Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Association de résultats de prédiction à des enregistrements d'entrée
Lorsque vous effectuez des prédictions sur un ensemble de données volumineux, vous pouvez exclure les attributs qui ne sont pas nécessaires pour les prédictions. Une fois les prédictions effectuées, vous souhaitez dans la plupart des cas associer certains des attributs exclus avec ces prédictions ou avec d'autres données d'entrée dans votre rapport. En utilisant la transformation par lots pour effectuer ces étapes de traitement des données, vous pouvez souvent éliminer d'autres prétraitement ou post-traitement. Vous pouvez utiliser les fichiers d'entrée au format JSON et CVS uniquement.
Rubriques
Flux de travail pour l'association d'inférences à des enregistrements d'entrée
Le schéma suivant illustre le flux de travail pour associer des inférences à des enregistrements d'entrée.
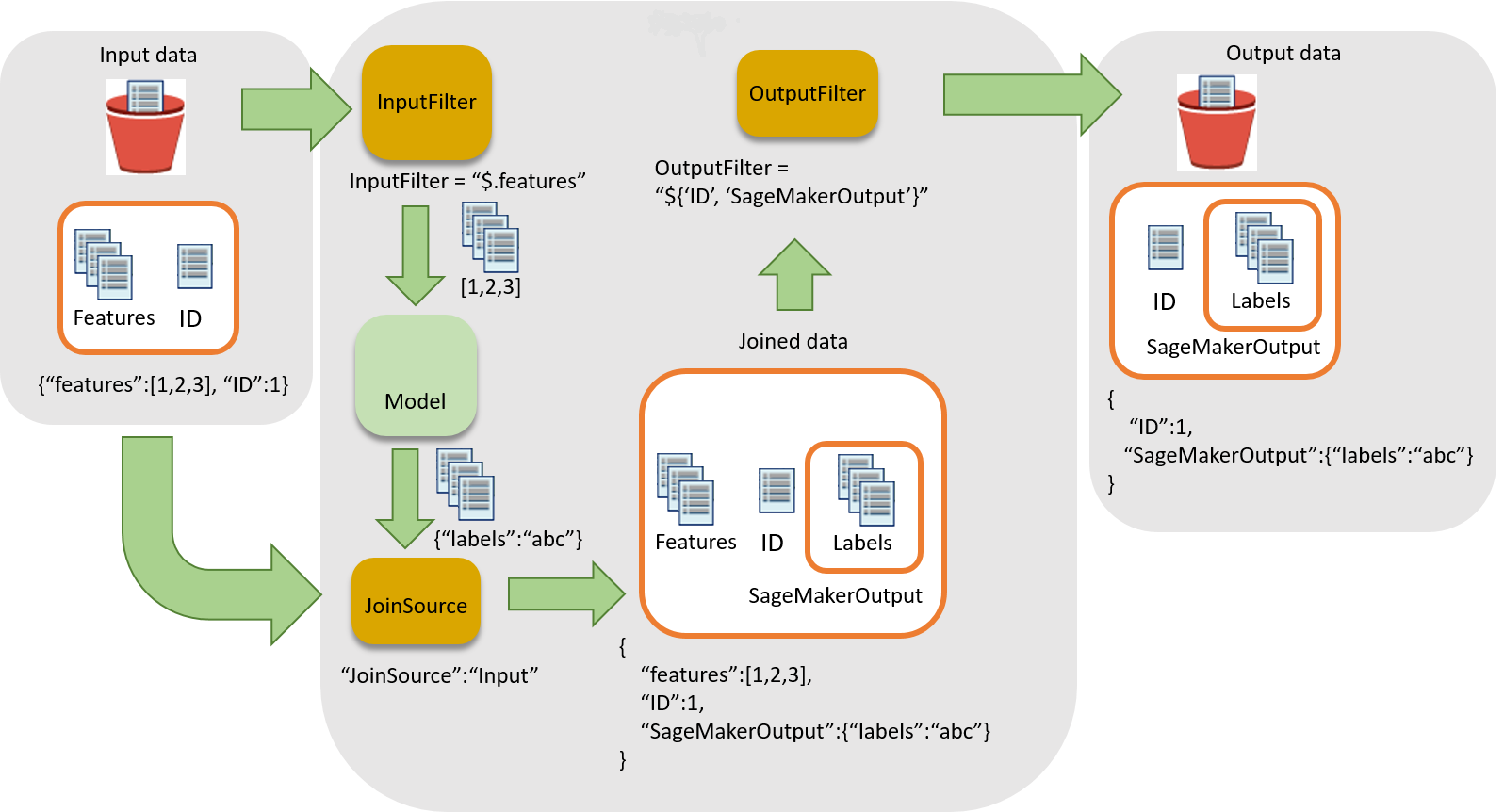
Pour associer des inférences à des données d'entrée, il y a trois étapes principales :
-
Filtrez les données d'entrée qui ne sont pas nécessaires à l'inférence avant de les transmettre à la tâche de transformation par lots. Utilisez le paramètre
InputFilterpour déterminer les attributs à utiliser en tant qu'entrée pour le modèle. -
Associez les données d'entrée aux résultats de l'inférence. Utilisez le paramètre
JoinSourcepour combiner les données d'entrée avec l'inférence. -
Filtrez les données associées afin de conserver les entrées nécessaires pour indiquer le contexte de l'interprétation des prédictions dans les rapports. Utilisez
OutputFilterpour stocker la partie spécifiée du jeu de données associé dans le fichier de sortie.
Utilisation du traitement des données dans les tâches de transformation par lots
Lors de la création d'une tâche de transformation par lots avec CreateTransformJob pour traiter des données :
-
Spécifiez la partie de l'entrée à transmettre au modèle avec le paramètre
InputFilterdans la structure de donnéesDataProcessing. -
Associez les données d'entrée brutes aux données transformées avec le paramètre
JoinSource. -
