Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Réduisez le volume de données numérisées
Pour commencer, pensez à charger uniquement les données dont vous avez besoin. Vous pouvez améliorer les performances simplement en réduisant la quantité de données chargées dans votre cluster Spark pour chaque source de données. Pour évaluer si cette approche est appropriée, utilisez les mesures suivantes.
Vous pouvez vérifier les octets lus depuis Amazon S3 dans CloudWatchles métriques et obtenir plus de détails dans l'interface utilisateur de Spark, comme décrit dans la section Spark UI.
CloudWatch métriques
Vous pouvez voir la taille de lecture approximative d'Amazon S3 dans ETLData Movement (Bytes). Cette métrique indique le nombre d'octets lus depuis Amazon S3 par tous les exécuteurs depuis le rapport précédent. Vous pouvez l'utiliser pour surveiller le mouvement ETL des données depuis Amazon S3 et comparer les taux de lecture aux taux d'ingestion provenant de sources de données externes.
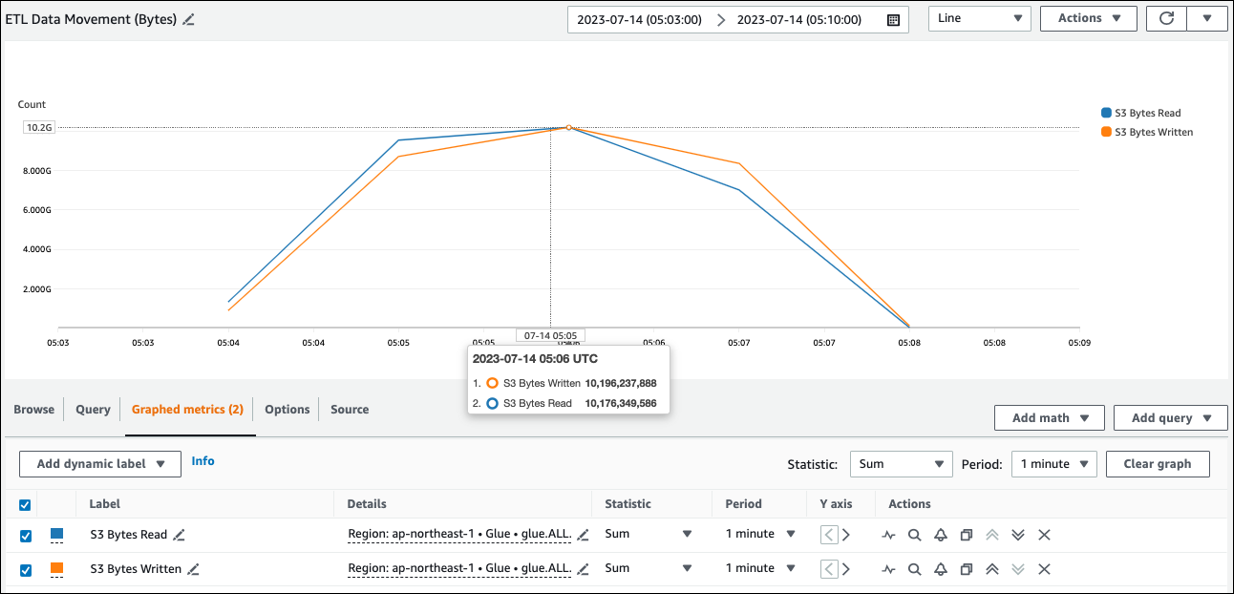
Si vous observez un point de données de lecture de S3 octets plus important que prévu, envisagez les solutions suivantes.
Interface utilisateur Spark
Dans l'onglet Stage de l'interface utilisateur AWS Glue de Spark, vous pouvez voir la taille de l'entrée et de la sortie. Dans l'exemple suivant, l'étape 2 lit 47,4 GiB en entrée et 47,7 GiB en sortie, tandis que l'étape 5 lit 61,2 MiB en entrée et 56,6 MiB en sortie.

Lorsque vous utilisez le Spark SQL ou DataFrame des approches dans le cadre de votre AWS Glue travail, l' ataFrame onglet SQL/D affiche davantage de statistiques sur ces étapes. Dans ce cas, l'étape 2 indique le nombre de fichiers lus : 430, la taille des fichiers lus : 47,4 GiB et le nombre de lignes de sortie : 160 796 570.
