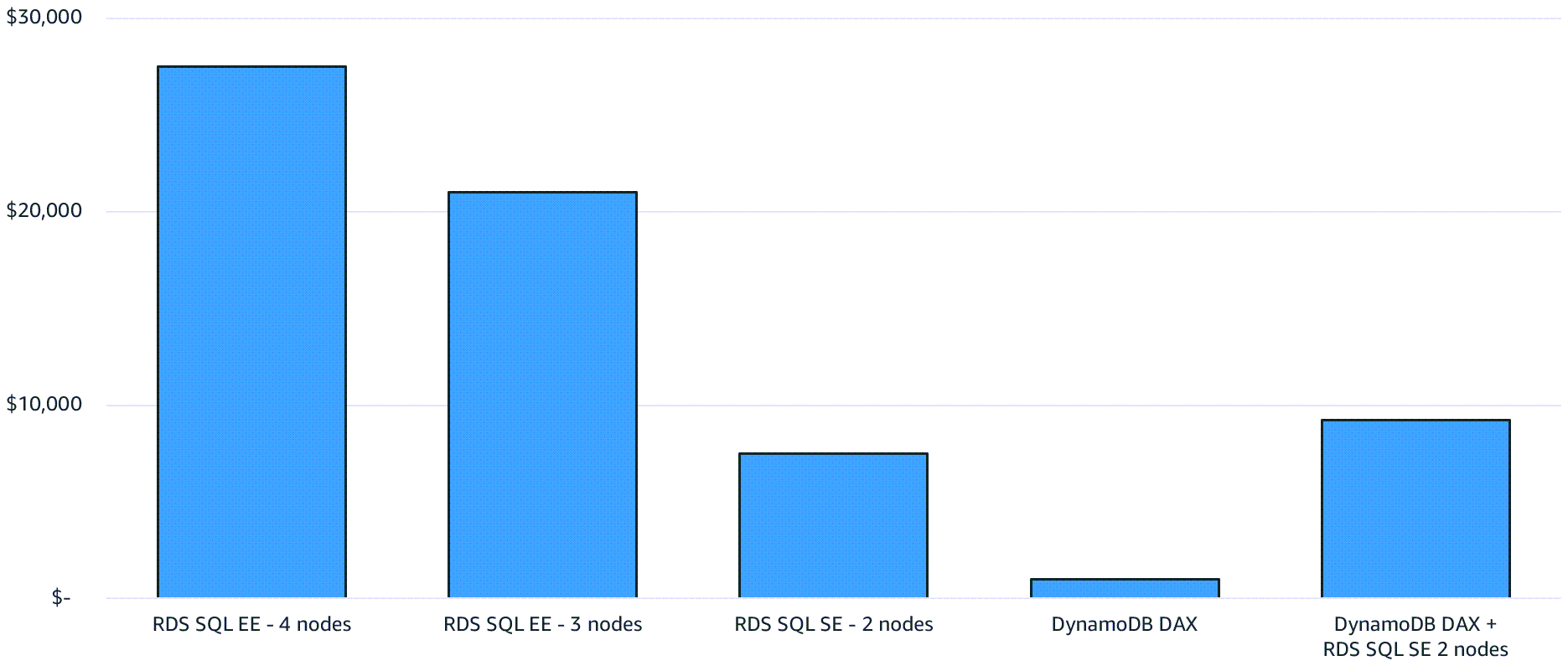
Vous pouvez réaliser d'importantes économies en utilisant la mise en cache locale sans répliques en lecture ou en l'introduisant côte à DAX côte avec SQL Server on Amazon en RDS tant que couche de mise en cache. Cette couche se décharge du SQL serveur et réduit la taille du SQL serveur requise pour exécuter la base de données.