Indiquez la partie de l'entrée associée et des données transformées issues de la tâche de transformation par lots à inclure dans le fichier de sortie avec le paramètre
OutputFilter. -
Choisissez des fichiers JSON ou CSV-formatted des fichiers pour la saisie :
-
Pour les fichiers Lines-formatted d'entrée JSON ou JSON, SageMaker AI ajoute l'
SageMakerOutputattribut au fichier d'entrée ou crée un nouveau fichier de sortie JSON avec lesSageMakerOutputattributsSageMakerInputet. Pour de plus amples informations, veuillez consulterDataProcessing. -
Pour les fichiers CSV-formatted d'entrée, les données d'entrée jointes sont suivies des données transformées et la sortie est un fichier CSV.
-
Si vous utilisez un algorithme avec la structure DataProcessing, il doit prendre en charge le format que vous avez choisi pour les fichiers d'entrée et les fichiers de sortie. Par exemple, avec le champ TransformOutput de l'API CreateTransformJob, vous devez configurer les paramètres ContentType et Accept sur l'une des valeurs suivantes : text/csv, application/json ou application/jsonlines. La syntaxe permettant de spécifier des colonnes dans un fichier CSV est différente de la syntaxe permettant de spécifier des attributs dans un fichier JSON. L'utilisation d'une syntaxe incorrecte provoque une erreur. Pour de plus amples informations, veuillez consulter Exemples de transformation par lots. Pour plus d'informations sur les formats de fichier d'entrée et de sortie pour les algorithmes intégrés, consultez Built-in algorithmes et modèles préentraînés sur Amazon SageMaker.
Les délimiteurs d'enregistrement pour l'entrée et la sortie doivent également être cohérents avec l'entrée de fichier que vous avez choisie. Le paramètre SplitType indique le mode de fractionnement des enregistrements dans le jeu de données d'entrée. Le paramètre AssembleWith indique le mode de reconstitution des enregistrements pour la sortie. Si vous définissez les formats d'entrée et de sortie sur text/csv, vous devez également définir les paramètres SplitType et AssembleWith sur line. Si vous définissez les formats d'entrée et de sortie sur application/jsonlines, vous pouvez définir les paramètres SplitType et AssembleWith sur line.