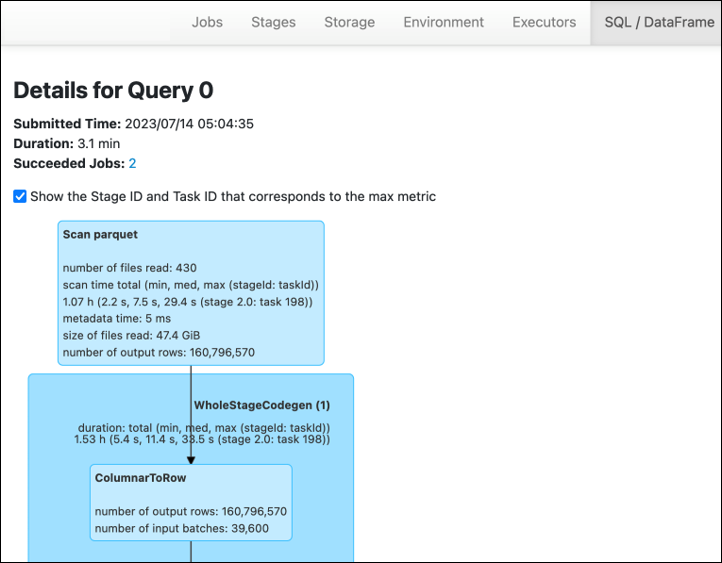
Si vous constatez une différence de taille importante entre les données que vous lisez et celles que vous utilisez, essayez les solutions suivantes.
Amazon S3
Pour réduire la quantité de données chargées dans votre tâche lors de la lecture depuis Amazon S3, tenez compte de la taille du fichier, de la compression, du format de fichier et de la disposition des fichiers (partitions) de votre ensemble de données. AWS Glue car les tâches Spark sont souvent utilisées pour les ETL données brutes, mais pour un traitement distribué efficace, vous devez inspecter les fonctionnalités du format de votre source de données.
-
Taille du fichier — Nous recommandons de maintenir la taille du fichier des entrées et des sorties dans une fourchette modérée (par exemple, 128 Mo). Les fichiers trop petits ou trop volumineux peuvent entraîner des problèmes.
Un grand nombre de petits fichiers sont à l'origine des problèmes suivants :
-
Charge d'E/S réseau importante sur Amazon S3 en raison de la surcharge requise pour effectuer des demandes (telles que
ListGet, ouHead) pour de nombreux objets (par rapport à quelques objets qui stockent la même quantité de données). -
Charge d'E/S et de traitement importante sur le pilote Spark, ce qui générera de nombreuses partitions et tâches et entraînera un parallélisme excessif.
En revanche, si le type de fichier n'est pas divisible (par exemple gzip) et que les fichiers sont trop volumineux, l'application Spark doit attendre qu'une seule tâche ait terminé de lire le fichier dans son intégralité.
Pour réduire le parallélisme excessif lié à la création d'une tâche Apache Spark pour chaque petit fichier, utilisez le regroupement de fichiers pour. DynamicFrames Cette approche réduit le risque d'une OOM exception de la part du pilote Spark. Pour configurer le regroupement de fichiers, définissez les
groupSizeparamètresgroupFileset. L'exemple de code suivant utilise le AWS Glue DynamicFrame API dans un ETL script avec ces paramètres.dyf = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input-s3-path/"], 'recurse':True, 'groupFiles': 'inPartition', 'groupSize': '1048576'}, format="json") -
-
Compression — Si vos objets S3 se chiffrent en centaines de mégaoctets, pensez à les compresser. Il existe différents formats de compression, que l'on peut globalement classer en deux types :
-
Les formats de compression non fractionnables tels que gzip nécessitent que l'intégralité du fichier soit décompressée par un seul utilisateur.
-
Les formats de compression séparables, tels que bzip2 ou LZO (indexé), permettent une décompression partielle d'un fichier, qui peut être parallélisé.
