Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Optimisation des fonctions définies par l'utilisateur
Les fonctions définies par l'utilisateur (UDFs) et RDD.map IN PySpark dégradent souvent les performances de manière significative. Cela est dû à la surcharge requise pour représenter avec précision votre code Python dans l'implémentation Scala sous-jacente de Spark.
Le schéma suivant montre l'architecture des PySpark tâches. Lorsque vous l'utilisez PySpark, le pilote Spark utilise la bibliothèque Py4j pour appeler des méthodes Java depuis Python. Lorsque vous appelez Spark SQL ou des fonctions DataFrame intégrées, il y a peu de différence de performance entre Python et Scala, car les fonctions s'exécutent sur chaque exécuteur à JVM l'aide d'un plan d'exécution optimisé.
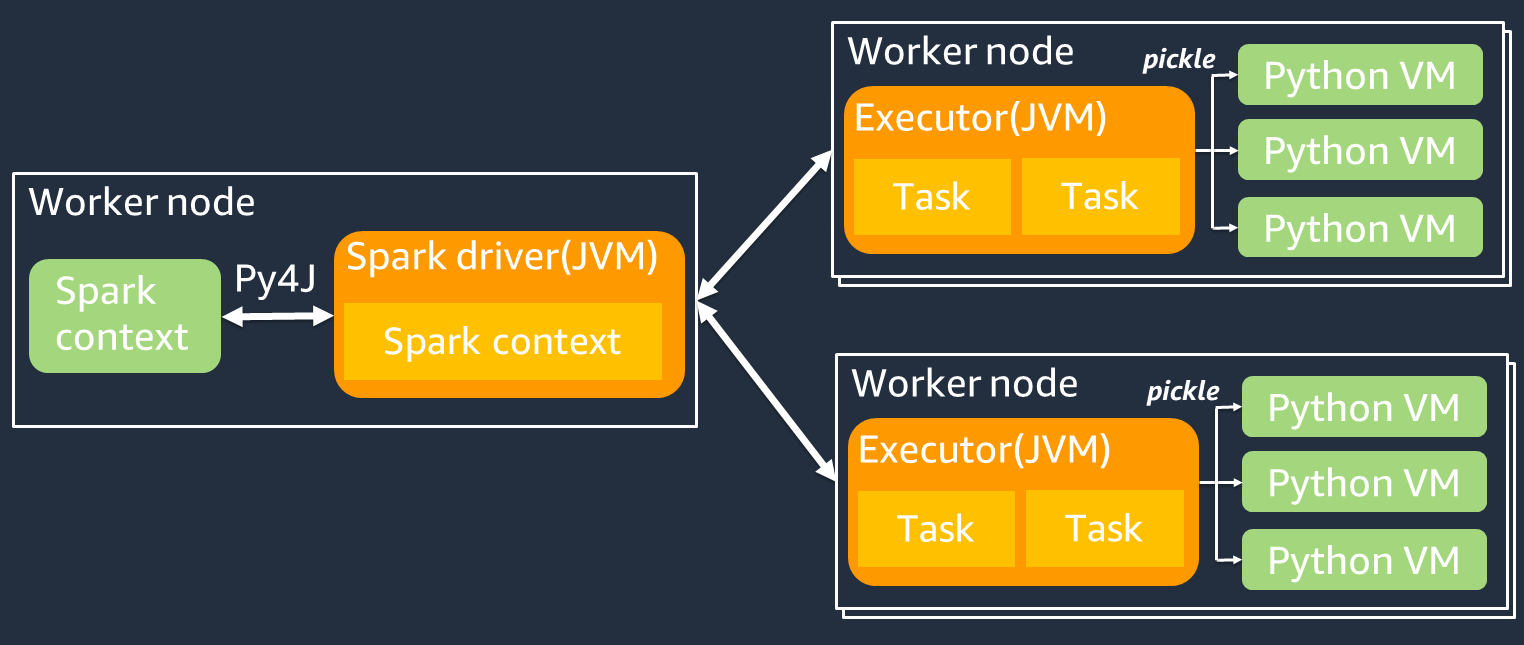
Si vous utilisez votre propre logique Python, telle que usingmap/ mapPartitions/ udf, la tâche s'exécutera dans un environnement d'exécution Python. La gestion de deux environnements entraîne des frais généraux. En outre, vos données en mémoire doivent être transformées pour être utilisées par les fonctions intégrées de l'environnement JVM d'exécution. Pickle est un format de sérialisation utilisé par défaut pour l'échange entre les environnements d'exécution et JVM Python. Cependant, le coût de cette sérialisation et de cette désérialisation étant très élevé, les UDFs écrits en Java ou en Scala sont plus rapides que Python. UDFs
Pour éviter les surcharges liées à la sérialisation et à la désérialisation PySpark, tenez compte des points suivants :
-
Utilisez les SQL fonctions Spark intégrées : envisagez de remplacer votre propre fonction UDF ou votre fonction cartographique par Spark SQL ou des fonctions DataFrame intégrées. Lors de l'exécution de Spark SQL ou de fonctions DataFrame intégrées, il y a peu de différence de performance entre Python et Scala, car les tâches sont gérées par chaque exécuteur. JVM
-
UDFsImplémenter en Scala ou Java — Envisagez d'utiliser un UDF fichier écrit en Java ou en Scala, car ils s'exécutent sur le. JVM
-
Utiliser la technologie basée sur Apache Arrow UDFs pour les charges de travail vectorisées : pensez à utiliser la technologie basée sur Arrow. UDFs Cette fonctionnalité est également connue sous le nom de vectorisation UDF (PandasUDF). Apache Arrow
est un format de données en mémoire indépendant du langage qui AWS Glue peut être utilisé pour transférer efficacement des données entre et JVM des processus Python. C'est actuellement le plus avantageux pour les utilisateurs de Python qui travaillent avec des pandas ou NumPy des données. La flèche est un format colonnaire (vectorisé). Son utilisation n'est pas automatique et peut nécessiter quelques modifications mineures de la configuration ou du code pour en tirer pleinement parti et garantir la compatibilité. Pour plus de détails et pour connaître les limites, voir Apache Arrow dans PySpark
