Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Présentation de la bibliothèque de parallélisme de données distribué basée sur l' SageMaker IA
La bibliothèque SageMaker AI Distributed Data Parallelism (SMDDP) est une bibliothèque de communication collective qui améliore les performances informatiques de l'entraînement parallèle aux données distribuées. La bibliothèque SMDDP permet de réduire la surcharge de communications liée aux principales opérations de communication collective en proposant les éléments suivants.
-
La bibliothèque propose des offres
AllReduceoptimisées pour AWS.AllReduceest une opération clé utilisée pour synchroniser les dégradés entre les GPU à la fin de chaque itération d'entraînement pendant l'entraînement aux données distribuées. -
La bibliothèque propose des offres
AllGatheroptimisées pour AWS.AllGatherest une autre opération clé utilisée dans le cadre de l'apprentissage parallèle des données partagées, une technique de parallélisme de données économe en mémoire proposée par des bibliothèques populaires telles que la bibliothèque SageMaker AI model parallelism (SMP), DeepSpeed Zero Redundancy Optimizer (Zero) et Fully Sharded Data Parallelism (FSDP). PyTorch -
La bibliothèque optimise la communication nœud à nœud en utilisant pleinement l'infrastructure AWS réseau et la topologie d'instance Amazon EC2.
La bibliothèque SMDDP peut augmenter la vitesse d’entraînement en améliorant les performances à mesure que vous faites évoluer votre cluster d’entraînement, avec une efficacité de mise à l’échelle quasi linéaire.
Note
Les bibliothèques de formation distribuées par l' SageMaker IA sont disponibles via les conteneurs d'apprentissage AWS profond PyTorch et Hugging Face de SageMaker la plateforme de formation. Pour utiliser les bibliothèques, vous devez utiliser le SDK SageMaker Python ou les SageMaker API via SDK for Python (Boto3) ou. AWS Command Line Interface Tout au long de la documentation, les instructions et les exemples se concentrent sur l'utilisation des bibliothèques de formation distribuées avec le SDK SageMaker Python.
Opérations de communication collective SMDDP optimisées pour AWS ressources informatiques et infrastructure réseau
La bibliothèque SMDDP fournit des implémentations des AllReduce opérations AllGather collectives optimisées pour les ressources AWS informatiques et l'infrastructure réseau.
Opération collective AllReduce de la bibliothèque SMDDP
La bibliothèque SMDDP réalise un chevauchement optimal des opérations AllReduce avec la transmission vers l’arrière, ce qui améliore considérablement l’utilisation du GPU. Ceci permet une efficacité de mise à l’échelle quasi linéaire et une vitesse d’entraînement plus rapide en optimisant les opérations de noyau entre les CPU et les GPU. La bibliothèque effectue l’opération AllReduce en parallèle tandis que le GPU calcule les gradients, sans supprimer de cycles GPU, ce qui permet à la bibliothèque de réaliser les entraînements plus rapidement.
-
Exploitation des CPU : la bibliothèque utilise les CPU pour les gradients
AllReduce, délestant ainsi les GPU de cette tâche. -
Utilisation améliorée des GPU : les GPU du cluster se concentrent sur le calcul des gradients, améliorant leur utilisation tout au long de l'entraînement.