Pour Spark (et les autres moteurs de traitement distribué courants), vous allez diviser votre fichier de données source en fragments que votre moteur peut traiter en parallèle. Ces unités sont souvent appelées divisions. Une fois que vos données sont dans un format séparable, les AWS Glue lecteurs optimisés peuvent récupérer les divisions d'un objet S3 en offrant la
Rangepossibilité de neGetObjectAPI récupérer que des blocs spécifiques. Examinez le schéma suivant pour voir comment cela fonctionnerait dans la pratique.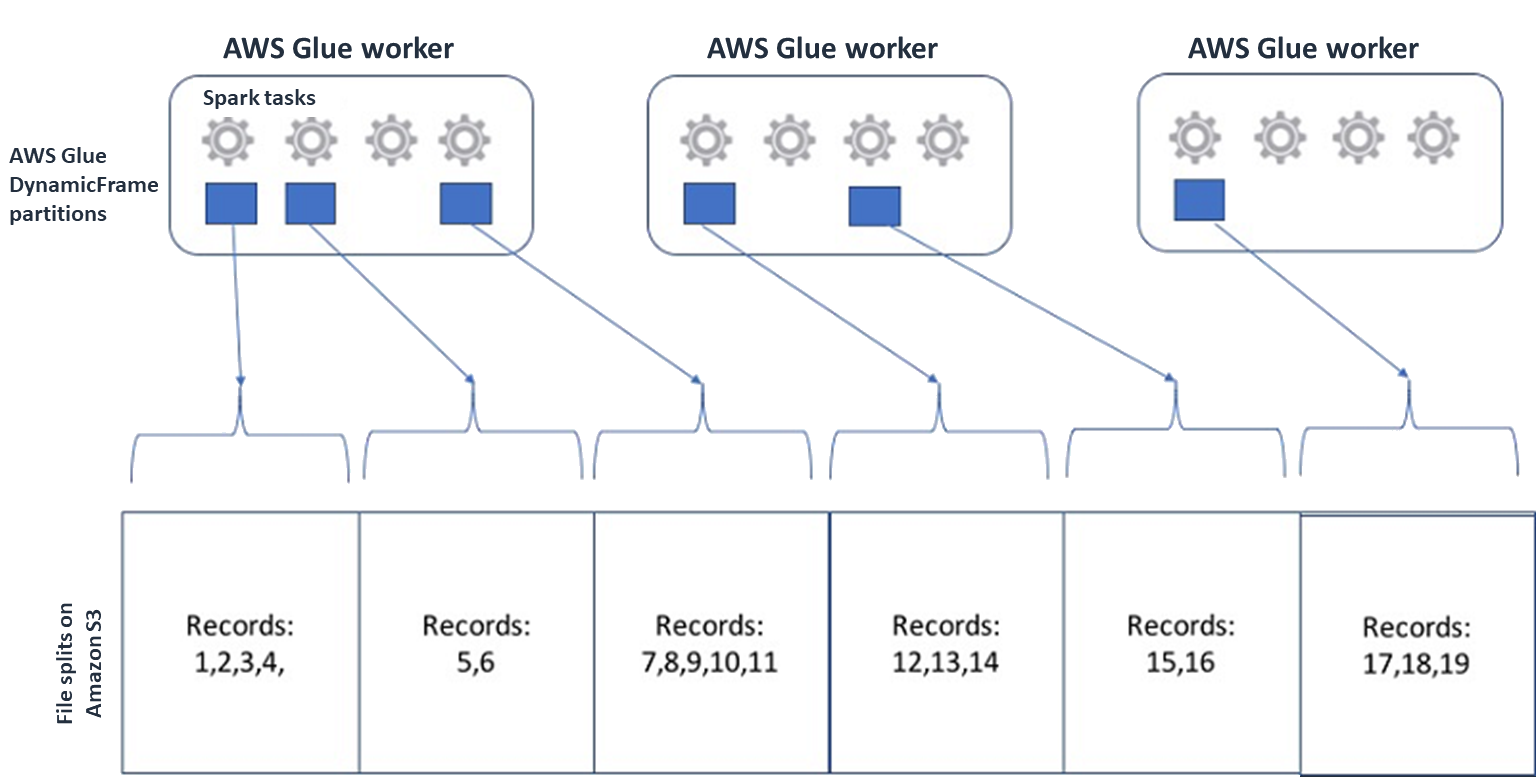
Les données compressées peuvent accélérer considérablement votre application, à condition que les fichiers soient d'une taille optimale ou qu'ils soient séparables. Les petites tailles de données réduisent les données numérisées depuis Amazon S3 et le trafic réseau d'Amazon S3 vers votre cluster Spark. D'autre part, il en faut davantage CPU pour compresser et décompresser les données. La quantité de calcul requise varie en fonction du taux de compression de votre algorithme de compression. Tenez compte de ce compromis lorsque vous choisissez votre format de compression fractionnable.
Note
Bien que les fichiers gzip ne soient généralement pas séparables, vous pouvez compresser des blocs de parquet individuels avec gzip, et ces blocs peuvent être parallélisés.
