Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Créez un pipeline de données pour ingérer, transformer et analyser les données Google Analytics à l'aide du kit de AWS DataOps développement
Anton Kukushkin et Rudy Puig, Amazon Web Services
Récapitulatif
Ce modèle décrit comment créer un pipeline de données pour ingérer, transformer et analyser les données de Google Analytics à l'aide du kit de AWS DataOps développement (AWS DDK) et d'autres outils. Services AWS Le AWS DDK est un framework de développement open source qui vous aide à créer des flux de travail de données et une architecture de données moderne. AWS L'un des principaux objectifs du AWS DDK est de vous faire économiser le temps et les efforts généralement consacrés aux tâches de pipeline de données exigeantes en main-d'œuvre, telles que l'orchestration de pipelines, la création d'infrastructures et la création de l' DevOps infrastructure sous-jacente. Vous pouvez déléguer ces tâches fastidieuses à AWS DDK afin de pouvoir vous concentrer sur l'écriture de code et d'autres activités à forte valeur ajoutée.
Conditions préalables et limitations
Prérequis
Versions du produit
Python 3.7 ou version ultérieure
pip 9.0.3 ou version ultérieure
Architecture
Pile technologique
Amazon AppFlow
Amazon Athena
Amazon CloudWatch
Amazon EventBridge
Amazon Simple Storage Service (Amazon S3)
Amazon Simple Queue Service (Amazon SQS)
AWS DataOps Kit de développement (AWS DDK)
AWS Lambda
Architecture cible
Le schéma suivant montre le processus piloté par les événements qui ingère, transforme et analyse les données de Google Analytics.
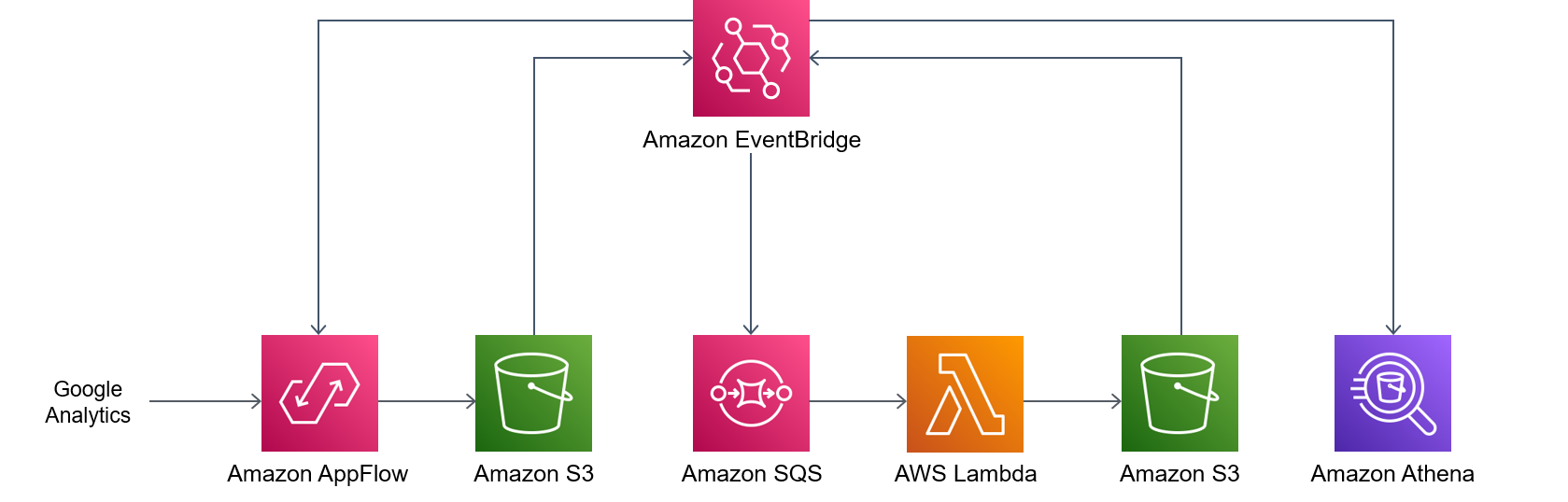
Le schéma suivant illustre le flux de travail suivant :
Une règle relative aux événements CloudWatch planifiés d'Amazon invoque Amazon AppFlow.
Amazon AppFlow ingère les données de Google Analytics dans un compartiment S3.
Une fois les données ingérées par le compartiment S3, les notifications d'événements EventBridge sont générées, capturées par une règle CloudWatch Events, puis placées dans une file d'attente Amazon SQS.
Une fonction Lambda consomme les événements de la file d'attente Amazon SQS, lit les objets S3 respectifs, transforme les objets au format Apache Parquet, écrit les objets transformés dans le compartiment S3, puis crée ou met à jour AWS Glue Data Catalog la définition de la table.
Une requête Athena s'exécute sur la table.
Outils
AWS outils
Amazon AppFlow est un service d'intégration entièrement géré qui vous permet d'échanger des données en toute sécurité entre des applications SaaS (Software as a Service).
Amazon Athena est un service de requête interactif qui vous permet d'analyser les données directement dans Amazon S3 à l'aide du SQL standard.
Amazon vous CloudWatch aide à surveiller les indicateurs de vos AWS ressources et des applications que vous utilisez AWS en temps réel.
