Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Créer et utiliser un flux Data Wrangler
Utilisez un flux Amazon SageMaker Data Wrangler, ou un flux de données, pour créer et modifier un pipeline de préparation des données. Le flux de données relie les jeux de données, les transformations et les analyses (ou étapes) que vous créez, et peut être utilisé pour définir votre pipeline.
instances
Lorsque vous créez un flux Data Wrangler dans Amazon SageMaker Studio Classic, Data Wrangler utilise une instance Amazon EC2 pour exécuter les analyses et les transformations de votre flux. Par défaut, Data Wrangler utilise l’instance m5.4xlarge. Les instances m5 sont des instances polyvalentes qui fournissent un équilibre entre le calcul et la mémoire. Vous pouvez utiliser des instances m5 pour diverses charges de travail de calcul.
Data Wrangler vous permet également d'utiliser des instances r5. Les instances r5 sont conçues pour offrir des performances rapides afin de traiter des jeux de données volumineux en mémoire.
Nous vous recommandons de choisir l’instance la mieux optimisée en fonction de vos charges de travail. Par exemple, l'instance r5.8xlarge peut être plus coûteuse que l'instance m5.4xlarge, mais elle sera peut-être mieux optimisée pour vos charges de travail. Avec des instances mieux optimisées, vous pouvez exécuter vos flux de données en moins de temps à moindre coût.
Le tableau suivant présente les instances que vous pouvez utiliser pour exécuter votre flux Data Wrangler.
| Instances standard | vCPU | Mémoire |
|---|---|---|
| ml.m5.4xlarge | 16 | 64 Go |
| ml.m5.8xlarge | 32 | 128 Gio |
| ml.m5.16xlarge | 64 |
256 Gio |
| ml.m5.24xlarge | 96 | 384 Go |
| r5.4xlarge | 16 | 128 Gio |
| r5.8xlarge | 32 | 256 Gio |
| r5.24xlarge | 96 | 768 Gio |
Pour plus d'informations sur les instances r5, consultez Instances Amazon EC2 R5