-
-
Format de fichier — Utilisez un format en colonnes. Apache Parquet
et Apache ORC sont des formats de données en colonnes populaires. Parcourez et ORC stockez les données de manière efficace en utilisant la compression basée sur les colonnes, en encodant et en compressant chaque colonne en fonction de son type de données. Pour plus d'informations sur les codages Parquet, consultez la section Définitions de codage Parquet . Les fichiers de parquet sont également séparables. Les formats en colonnes regroupent les valeurs par colonne et les stockent ensemble dans des blocs. Lorsque vous utilisez des formats en colonnes, vous pouvez ignorer les blocs de données correspondant à des colonnes que vous n'avez pas l'intention d'utiliser. Les applications Spark ne peuvent récupérer que les colonnes dont vous avez besoin. En général, de meilleurs taux de compression ou le fait de sauter des blocs de données permettent de lire moins d'octets depuis Amazon S3, ce qui améliore les performances. Les deux formats prennent également en charge les approches pushdown suivantes pour réduire les E/S :
-
Projection pushdown — La projection pushdown est une technique qui permet de récupérer uniquement les colonnes spécifiées dans votre application. Vous spécifiez des colonnes dans votre application Spark, comme indiqué dans les exemples suivants :
-
DataFrame exemple :
df.select("star_rating") -
SQLExemple de Spark :
spark.sql("select start_rating from <table>")
-
-
Pushdown des prédicats — Le pushdown des prédicats est une technique permettant un traitement et des clauses efficaces.
WHEREGROUP BYLes deux formats comportent des blocs de données qui représentent les valeurs des colonnes. Chaque bloc contient des statistiques pour le bloc, telles que les valeurs maximales et minimales. Spark peut utiliser ces statistiques pour déterminer si le bloc doit être lu ou ignoré en fonction de la valeur de filtre utilisée dans l'application. Pour utiliser cette fonctionnalité, ajoutez des filtres supplémentaires dans les conditions, comme indiqué dans les exemples suivants :-
DataFrame exemple :
df.select("star_rating").filter("star_rating < 2") -
SQLExemple de Spark :
spark.sql("select * from <table> where star_rating < 2")
-
-
-
Disposition des fichiers — En stockant vos données S3 dans des objets dans différents chemins en fonction de la façon dont les données seront utilisées, vous pouvez récupérer efficacement les données pertinentes. Pour plus d'informations, consultez la section Organisation des objets à l'aide de préfixes dans la documentation Amazon S3. AWS Glue prend en charge le stockage des clés et des valeurs des préfixes Amazon S3 au format
key=value, en partitionnant vos données selon le chemin Amazon S3. En partitionnant vos données, vous pouvez limiter la quantité de données numérisées par chaque application d'analyse en aval, ce qui améliore les performances et réduit les coûts. Pour plus d'informations, consultez la section Gestion des partitions pour ETL la sortie dans AWS Glue.Le partitionnement divise votre table en différentes parties et conserve les données associées dans des fichiers groupés en fonction de valeurs de colonne telles que l'année, le mois et le jour, comme indiqué dans l'exemple suivant.
# Partitioning by /YYYY/MM/DD s3://<YourBucket>/year=2023/month=03/day=31/0000.gz s3://<YourBucket>/year=2023/month=03/day=01/0000.gz s3://<YourBucket>/year=2023/month=03/day=02/0000.gz s3://<YourBucket>/year=2023/month=03/day=03/0000.gz ...Vous pouvez définir des partitions pour votre jeu de données en le modélisant à l'aide d'une table dans le AWS Glue Data Catalog. Vous pouvez ensuite limiter la quantité de données numérisées en utilisant l'élagage des partitions comme suit :
-
Pour AWS Glue DynamicFrame, régler
push_down_predicate(oucatalogPartitionPredicate).dyf = Glue_context.create_dynamic_frame.from_catalog( database=src_database_name, table_name=src_table_name, push_down_predicate = "year='2023' and month ='03'", ) -
Pour Spark DataFrame, définissez un chemin fixe pour élaguer les partitions.
df = spark.read.format("json").load("s3://<YourBucket>/year=2023/month=03/*/*.gz") -
Pour SparkSQL, vous pouvez définir la clause Where pour supprimer les partitions du catalogue de données.
df = spark.sql("SELECT * FROM <Table> WHERE year= '2023' and month = '03'") -
Pour partitionner par date lorsque vous écrivez vos données avec AWS Glue, vous devez DynamicFrame saisir ou partitionBy()
DataFrame insérer les informations de date dans vos colonnes comme suit. partitionKeys -
DynamicFrame
glue_context.write_dynamic_frame_from_options( frame= dyf, connection_type='s3',format='parquet' connection_options= { 'partitionKeys': ["year", "month", "day"], 'path': 's3://<YourBucket>/<Prefix>/' } ) -
DataFrame
df.write.mode('append')\ .partitionBy('year','month','day')\ .parquet('s3://<YourBucket>/<Prefix>/')
Cela peut améliorer les performances des consommateurs de vos données de sortie.