Pour les fichiers CSV, vous ne pouvez pas utiliser de caractères de saut de ligne intégrés. Pour les fichiers JSON, le nom d'attribut SageMakerOutput est réservé à la sortie. Le fichier d'entrée JSON ne peut pas avoir d'attribut portant ce nom. Si c'est le cas, les données du fichier d'entrée risquent d'être écrasées.
Opérateurs JSONPath pris en charge
Pour filtrer et associer les données d'entrée et l'inférence, utilisez une sous-expression JSONPath. SageMaker L'IA ne prend en charge qu'un sous-ensemble des opérateurs JSONPath définis. Le tableau suivant répertorie les opérateurs JSONPath pris en charge. Pour les données CSV, chaque ligne est considérée comme un tableau JSON. Par conséquent, seules les valeurs JSONPaths basées sur l'index peuvent être appliquées, par exemple $[0], $[1:]. Les données CSV doivent également respecter le format RFC
| Opérateur JSONPath | Description | Exemple |
|---|---|---|
$ |
Élément racine d'une requête. Cet opérateur est requis au début de toutes les expressions de chemin d'accès. |
$ |
. |
Élément enfant à notation point. |
|
* |
Caractère générique. Utilisez-le pour remplacer un nom d'attribut ou une valeur numérique. |
|
[' |
Élément à notation crochet ou éléments enfants multiples. |
|
[ |
Index ou tableau d'index. Les valeurs d'index négatives sont également prises en charge. Un index |
|
[ |
Opérateur de découpage de tableau. La méthode array slice() extrait une section d'un tableau et renvoie un nouveau tableau. Si vous omettez |
|
Lorsque vous utilisez la notation entre crochets pour spécifier plusieurs éléments enfants d'un champ donné, l'imbrication supplémentaire d'enfants entre parenthèses n'est pas prise en charge. Par exemple, $.field1.['child1','child2'] est pris en charge alors qu'$.field1.['child1','child2.grandchild'] ne l'est pas.
Pour plus d'informations sur les opérateurs JSONPath, reportez-vous JsonPath
Exemples de transformation par lots
Les exemples suivants illustrent les méthodes courantes permettant d'associer des données d'entrée aux résultats de prédiction.
Rubriques
Exemple : Inférences de sortie uniquement
Par défaut, le paramètre DataProcessing ne joint pas les résultats d'inférence à l'entrée. Il génère uniquement les résultats de l'inférence.
Si vous souhaitez spécifier explicitement de ne pas associer les résultats aux entrées, utilisez le SDK Amazon SageMaker Python
sm_transformer = sagemaker.transformer.Transformer(…) sm_transformer.transform(…, input_filter="$", join_source= "None", output_filter="$")
Pour générer des inférences à l'aide du AWS SDK pour Python, ajoutez le code suivant à votre CreateTransformJob demande. Le code suivant imite le comportement par défaut.
{ "DataProcessing": { "InputFilter": "$", "JoinSource": "None", "OutputFilter": "$" } }
Exemple : inférences de sortie avec des données d'entrée
Si vous utilisez le SDK Amazon SageMaker Pythonaccept paramètres assemble_with et lors de l'initialisation de l'objet transformateur. Lorsque vous utilisez l'appel de transformation, spécifiez Input pour le paramètre join_source et spécifiez également le paramètres split_type et content_type. Le paramètre split_type doit avoir la même valeur que assemble_with, et le paramètre content_type doit avoir la même valeur que accept. Pour plus d'informations sur les paramètres et leurs valeurs acceptées, consultez la page Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, join_source="Input", split_type="Line", content_type="text/csv")
Si vous utilisez le AWS SDK pour Python (Boto 3), associez toutes les données d'entrée à l'inférence en ajoutant le code suivant à votre demande. CreateTransformJob Les valeurs pour Accept et ContentType doivent correspondre, et les valeurs pour AssembleWith et SplitType doivent également correspondre.