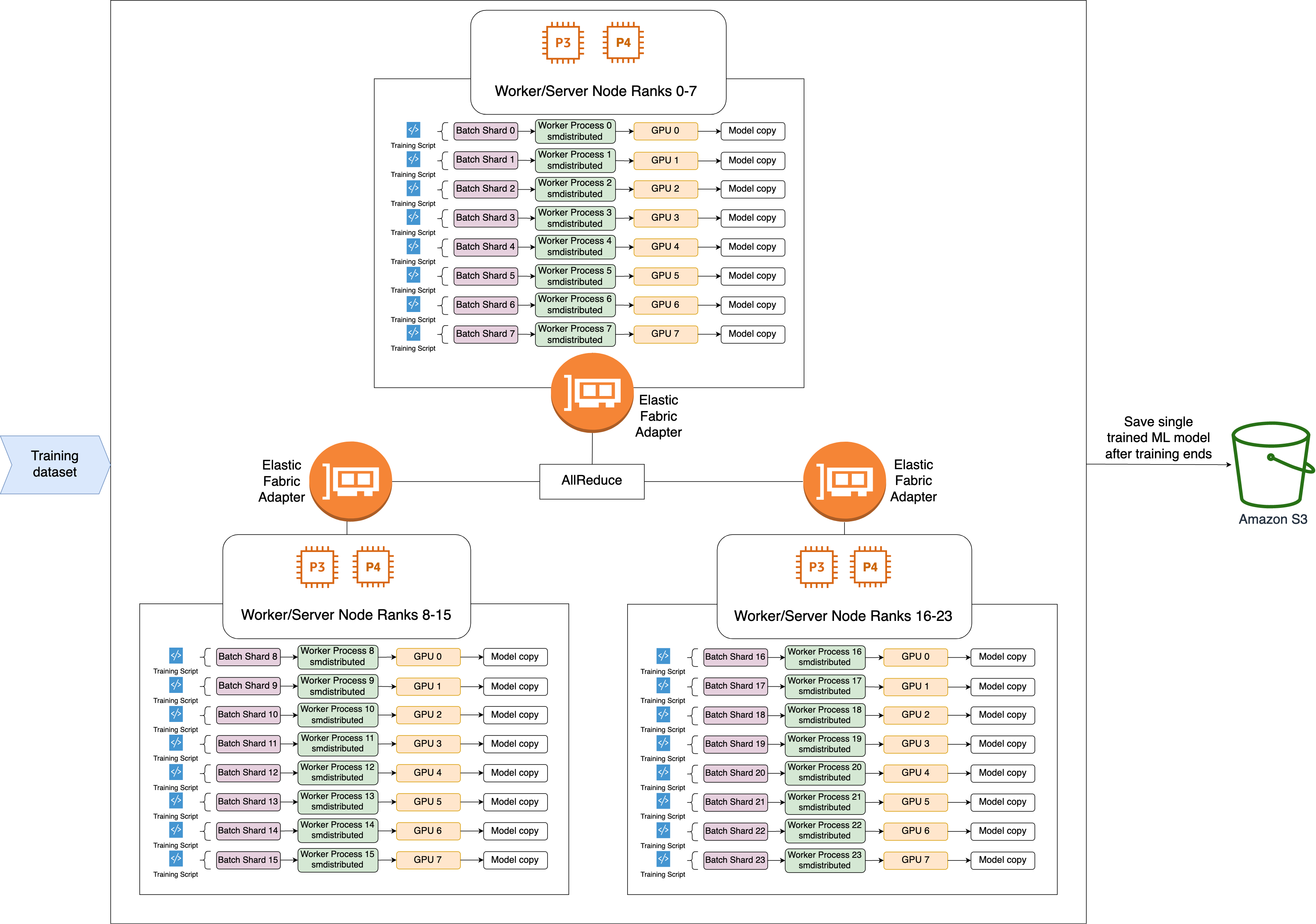
Le flux de travail de haut niveau de l’opération AllReduce de la bibliothèque SMDDP est le suivant.
-
La bibliothèque affecte des classements aux GPU (employés).
-
À chaque itération, la bibliothèque divise chaque lot global par le nombre total d'employés (taille mondiale) et affecte de petits lots (partitions de lots) aux employés.
-
Le lot global a une taille de
(number of nodes in a cluster) * (number of GPUs per node) * (per batch shard). -
Une partition de lot (petit lot) est un sous-ensemble du jeu de données affecté à chaque GPU (employé) par itération.
-
-
La bibliothèque lance un script d'entraînement sur chaque employé.
-
La bibliothèque gère les copies des poids et des gradients des modèles reçus des employés à la fin de chaque itération.