Amazon EventBridge est un service de bus d'événements sans serveur qui vous permet de connecter vos applications à des données en temps réel provenant de diverses sources. Par exemple, AWS Lambda des fonctions, des points de terminaison d'appel HTTP utilisant des destinations d'API ou des bus d'événements dans d'autres. Comptes AWS
Amazon Simple Storage Service (Amazon S3) est un service de stockage d'objets basé sur le cloud qui vous permet de stocker, de protéger et de récupérer n'importe quel volume de données.
Amazon Simple Queue Service (Amazon SQS) fournit une file d'attente hébergée sécurisée, durable et disponible qui vous permet d'intégrer et de dissocier les systèmes et composants logiciels distribués.
AWS Lambda est un service de calcul qui vous aide à exécuter du code sans avoir à allouer ni à gérer des serveurs. Il exécute votre code uniquement lorsque cela est nécessaire et évolue automatiquement, de sorte que vous ne payez que pour le temps de calcul que vous utilisez.
AWS Cloud Development Kit (AWS CDK)est un framework permettant de définir l'infrastructure cloud dans le code et de la provisionner via AWS CloudFormation celle-ci.
AWS DataOps Le kit de développement (AWS DDK)
est un framework de développement open source qui vous aide à créer des flux de travail de données et une architecture de données moderne. AWS
Code
Le code de ce modèle est disponible dans le kit de GitHub AWS DataOps développement (AWS DDK)
Épopées
| Tâche | Description | Compétences requises |
|---|---|---|
Clonez le code source. | Pour cloner le code source, exécutez la commande suivante :
| DevOps ingénieur |
Créez un environnement virtuel. | Accédez au répertoire du code source, puis exécutez la commande suivante pour créer un environnement virtuel :
| DevOps ingénieur |
Installez les dépendances. | Pour activer l'environnement virtuel et installer les dépendances, exécutez la commande suivante :
| DevOps ingénieur |
| Tâche | Description | Compétences requises |
|---|---|---|
Démarrez l'environnement. |
| DevOps ingénieur |
Déployez les données. | Pour déployer le pipeline de données, exécutez la | DevOps ingénieur |
| Tâche | Description | Compétences requises |
|---|---|---|
Validez l'état de la pile. |
| DevOps ingénieur |
Résolution des problèmes
| Problème | Solution |
|---|---|
Le déploiement échoue lors de la création d'une | Confirmez que vous avez créé un AppFlow connecteur Amazon pour Google Analytics et que vous l'avez nommé Pour obtenir des instructions, consultez Google Analytics dans la AppFlow documentation Amazon. |
Ressources connexes
Informations supplémentaires
AWS Les pipelines de données DDK sont composés d'une ou de plusieurs étapes. Dans les exemples de code suivants, vous les utilisez AppFlowIngestionStage pour ingérer des données provenant de Google Analytics, SqsToLambdaStage pour gérer la transformation des données et AthenaSQLStage pour exécuter la requête Athena.
Tout d'abord, les étapes de transformation et d'ingestion des données sont créées, comme le montre l'exemple de code suivant :
appflow_stage = AppFlowIngestionStage( self, id="appflow-stage", flow_name=flow.flow_name, ) sqs_lambda_stage = SqsToLambdaStage( self, id="lambda-stage", lambda_function_props={ "code": Code.from_asset("./ddk_app/lambda_handlers"), "handler": "handler.lambda_handler", "layers": [ LayerVersion.from_layer_version_arn( self, id="layer", layer_version_arn=f"arn:aws:lambda:{self.region}:336392948345:layer:AWSDataWrangler-Python39:1", ) ], "runtime": Runtime.PYTHON_3_9, }, ) # Grant lambda function S3 read & write permissions bucket.grant_read_write(sqs_lambda_stage.function) # Grant Glue database & table permissions sqs_lambda_stage.function.add_to_role_policy( self._get_glue_db_iam_policy(database_name=database.database_name) ) athena_stage = AthenaSQLStage( self, id="athena-sql", query_string=[ ( "SELECT year, month, day, device, count(user_count) as cnt " f"FROM {database.database_name}.ga_sample " "GROUP BY year, month, day, device " "ORDER BY cnt DESC " "LIMIT 10; " ) ], output_location=Location( bucket_name=bucket.bucket_name, object_key="query-results/" ), additional_role_policy_statements=[ self._get_glue_db_iam_policy(database_name=database.database_name) ], )
Ensuite, la DataPipeline construction est utilisée pour « relier » les étapes entre elles en utilisant des EventBridge règles, comme le montre l'exemple de code suivant :
( DataPipeline(self, id="ingestion-pipeline") .add_stage( stage=appflow_stage, override_rule=Rule( self, "schedule-rule", schedule=Schedule.rate(Duration.hours(1)), targets=appflow_stage.targets, ), ) .add_stage( stage=sqs_lambda_stage, # By default, AppFlowIngestionStage stage emits an event after the flow run finishes successfully # Override rule below changes that behavior to call the the stage when data lands in the bucket instead override_rule=Rule( self, "s3-object-created-rule", event_pattern=EventPattern( source=["aws.s3"], detail={ "bucket": {"name": [bucket.bucket_name]}, "object": {"key": [{"prefix": "ga-data"}]}, }, detail_type=["Object Created"], ), targets=sqs_lambda_stage.targets, ), ) .add_stage(stage=athena_stage) )
Pour d'autres exemples de code, consultez le GitHub référentiel Analyse des données Google Analytics avec Amazon AppFlow, Amazon Athena et AWS DataOps le référentiel Development Kit
