Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Exemples de code : SDK pour Python
Cette section fournit un exemple de code permettant de créer et d'invoquer un point de terminaison utilisant l'explicabilité en ligne SageMaker Clarify. Ces exemples de code utilisent le code AWS SDKpour Python.
Données tabulaires
L'exemple suivant utilise des données tabulaires et un SageMaker modèle appelémodel_name. Dans cet exemple, le conteneur du modèle accepte les données au CSV format, et chaque enregistrement possède quatre caractéristiques numériques. Dans cette configuration minimale, à des fins de démonstration uniquement, les données SHAP de référence sont mises à zéro. Reportez-vous SHAPPoints de référence pour l'explicabilité à la section pour savoir comment choisir des valeurs plus appropriées pourShapBaseline.
Configurez le point de terminaison comme suit :
endpoint_config_name = 'tabular_explainer_endpoint_config' response = sagemaker_client.create_endpoint_config( EndpointConfigName=endpoint_config_name, ProductionVariants=[{ 'VariantName': 'AllTraffic', 'ModelName': model_name, 'InitialInstanceCount': 1, 'InstanceType': 'ml.m5.xlarge', }], ExplainerConfig={ 'ClarifyExplainerConfig': { 'ShapConfig': { 'ShapBaselineConfig': { 'ShapBaseline': '0,0,0,0', }, }, }, }, )
Utilisez la configuration du point de terminaison pour créer un point de terminaison, comme suit :
endpoint_name = 'tabular_explainer_endpoint' response = sagemaker_client.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name, )
Utilisez le DescribeEndpoint API pour inspecter la progression de la création d'un point de terminaison, comme suit :
response = sagemaker_client.describe_endpoint( EndpointName=endpoint_name, ) response['EndpointStatus']
Une fois que le statut du point de terminaison est InService « », invoquez le point de terminaison avec un enregistrement de test, comme suit :
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='1,2,3,4', )
Note
Dans l'exemple de code précédent, pour les points de terminaison multimodèles, transmettez un paramètre TargetModel supplémentaire dans la demande pour spécifier le modèle à cibler au niveau du point de terminaison.
Supposons que le code d'état de la réponse est 200 (aucune erreur) et chargez le corps de la réponse comme suit :
import codecs import json json.load(codecs.getreader('utf-8')(response['Body']))
L'action par défaut pour le point de terminaison consiste à expliquer l'enregistrement. Voici un exemple de sortie dans l'JSONobjet renvoyé.
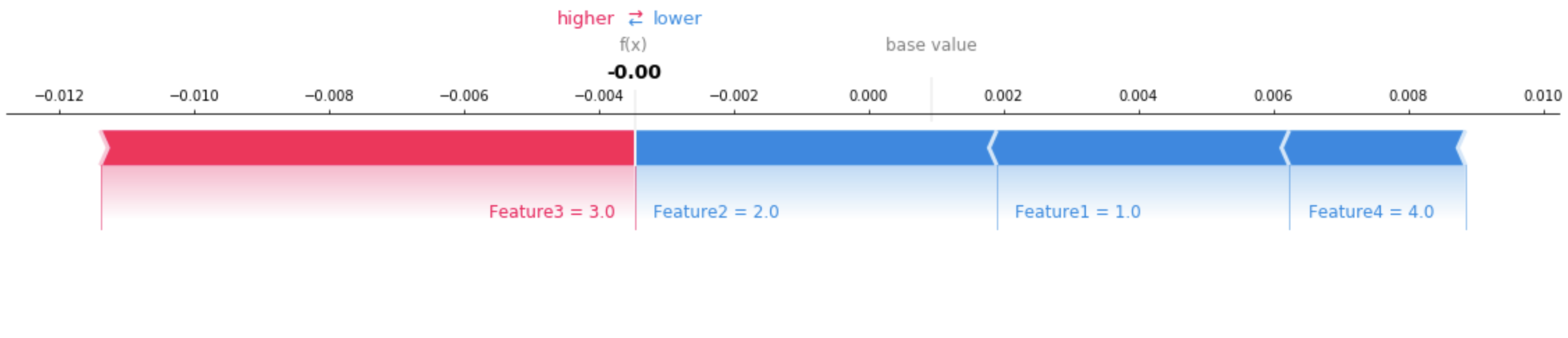
{ "version": "1.0", "predictions": { "content_type": "text/csv; charset=utf-8", "data": "0.0006380207487381" }, "explanations": { "kernel_shap": [ [ { "attributions": [ { "attribution": [-0.00433456] } ] }, { "attributions": [ { "attribution": [-0.005369821] } ] }, { "attributions": [ { "attribution": [0.007917749] } ] }, { "attributions": [ { "attribution": [-0.00261214] } ] } ] ] } }
Utilisez le paramètre EnableExplanations pour activer les explications à la demande, comme suit :
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='1,2,3,4', EnableExplanations='[0]>`0.8`', )
Note
Dans l'exemple de code précédent, pour les points de terminaison multimodèles, transmettez un paramètre TargetModel supplémentaire dans la demande pour spécifier le modèle à cibler au niveau du point de terminaison.