. L'exemple suivant compare un incrémental de base UDF en Python standard, en tant que vectorisé et en UDF Spark. SQL
Python standard UDF
Le temps d'exemple est de 3,20 (sec).
Exemple de code
# DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # UDF Example def plus(a,b): return a+b spark.udf.register("plus",plus) df.selectExpr("count(plus(a,b))").collect()
Plan d'exécution
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#124)]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#580] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#124)]) +- Project [pythonUDF0#124] +- BatchEvalPython [plus(a#116L, b#117L)], [pythonUDF0#124] +- Project [id#114L AS a#116L, id#114L AS b#117L] +- Range (0, 10000000, step=1, splits=16)
Vectorisé UDF
Le temps d'exemple est de 0,59 (sec).
Le vectorisé UDF est 5 fois plus rapide que l'exemple précédentUDF. Vous pouvez voir ArrowEvalPython que cette application est vectorisée par Apache Arrow. Physical Plan Pour activer VectorizedUDF, vous devez le spécifier spark.sql.execution.arrow.pyspark.enabled = true dans votre code.
Exemple de code
# Vectorized UDF from pyspark.sql.types import LongType from pyspark.sql.functions import count, pandas_udf # Enable Apache Arrow Support spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true") # DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # Annotate pandas_udf to use Vectorized UDF @pandas_udf(LongType()) def pandas_plus(a,b): return a+b spark.udf.register("pandas_plus",pandas_plus) df.selectExpr("count(pandas_plus(a,b))").collect()
Plan d'exécution
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#1082L)], output=[count(pandas_plus(a, b))#1080L]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#5985] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#1082L)], output=[count#1084L]) +- Project [pythonUDF0#1082L] +- ArrowEvalPython [pandas_plus(a#1074L, b#1075L)], [pythonUDF0#1082L], 200 +- Project [id#1072L AS a#1074L, id#1072L AS b#1075L] +- Range (0, 10000000, step=1, splits=16)
Étincelle SQL
Le temps d'exemple est de 0,087 (sec).
Spark SQL est beaucoup plus rapide que VectorizedUDF, car les tâches sont exécutées sur chaque exécuteur sans environnement JVM d'exécution Python. Si vous pouvez le remplacer par une fonction intégrée, nous vous recommandons de le faire. UDF
Exemple de code
df.createOrReplaceTempView("test") spark.sql("select count(a+b) from test").collect()
Utiliser les pandas pour les mégadonnées
Si vous connaissez déjà les pandas et que