{ "DataProcessing": { "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
Pour le format JSON ou JSON Lines, les résultats figurent dans la clé SageMakerOutput du fichier JSON en entrée. Par exemple, si l'entrée est un fichier JSON qui contient la paire clé-valeur {"key":1}, le résultat de la transformation des données peut être {"label":1}.
SageMaker L'IA enregistre les deux dans le fichier d'entrée de la SageMakerInput clé.
{ "key":1, "SageMakerOutput":{"label":1} }
Note
Le résultat associé pour JSON doit être un objet de type paire clé-valeur. Si l'entrée n'est pas un objet de paire clé-valeur, SageMaker AI crée un nouveau fichier JSON. Dans le nouveau fichier JSON, les données d'entrée sont stockées dans la clé SageMakerInput et les résultats sont stockés dans la valeur SageMakerOutput.
Pour un fichier CSV, si l'enregistrement est [1,2,3] et le résultat d'étiquette est [1] par exemple, le fichier de sortie contient alors [1,2,3,1].
Exemple : inférences de sortie avec des données d'entrée et exclusion de la colonne ID de l'entrée (CSV)
Si vous utilisez le SDK Amazon SageMaker Pythoninput_filter dans votre appel de transformateur. Par exemple, si vos données d'entrée incluent cinq colonnes (la première étant la colonne ID), utilisez la demande de transformateur suivante pour sélectionner toutes les colonnes à l'exception de la colonne ID comme fonctions. Le transformateur sort toujours toutes les colonnes d'entrée jointes aux inférences. Pour plus d'informations sur les paramètres et leurs valeurs acceptées, consultez la page Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input")
Si vous utilisez le AWS SDK pour Python (Boto 3), ajoutez le code suivant à votre
CreateTransformJob demande.
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
Pour spécifier des colonnes dans SageMaker AI, utilisez l'index des éléments du tableau. La première colonne est l'index 0, la deuxième est l'index 1 et la sixième est l'index 5.
Pour exclure la première colonne de l'entrée, définissez InputFilter sur "$[1:]". Les deux points (:) indiquent à SageMaker AI d'inclure tous les éléments compris entre deux valeurs, y compris. Par exemple, $[1:4] spécifie les colonnes 2 à 5.
Si vous omettez le nombre après les deux points, par exemple, [5:], le sous-ensemble inclut toutes les colonnes, de la sixième à la dernière. Si vous omettez le nombre avant les deux points, par exemple, [:5], le sous-ensemble inclut toutes les colonnes, de la première (index 0) à la sixième.
Exemple : inférences de sortie jointes à une colonne ID et exclusion de la colonne ID de l'entrée (CSV)
Si vous utilisez le SDK Amazon SageMaker Pythonoutput_filter dans l'appel du transformateur. Le output_filter utilise une sous-expression JSONPath pour spécifier les colonnes à renvoyer en sortie après avoir joint les données en entrée avec les résultats de l'inférence. La demande suivante montre comment faire des prédictions tout en excluant une colonne ID, puis joindre la colonne ID avec les inférences. Notez que dans l'exemple suivant, la dernière colonne (-1) de la sortie contient les inférences. Si vous utilisez des fichiers JSON, SageMaker AI stocke les résultats de l'inférence dans l'attributSageMakerOutput. Pour plus d'informations sur les paramètres et leurs valeurs acceptées, consultez la page Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input", output_filter="$[0,-1]")
Si vous utilisez le AWS SDK pour Python (Boto 3), joignez uniquement la colonne ID avec les inférences en ajoutant le code suivant à votre demande. CreateTransformJob
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input", "OutputFilter": "$[0,-1]" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
Avertissement
Si vous utilisez un fichier JSON-formatted d'entrée, celui-ci ne peut pas contenir le nom de l'attributSageMakerOutput. Le nom d'attribut est réservé aux interférences présentes dans le fichier de sortie. Si votre fichier JSON-formatted d'entrée contient un attribut portant ce nom, les valeurs du fichier d'entrée peuvent être remplacées par l'inférence.