Si vous n'êtes pas autorisé à modifier le pipeline qui crée votre jeu de données en entrée, le partitionnement n'est pas une option. Au lieu de cela, vous pouvez exclure les chemins S3 inutiles en utilisant des modèles globaux. Définissez des exclusions lors de la lecture DynamicFrame. Par exemple, le code suivant exclut les jours des mois 01 à 09, de l'année 2023.
dyf = glueContext.create_dynamic_frame.from_catalog( database=db, table_name=table, additional_options = { "exclusions":"[\"**year=2023/month=0[1-9]/**\"]" }, transformation_ctx='dyf' )Vous pouvez également définir des exclusions dans les propriétés des tables du catalogue de données :
-
Clé :
exclusions -
Valeur :
["**year=2023/month=0[1-9]/**"]
-
-
-
Trop de partitions Amazon S3 : évitez de partitionner vos données Amazon S3 sur des colonnes contenant un large éventail de valeurs, comme une colonne d'ID contenant des milliers de valeurs. Cela peut augmenter considérablement le nombre de partitions dans votre bucket, car le nombre de partitions possibles est le produit de tous les champs que vous avez partitionnés. Un trop grand nombre de partitions peut provoquer les effets suivants :
-
Latence accrue pour récupérer les métadonnées des partitions à partir du catalogue de données
-
Augmentation du nombre de petits fichiers, ce qui nécessite davantage de API requêtes Amazon S3 (
List,Get, etHead)
Par exemple, lorsque vous définissez un type de date dans
partitionByoupartitionKeys, un partitionnement au niveau de la dateyyyy/mm/ddest adapté à de nombreux cas d'utilisation. Cependant,yyyy/mm/dd/<ID>cela peut générer tellement de partitions que cela aurait un impact négatif sur les performances dans leur ensemble.D'autre part, certains cas d'utilisation, tels que les applications de traitement en temps réel, nécessitent de nombreuses partitions telles que
yyyy/mm/dd/hh. Si votre cas d'utilisation nécessite des partitions importantes, pensez à utiliser des index de AWS Glue partition pour réduire le temps de latence lors de la récupération des métadonnées de partition à partir du catalogue de données. -
Bases de données et JDBC
Pour réduire l'analyse des données lors de la récupération d'informations dans une base de données, vous pouvez spécifier un where prédicat (ou une clause) dans une SQL requête. Les bases de données qui ne fournissent pas d'SQLinterface fourniront leur propre mécanisme d'interrogation ou de filtrage.
Lorsque vous utilisez des connexions Java Database Connectivity (JDBC), fournissez une requête de sélection avec la where clause pour les paramètres suivants :
-
Pour DynamicFrame, utilisez l'sampleQueryoption. Lors de l'utilisation
create_dynamic_frame.from_catalog, configurez l'additional_optionsargument comme suit.query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_catalog( database = db, table_name = table, additional_options={ "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True }, transformation_ctx = "datasource0" )Quand
using create_dynamic_frame.from_options, configurez l'connection_optionsargument comme suit.query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_options( connection_type = connection, connection_options={ "url": url, "user": user, "password": password, "dbtable": table, "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True } ) -
Pour DataFrame, utilisez l'option de requête
. query = "SELECT * FROM <TableName> where id = 'XX'" jdbcDF = spark.read \ .format('jdbc') \ .option('url', url) \ .option('user', user) \ .option('password', pwd) \ .option('query', query) \ .load() -
Pour Amazon Redshift, utilisez la AWS Glue version 4.0 ou une version ultérieure pour bénéficier de la prise en charge du pushdown dans le connecteur Amazon Redshift Spark.
dyf = glueContext.create_dynamic_frame.from_catalog( database = "redshift-dc-database-name", table_name = "redshift-table-name", redshift_tmp_dir = args["temp-s3-dir"], additional_options = {"aws_iam_role": "arn:aws:iam::role-account-id:role/rs-role-name"} ) -
Pour les autres bases de données, consultez la documentation de cette base de données.
AWS Glue options
-
Pour éviter une analyse complète de toutes les exécutions de tâches en continu et ne traiter que les données absentes lors de la dernière exécution de tâches, activez les signets de tâches.
-
Pour limiter la quantité de données d'entrée à traiter, activez l'exécution limitée avec des signets de tâches. Cela permet de réduire la quantité de données numérisées pour chaque exécution de tâche.
