Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Déployez des modèles pour une inférence en temps réel
L'inférence en temps réel est idéale pour les charges de travail d'inférence où vous avez des exigences en temps réel, interactives et à faible latence. Cette section montre comment vous pouvez utiliser l'inférence en temps réel pour obtenir des prévisions interactives à partir de votre modèle.
Plusieurs options s'offrent à vous pour déployer le modèle qui a produit la meilleure métrique de validation dans une expérience Autopilot. Par exemple, lorsque vous utilisez le pilote automatique dans SageMaker Studio Classic, vous pouvez déployer le modèle automatiquement ou manuellement. Vous pouvez également l'utiliser SageMaker APIs pour déployer manuellement un modèle de pilote automatique.
Les onglets suivants présentent trois options pour déployer votre modèle. Ces instructions supposent que vous avez déjà créé un modèle dans Autopilot. Si vous ne disposez pas de modèle, veuillez consulter Créez des tâches de régression ou de classification pour des données tabulaires à l'aide de l'AutoML API. Pour voir des exemples de chaque option, ouvrez chaque onglet.
L'interface utilisateur d'Autopilot contient des menus déroulants utiles, des boutons, des infobulles et bien plus encore, pour vous aider à parcours le déploiement du modèle. Vous pouvez déployer à l'aide de l'une des procédures suivantes : automatique ou manuelle.
-
Déploiement automatique : pour déployer automatiquement le meilleur modèle, d'une expérience Autopilot vers un point de terminaison
-
Créez un test dans SageMaker Studio Classic.
-
Basculez la valeur Auto deploy (Déploiement automatique) sur Yes (Oui).
Note
Le déploiement automatique échoue si le quota de ressources par défaut ou votre quota client pour les instances de point de terminaison dans une région est trop limité. En mode d'optimisation des hyperparamètres (HPO), vous devez disposer d'au moins deux instances ml.m5.2xlarge. En mode d'assemblage, vous devez avoir au moins une instance ml.m5.12xlarge. Si vous rencontrez un échec lié aux quotas, vous pouvez demander une augmentation de la limite de service pour les instances de point de SageMaker terminaison.
-
-
Déploiement manuel : pour déployer manuellement le meilleur modèle, d'une expérience Autopilot vers un point de terminaison
-
Créez un test dans SageMaker Studio Classic.
-
Basculez la valeur Auto deploy (Déploiement automatique) sur No (Non).
-
Sélectionnez le modèle que vous voulez déployer sous Model name (Nom du modèle).
-
Sélectionnez le bouton orange Deployment and advanced settings (Déploiement et paramètres avancés) situé à droite du classement. Un nouvel onglet s'ouvre.
-
Configurez le nom du point de terminaison, le type d'instance et d'autres informations facultatives.
-
Sélectionnez le bouton orange Deploy model (Déployer le modèle) pour déployer vers un point de terminaison.
-
Vérifiez la progression du processus de création du point de terminaison en https://console.aws.amazon.com/sagemaker/
accédant à la section Points de terminaison. Cette section se trouve dans le menu déroulant Inference (Inférence) du panneau de navigation. -
Une fois que le statut du point de terminaison est passé de Creating à InService, comme indiqué ci-dessous, revenez à Studio Classic et appelez le point de terminaison.