Recommandations d'optimisation des coûts
Mise en cache locale
La mise en cache locale est l'une des méthodes les plus couramment utilisées pour mettre en cache le contenu des applications hébergées à la fois dans des environnements sur site ou dans le cloud. Cela s'explique par le fait qu'il est relativement facile et intuitif à mettre en œuvre. La mise en cache locale consiste à récupérer le contenu d'une base de données ou d'une autre source et à le mettre en cache localement en mémoire ou sur disque pour un accès plus rapide. Cette approche, bien que facile à mettre en œuvre, n'est pas idéale pour certains cas d'utilisation. Cela inclut, par exemple, les cas d'utilisation où le contenu de la mise en cache doit persister dans le temps, par exemple pour préserver l'état de l'application ou l'état de l'utilisateur. Un autre cas d'utilisation est celui où le contenu mis en cache doit être accessible à partir d'autres instances d'application.
Le schéma ci-dessous illustre un cluster de SQL serveurs à haute disponibilité avec quatre nœuds et deux répliques en lecture.
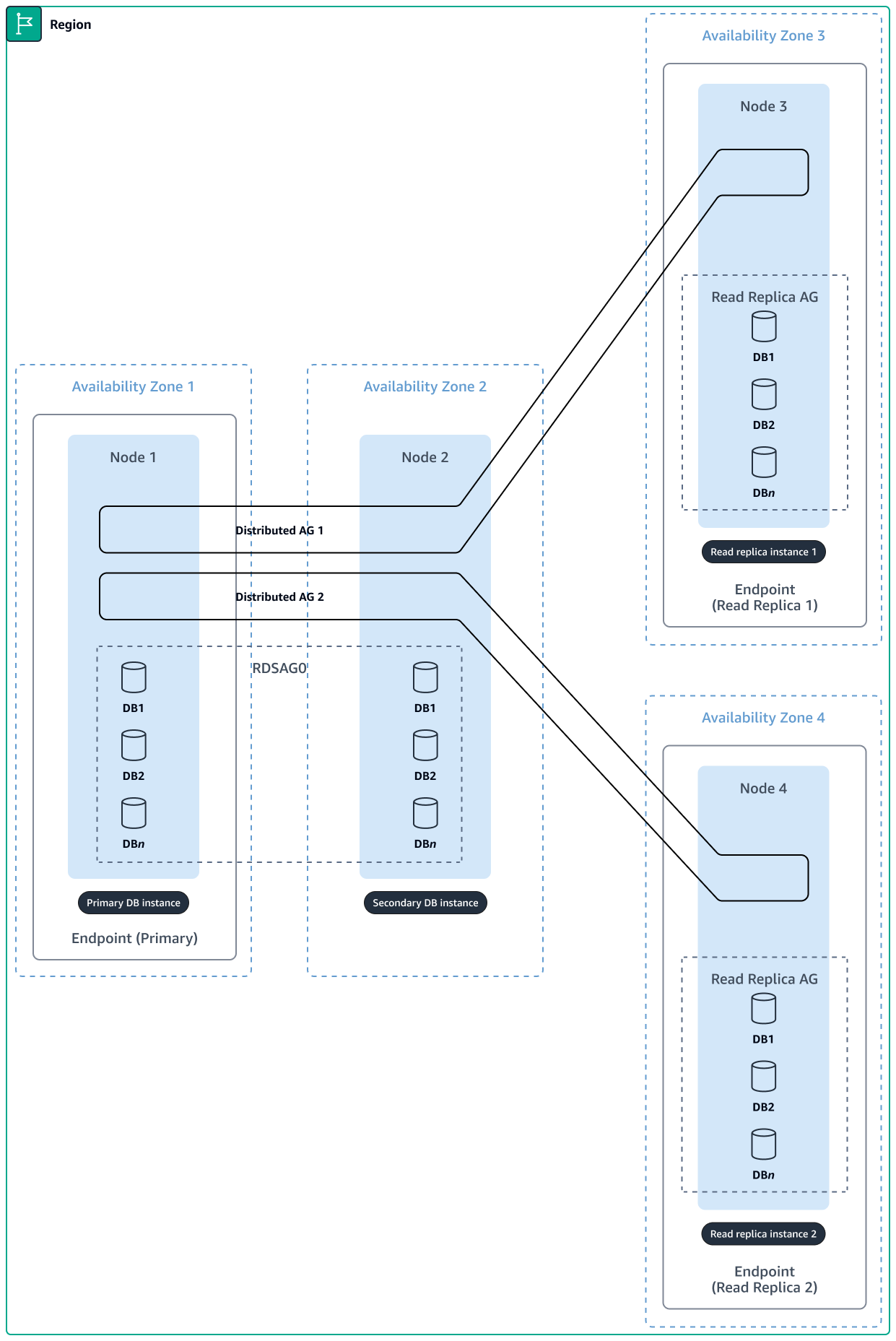
Avec la mise en cache locale, vous devrez peut-être équilibrer la charge du trafic entre plusieurs EC2 instances. Chaque instance doit gérer son propre cache local. Si le cache stocke des informations dynamiques, des validations régulières doivent être effectuées dans la base de données, et les utilisateurs devront peut-être être redirigés vers la même instance pour chaque demande suivante (session persistante). Cela représente un défi lorsque vous essayez de faire évoluer les applications, car certaines instances peuvent être surutilisées, tandis que d'autres sont sous-utilisées en raison de la répartition inégale du trafic.
Vous pouvez utiliser la mise en cache locale, en mémoire ou via le stockage local, pour. NETapplications. Pour ce faire, vous pouvez ajouter des fonctionnalités permettant soit de stocker des objets sur disque et de les récupérer si nécessaire, soit d'interroger des données dans la base de données et de les conserver en mémoire. Pour effectuer une mise en cache locale en mémoire et sur le stockage local des données d'un SQL serveur en C#, par exemple, vous pouvez utiliser une combinaison de MemoryCache bibliothèques et. LiteDB MemoryCachefournit une mise en cache en mémoire, tandis qu'LiteDBil s'agit d'une SQL base de données intégrée sans disque rapide et légère.