Chaque flux Data Wrangler est associé à une instance Amazon EC2. Il se peut que plusieurs flux soient associés à une seule instance.
Pour chaque fichier de flux, vous pouvez changer de type d'instance en toute transparente. Si vous changez de type d'instance, l'instance que vous avez utilisée pour exécuter le flux continue de s'exécuter.
Pour changer le type d’instance de votre flux, procédez comme suit.
-
Choisissez l’icône Exécution des terminaux et des noyaux (
 ).
). -
Accédez à l’instance que vous utilisez et choisissez-la.
-
Choisissez le type d’instance que vous souhaitez utiliser.
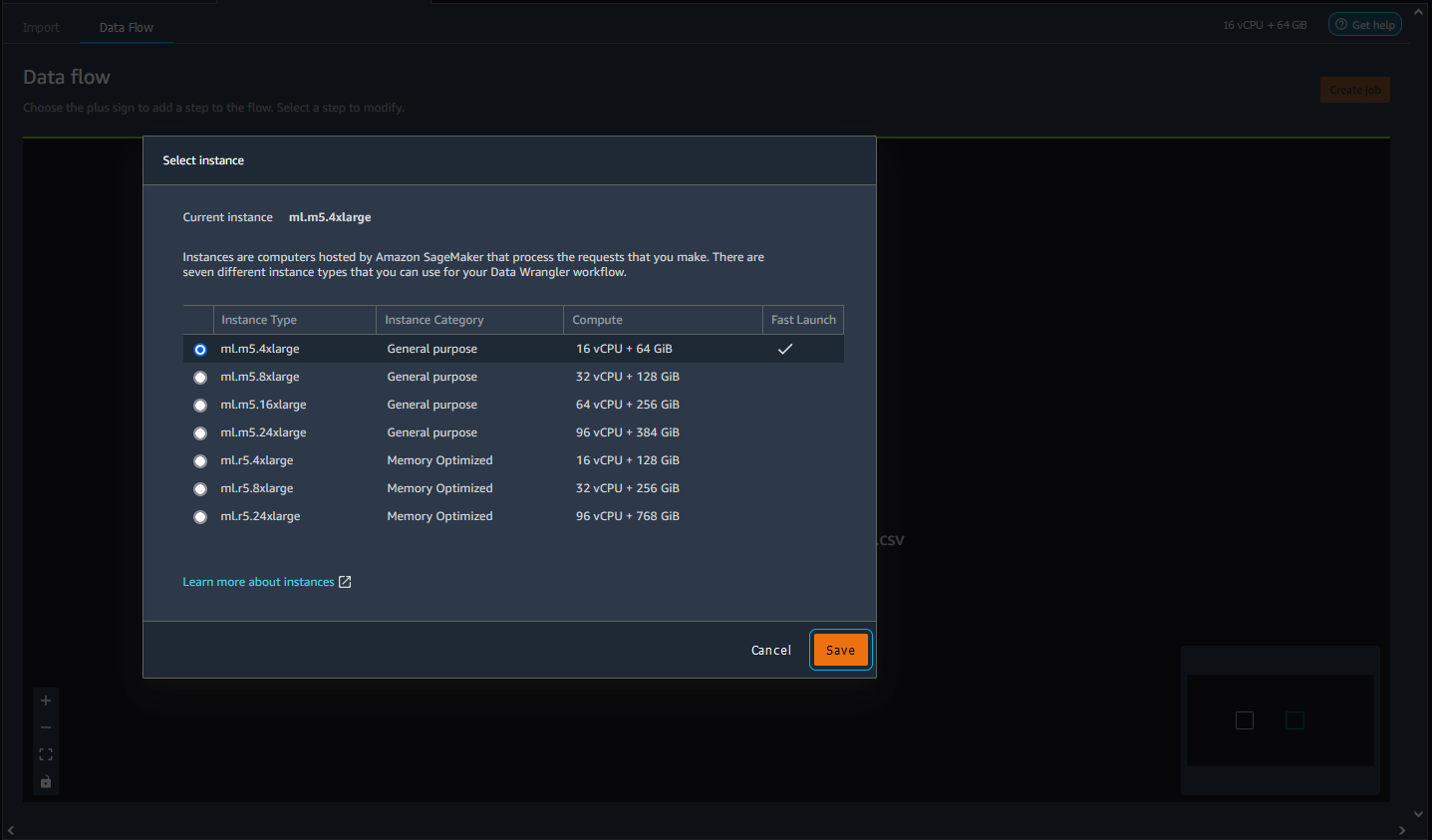
-
Choisissez Enregistrer.
Toutes les instances en cours d'exécution vous sont facturées. Pour éviter les frais supplémentaires, arrêtez manuellement les instances que vous n'utilisez pas. Pour arrêter une instance en cours d'exécution, procédez comme suit.
Pour arrêter une instance en cours d’exécution.
-
Choisissez l'icône représentant une instance. L’image suivante indique où sélectionner l’icône RUNNING INSTANCES (INSTANCES EN COURS D’EXÉCUTION).
-
Choisissez Shut down (Arrêter) en regard de l’instance que vous souhaitez arrêter.
Si vous arrêtez une instance utilisée pour exécuter un flux, vous ne pouvez temporairement pas accéder au flux. Si vous obtenez une erreur en essayant d'ouvrir le flux exécutant une instance que vous avez arrêté précédemment, patientez 5 minutes environ et essayez de l'ouvrir à nouveau.
Lorsque vous exportez votre flux de données vers un emplacement tel qu'Amazon Simple Storage Service ou Amazon SageMaker Feature Store, Data Wrangler exécute une tâche de SageMaker traitement Amazon. Vous pouvez utiliser l'une des instances suivantes pour la tâche de traitement. Pour plus d’informations sur l’exportation de vos données, consultez Exporter.