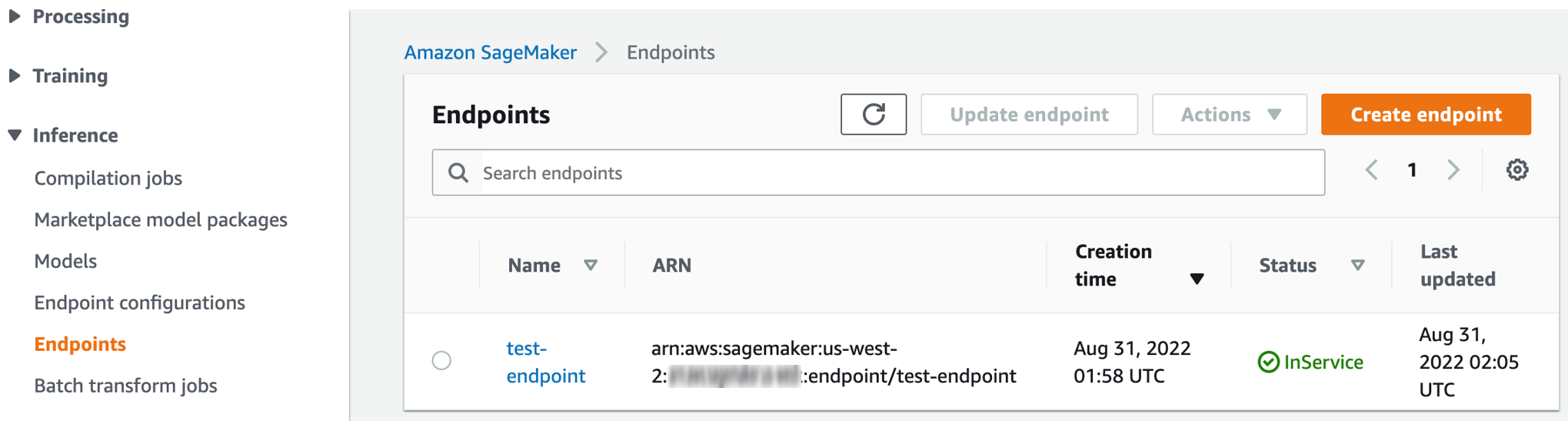
-
Vous pouvez également obtenir des inférences en temps réel en déployant votre modèle à l'aide d'APIappels. Cette section présente les cinq étapes de ce processus à l'aide d'extraits de code AWS Command Line Interface (AWS CLI).
Pour obtenir des exemples de code complets pour AWS CLI les deux commandes et AWS SDK pour Python (boto3), ouvrez les onglets directement en suivant ces étapes.
-
Obtenir les définitions des candidats
Obtenez les définitions des conteneurs candidats auprès de InferenceContainers. Ces définitions de candidats sont utilisées pour créer un SageMaker modèle.
L'exemple suivant utilise le DescribeAutoMLJobAPIpour obtenir les définitions du meilleur modèle candidat. Consultez la AWS CLI commande suivante à titre d'exemple.
aws sagemaker describe-auto-ml-job --auto-ml-job-name<job-name>--region<region> -
Liste des candidats
L'exemple suivant utilise le ListCandidatesForAutoMLJobAPIpour répertorier tous les candidats. La commande AWS CLI suivante constitue un exemple.
aws sagemaker list-candidates-for-auto-ml-job --auto-ml-job-name<job-name>--region<region> -
Création d'un SageMaker modèle
Utilisez les définitions de conteneur des étapes précédentes pour créer un SageMaker modèle à l'aide du CreateModelAPI. Consultez la AWS CLI commande suivante à titre d'exemple.
aws sagemaker create-model --model-name '<your-custom-model-name>' \ --containers ['<container-definition1>,<container-definition2>,<container-definition3>]' \ --execution-role-arn '<execution-role-arn>' --region '<region> -
Créer une configuration de point de terminaison
L'exemple suivant utilise le CreateEndpointConfigAPIpour créer une configuration de point de terminaison. Consultez la AWS CLI commande suivante à titre d'exemple.
aws sagemaker create-endpoint-config --endpoint-config-name '<your-custom-endpoint-config-name>' \ --production-variants '<list-of-production-variants>' \ --region '<region>' -
Créer le point de terminaison
L' AWS CLI exemple suivant utilise le CreateEndpointAPIpour créer le point de terminaison.
aws sagemaker create-endpoint --endpoint-name '<your-custom-endpoint-name>' \ --endpoint-config-name '<endpoint-config-name-you-just-created>' \ --region '<region>'Vérifiez la progression du déploiement de votre terminal à l'aide du DescribeEndpointAPI. Consultez la AWS CLI commande suivante à titre d'exemple.
aws sagemaker describe-endpoint —endpoint-name '<endpoint-name>' —region<region>Lorsque
EndpointStatusdevientInService, le point de terminaison est prêt à être utilisé pour l'inférence en temps réel. -
Appeler le point de terminaison
La structure de commande suivante appelle le point de terminaison pour une inférence en temps réel.