Pour effectuer une mise en cache en mémoire, utilisez le. NETBibliothèqueSystem.Runtime.MemoryCache. L'exemple de code suivant montre comment utiliser la System.Runtime.Caching.MemoryCache classe pour mettre en cache des données en mémoire. Cette classe permet de stocker temporairement des données dans la mémoire de l'application. Cela peut contribuer à améliorer les performances d'une application en réduisant le besoin de récupérer des données à partir d'une ressource plus coûteuse, telle qu'une base de données ou unAPI.
Voici comment fonctionne le code :
-
Une instance statique privée de
MemoryCachenamed_memoryCacheest créée. Le cache reçoit un nom (dataCache) pour l'identifier. Ensuite, le cache stocke et récupère les données. -
La
GetDataméthode est une méthode générique qui prend deux arguments : unestringclé et unFunc<T>délégué appelégetData. La clé est utilisée pour identifier les données mises en cache, tandis que legetDatadélégué représente la logique de récupération des données qui est exécutée lorsque les données ne sont pas présentes dans le cache. -
La méthode vérifie d'abord si les données sont présentes dans le cache à l'aide de la
_memoryCache.Contains(key)méthode. Si les données se trouvent dans le cache, la méthode les récupère en utilisant_memoryCache.Get(key)et les convertit dans le type attendu T. -
Si les données ne sont pas dans le cache, la méthode appelle le
getDatadélégué pour récupérer les données. Ensuite, il ajoute les données au cache en utilisant_memoryCache.Add(key, data, DateTimeOffset.Now.AddMinutes(10)). Cet appel indique que l'entrée du cache doit expirer au bout de 10 minutes, date à laquelle les données sont automatiquement supprimées du cache. -
La
ClearCacheméthode prend unestringclé comme argument et supprime les données associées à cette clé du cache en utilisant_memoryCache.Remove(key).