| Instances standard | vCPU | Mémoire |
|---|---|---|
| ml.m5.4xlarge | 16 | 64 Go |
| ml.m5.12xlarge | 48 |
192 Go |
| ml.m5.24xlarge | 96 | 384 Go |
Pour plus d'informations sur le coût horaire d'utilisation des types d'instances disponibles, consultez la section SageMaker Tarification
L'interface utilisateur du flux de données
Lorsque vous importez un jeu de données, le jeu de données d’origine apparaît sur le flux de données et est nommé Source. Si vous avez activé l'échantillonnage lorsque vous avez importé vos données, ce jeu de données est nommé Source - sampled (Source – échantillonnée). Data Wrangler déduit automatiquement les types de chaque colonne de votre jeu de données et crée un nouveau nom de données nommé Data types (Types de données). Vous pouvez sélectionner ce volet pour mettre à jour les types de données déduits. Vous voyez des résultats semblabes à ceux affichés dans l’image suivante après avoir téléchargé un seul jeu de données :
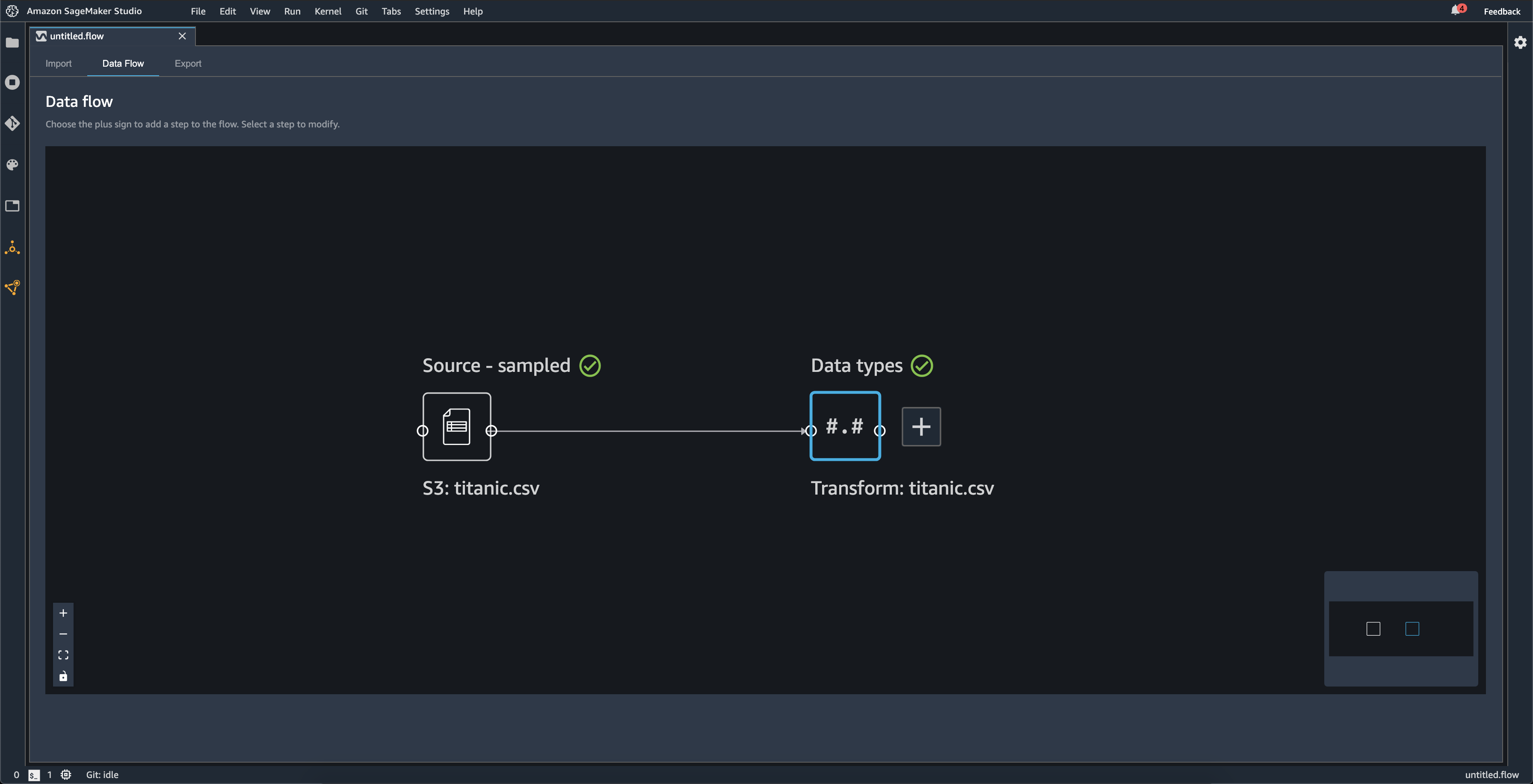
Chaque fois que vous ajoutez une étape de transformation, vous créez un nouveau nom de données. Lorsque plusieurs étapes de transformation (autres que Join (Joindre) ou Concatenate (Concaténer)) sont ajoutées au même jeu de données, elles sont empilées.
Join (Joindre) et Concatenate (Concaténer) créent des étapes autonomes contenant le nouveau jeu de données joint ou concaténé.
Le diagramme suivant montre un flux de données avec une jointure entre deux jeux de données, ainsi que deux piles d’étapes. La première pile (Steps (2)) ajoute deux transformations au type déduit dans le jeu de données Data types (Types de données). La pile en aval, ou la pile à droite, ajoute des transformations à le jeu de données résultant d’une jointure nommée demo-join.