Dans cet exemple, la valeur de prédiction est inférieure à la valeur de seuil de 0.8. L'enregistrement n'est donc pas expliqué :
{ "version": "1.0", "predictions": { "content_type": "text/csv; charset=utf-8", "data": "0.6380207487381995" }, "explanations": {} }
Utilisez des outils de visualisation pour vous aider à interpréter les explications renvoyées. L'image suivante montre comment les SHAP diagrammes peuvent être utilisés pour comprendre comment chaque caractéristique contribue à la prédiction. La valeur de base du diagramme, également appelée « valeur attendue », est la moyenne des prédictions du jeu de données d'entraînement. Les fonctionnalités qui poussent la valeur attendue vers le haut sont rouges, tandis que les fonctionnalités qui poussent la valeur attendue vers le bas sont bleues. Voir la disposition de la force SHAP additive
Consultez l'exemple complet de bloc-notes pour les données tabulaires
Données de texte
Cette section fournit un exemple de code permettant de créer et d'appeler un point de terminaison d'explicabilité en ligne pour les données texte. L'exemple de code est utilisé SDK pour Python.
L'exemple suivant utilise des données de texte et un SageMaker modèle appelémodel_name. Dans cet exemple, le conteneur du modèle accepte les données au CSV format, et chaque enregistrement est une chaîne unique.
endpoint_config_name = 'text_explainer_endpoint_config' response = sagemaker_client.create_endpoint_config( EndpointConfigName=endpoint_config_name, ProductionVariants=[{ 'VariantName': 'AllTraffic', 'ModelName': model_name, 'InitialInstanceCount': 1, 'InstanceType': 'ml.m5.xlarge', }], ExplainerConfig={ 'ClarifyExplainerConfig': { 'InferenceConfig': { 'FeatureTypes': ['text'], 'MaxRecordCount': 100, }, 'ShapConfig': { 'ShapBaselineConfig': { 'ShapBaseline': '"<MASK>"', }, 'TextConfig': { 'Granularity': 'token', 'Language': 'en', }, 'NumberOfSamples': 100, }, }, }, )
-
ShapBaseline: jeton spécial réservé au traitement du langage naturel (NLP). -
FeatureTypes: identifie la fonctionnalité sous forme de texte. Si ce paramètre n'est pas fourni, l'outil d'explication tente de déduire le type de fonctionnalité. -
TextConfig: spécifie l'unité de granularité et la langue pour l'analyse des fonctionnalités textuelles. Dans cet exemple, la langue est l'anglais et la valeurtokenpour la granularité signifie un mot dans un texte en anglais. -
NumberOfSamples: limite permettant de définir les limites supérieures de la taille du jeu de données synthétique. -
MaxRecordCount: nombre maximal d'enregistrements dans une demande que le conteneur de modèle peut gérer. Ce paramètre est défini pour stabiliser les performances.
Utilisez la configuration du point de terminaison pour créer le point de terminaison, comme suit :
endpoint_name = 'text_explainer_endpoint' response = sagemaker_client.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name, )
Une fois que l'état du point de terminaison est InService, appelez le point de terminaison. L'exemple de code suivant utilise un enregistrement de test comme suit :
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='"This is a good product"', )
Si la demande aboutit, le corps de la réponse renverra un JSON objet valide similaire à ce qui suit :
{ "version": "1.0", "predictions": { "content_type": "text/csv", "data": "0.9766594\n" }, "explanations": { "kernel_shap": [ [ { "attributions": [ { "attribution": [ -0.007270948666666712 ], "description": { "partial_text": "This", "start_idx": 0 } }, { "attribution": [ -0.018199033666666628 ], "description": { "partial_text": "is", "start_idx": 5 } }, { "attribution": [ 0.01970993241666666 ], "description": { "partial_text": "a", "start_idx": 8 } }, { "attribution": [ 0.1253469515833334 ], "description": { "partial_text": "good", "start_idx": 10 } }, { "attribution": [ 0.03291143366666657 ], "description": { "partial_text": "product", "start_idx": 15 } } ], "feature_type": "text" } ] ] } }
Utilisez des outils de visualisation pour vous aider à interpréter les attributions de texte renvoyées. L'image suivante montre comment l'utilitaire de visualisation captum peut être utilisé pour comprendre de quelle manière chaque terme contribue à la prédiction. Plus la saturation des couleurs est élevée, plus l'importance accordée au mot est élevée. Dans cet exemple, une couleur rouge vif très saturée indique une forte contribution négative. Une couleur verte très saturée indique une forte contribution positive. La couleur blanche indique que le mot a une contribution neutre. Consultez la bibliothèque captum

Consultez l'exemple complet de bloc-notes pour les données texte