-
La bibliothèque synchronise les poids et les gradients des modèles entre les employés afin d'agréger un seul modèle entraîné.
Le diagramme d'architecture qui suit est un exemple de la façon dont la bibliothèque configure le parallélisme des données pour un cluster de 3 nœuds.
Opération collective AllGather de la bibliothèque SMDDP
AllGather est une opération collective dans laquelle chaque application de travail commence par un tampon d’entrée, puis concatène ou rassemble les tampons d’entrée de toutes les autres applications de travail dans un tampon de sortie.
Note
L'opération AllGather collective SMDDP est disponible dans AWS Deep Learning Containers (DLC) pour les versions 2.0.1 smdistributed-dataparallel>=2.0.1 et ultérieures PyTorch .
AllGather est largement utilisée dans les techniques de d’entraînement distribué telles que le parallélisme partitionné des données, où chaque application de travail détient une fraction d’un modèle, ou une couche partitionnée. Les applications de travail appellent AllGather avant les transmissions avant et arrière pour reconstruire les couches partitionnées. Les transmissions avant et arrière se poursuivent une fois que les paramètres sont tous collectés. Pendant la transmission arrière, chaque application de travail appelle également ReduceScatter pour collecter (réduire) les gradients et les répartir (disperser) en partitions de gradients afin de mettre à jour la couche partitionnée correspondante. Pour plus de détails sur le rôle de ces opérations collectives dans le parallélisme des données fragmentées, consultez l'implémentation du parallélisme des données partitionnées par la bibliothèque SMP, Zero
Comme AllGather les opérations collectives de ce type sont appelées à chaque itération, elles sont les principaux responsables de la surcharge de communication du GPU. L’accélération du calcul de ces opérations collectives se traduit directement par un temps d’entraînement plus court, sans aucun effet secondaire sur la convergence. Pour cela, la bibliothèque SMDDP propose des opérations AllGather optimisées pour les instances P4d
L’opération AllGather SMDDP utilise les techniques suivantes pour améliorer les performances de calcul sur les instances P4d.
-
Elle transfère les données entre les instances (inter-nœuds) via le réseau Elastic Fabric Adapter (EFA)
avec une topologie maillée. EFA est la solution AWS réseau à faible latence et à haut débit. Une topologie maillée pour la communication réseau entre nœuds est mieux adaptée aux caractéristiques de l'EFA et de l'infrastructure AWS réseau. Par rapport à la topologie en arborescence ou en anneau de NCCL qui implique plusieurs sauts de paquets, SMDDP évite d’accumuler la latence résultant de plusieurs sauts, car un seul est nécessaire. SMDDP implémente un algorithme de contrôle du débit réseau qui équilibre la charge de travail de chaque homologue de communication dans une topologie maillée, et permet d’obtenir un débit réseau global plus élevé. -
Il adopte une bibliothèque de copie de mémoire GPU à faible latence basée sur la technologie NVIDIA GPUDirect RDMA (GDRCopy)
pour coordonner le trafic réseau local NVLink et EFA. GDRCopy, une bibliothèque de copie de mémoire GPU à faible latence proposée par NVIDIA, fournit une communication à faible latence entre les processus du CPU et les noyaux CUDA du GPU. Grâce à cette technologie, la bibliothèque SMDDP est capable de canaliser le mouvement intra-nœud et inter-nœuds des données. -
Cela réduit l’utilisation des multiprocesseurs de streaming GPU afin d’augmenter la puissance de calcul pour exécuter les noyaux des modèles. Les instances P4d et P4de disposent de GPU NVIDIA A100, équipés chacun de 108 multiprocesseurs de streaming. Alors que NCCL utilise jusqu’à 24 multiprocesseurs de streaming pour exécuter des opérations collectives, SMDDP en utilise moins de 9. Les noyaux de calcul du modèle récupèrent les multiprocesseurs de streaming enregistrés pour accélérer les calculs.