aws sagemaker invoke-endpoint --endpoint-name '<endpoint-name>' \ --region '<region>' --body '<your-data>' [--content-type] '<content-type>'<outfile>
Les onglets suivants contiennent des exemples de code complets pour déployer un modèle avec AWS SDK for Python (boto3) ou le. AWS CLI
Vous pouvez déployer un modèle Autopilot à partir d'un compte différent du compte d'origine dans lequel le modèle a été généré. Pour implémenter le déploiement de modèles multicomptes, cette section explique comment procéder comme suit :
-
Accorder l'autorisation au compte de déploiement
Pour assumer le rôle dans le compte générateur, vous devez accorder l'autorisation au compte à partir duquel vous souhaitez effectuer le déploiement. Cela permet au compte de déploiement de décrire les tâches Autopilot dans le compte générateur.
L'exemple suivant utilise un compte générateur avec une entité
sagemaker-rolede confiance. L'exemple montre comment autoriser un compte de déploiement portant l'ID 111122223333 à assumer le rôle du compte générateur."Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "sagemaker.amazonaws.com" ], "AWS": [ "111122223333"] }, "Action": "sts:AssumeRole" }Le nouveau compte portant l'ID 111122223333 peut désormais assumer le rôle du compte générateur.
Ensuite, appelez le compte
DescribeAutoMLJobAPI de déploiement pour obtenir une description de la tâche créée par le compte générateur.L'exemple de code suivant décrit le modèle issu du compte de déploiement.
import sagemaker import boto3 session = sagemaker.session.Session() sts_client = boto3.client('sts') sts_client.assume_role role = 'arn:aws:iam::111122223333:role/sagemaker-role' role_session_name = "role-session-name" _assumed_role = sts_client.assume_role(RoleArn=role, RoleSessionName=role_session_name) credentials = _assumed_role["Credentials"] access_key = credentials["AccessKeyId"] secret_key = credentials["SecretAccessKey"] session_token = credentials["SessionToken"] session = boto3.session.Session() sm_client = session.client('sagemaker', region_name='us-west-2', aws_access_key_id=access_key, aws_secret_access_key=secret_key, aws_session_token=session_token) # now you can call describe automl job created in account A job_name = "test-job" response= sm_client.describe_auto_ml_job(AutoMLJobName=job_name) -
Accordez l'accès au compte de déploiement aux artefacts du modèle du compte de génération.
Le compte de déploiement a simplement besoin d'accéder aux artefacts du modèle dans le compte de génération pour le déployer. Ils se trouvent dans le S3 OutputPath spécifié lors de l'
CreateAutoMLJobAPIappel initial lors de la génération du modèle.Pour donner au compte de déploiement l'accès aux artefacts du modèle, choisissez l'une des options suivantes :
-
Donnez accès
au ModelDataUrlà partir du compte générateur vers le compte de déploiement.Ensuite, vous devez autoriser le compte de déploiement à assumer le rôle. Suivez les étapes d'inférence en temps réel pour le déploiement.
-
Copiez les artefacts du modèle
depuis le S3 d'origine du compte générateur OutputPath vers le compte générateur. Pour autoriser l'accès aux artefacts du modèle, vous devez définir un modèle
best_candidateet réattribuer des conteneurs de modèles au nouveau compte.L'exemple suivant illustre la façon de définir un modèle
best_candidateet de réaffecter leModelDataUrl.best_candidate = automl.describe_auto_ml_job()['BestCandidate'] # reassigning ModelDataUrl for best_candidate containers below new_model_locations = ['new-container-1-ModelDataUrl', 'new-container-2-ModelDataUrl', 'new-container-3-ModelDataUrl'] new_model_locations_index = 0 for container in best_candidate['InferenceContainers']: container['ModelDataUrl'] = new_model_locations[new_model_locations_index++]Après cette attribution de conteneurs, suivez les étapes décrites dans Déployez en utilisant SageMaker APIs pour le déploiement.
-
Pour créer une charge utile dans l'inférence en temps réel, consultez l'exemple du bloc-notes pour définir une charge utile de test