using System; using System.Runtime.Caching; public class InMemoryCache { private static MemoryCache _memoryCache = new MemoryCache("dataCache"); public static T GetData<T>(string key, Func<T> getData) { if (_memoryCache.Contains(key)) { return (T)_memoryCache.Get(key); } T data = getData(); _memoryCache.Add(key, data, DateTimeOffset.Now.AddMinutes(10)); return data; } public static void ClearCache(string key) { _memoryCache.Remove(key); } }
Vous pouvez utiliser le code suivant :
public class Program { public static void Main() { string cacheKey = "sample_data"; Func<string> getSampleData = () => { // Replace this with your data retrieval logic return "Sample data"; }; string data = InMemoryCache.GetData(cacheKey, getSampleData); Console.WriteLine("Data: " + data); } }
L'exemple suivant montre comment utiliser LiteDBLocalStorageCache classe contient les principales fonctions de gestion du cache.
using System; using LiteDB; public class LocalStorageCache { private static string _liteDbPath = @"Filename=LocalCache.db"; public static T GetData<T>(string key, Func<T> getData) { using (var db = new LiteDatabase(_liteDbPath)) { var collection = db.GetCollection<T>("cache"); var item = collection.FindOne(Query.EQ("_id", key)); if (item != null) { return item; } } T data = getData(); using (var db = new LiteDatabase(_liteDbPath)) { var collection = db.GetCollection<T>("cache"); collection.Upsert(new BsonValue(key), data); } return data; } public static void ClearCache(string key) { using (var db = new LiteDatabase(_liteDbPath)) { var collection = db.GetCollection("cache"); collection.Delete(key); } } } public class Program { public static void Main() { string cacheKey = "sample_data"; Func<string> getSampleData = () => { // Replace this with your data retrieval logic return "Sample data"; }; string data = LocalStorageCache.GetData(cacheKey, getSampleData); Console.WriteLine("Data: " + data); } }
Si vous disposez d'un cache statique ou de fichiers statiques qui ne changent pas fréquemment, vous pouvez également stocker ces fichiers dans le stockage d'objets Amazon Simple Storage Service (Amazon S3). L'application peut récupérer le fichier de cache statique au démarrage pour l'utiliser localement. Pour plus de détails sur la façon de récupérer des fichiers depuis Amazon S3 à l'aide de. NET, consultez la section Téléchargement d'objets dans la documentation Amazon S3.
Mise en cache avec DAX
Vous pouvez utiliser une couche de mise en cache qui peut être partagée entre toutes les instances d'application. DynamoDB Accelerator DAX () est un cache en mémoire hautement disponible et entièrement géré pour DynamoDB qui peut décupler les performances. Vous pouvez l'utiliser DAX pour réduire les coûts en réduisant le besoin de surprovisionner les unités de capacité de lecture dans les tables DynamoDB. Cela est particulièrement utile pour les charges de travail qui sont lourdes en lecture et nécessitent des lectures répétées pour des clés individuelles.
DynamoDB est facturé à la demande ou avec une capacité allouée, de sorte que le nombre de lectures et d'écritures par mois contribue au coût. Si vous avez de lourdes charges de travail en lecture, les DAX clusters peuvent contribuer à réduire les coûts en réduisant le nombre de lectures sur vos tables DynamoDB. Pour obtenir des instructions sur la configurationDAX, consultez la section Accélération en mémoire avec DynamoDB Accelerator DAX () dans la documentation DynamoDB. Pour plus d'informations sur. NETintégration des applications, regardez Intégrer Amazon DAX DynamoDB dans votre. ASP NETCandidature
Ressources supplémentaires
-
Accélération en mémoire avec DynamoDB Accelerator () DAX - Amazon DynamoDB (documentation DynamoDB)
-
Intégrer Amazon DAX DynamoDB dans votre. ASP NET
Demande (YouTube) -
Téléchargement d'objets (documentation Amazon S3)