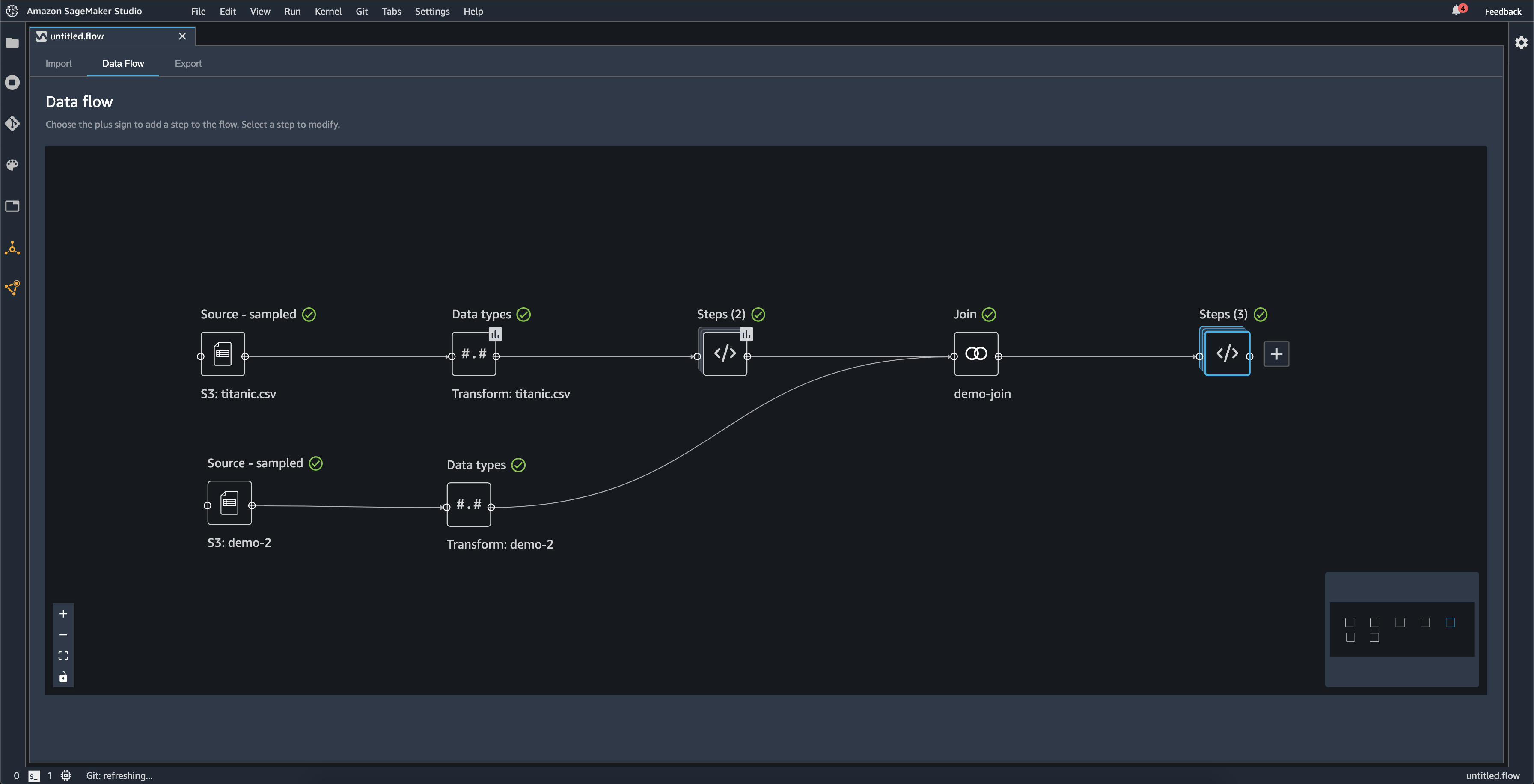
Le petit cadre gris situé dans le coin inférieur droit du flux de données fournit un aperçu du nombre de piles et d’étapes dans le flux et de la disposition du flux. La zone plus lumineuse à l’intérieur de la zone grise indique les étapes qui se trouvent dans la vue de l’interface utilisateur. Vous pouvez utiliser cette zone pour afficher les sections de votre flux de données qui ne figurent pas dans la vue de l’interface utilisateur. Utilisez l’icône Ajuster à l’écran (
 ) pour ajuster toutes les étapes et tous les jeux de données dans la vue de l’interface utilisateur.
) pour ajuster toutes les étapes et tous les jeux de données dans la vue de l’interface utilisateur.
La barre de navigation en bas à gauche comprend des icônes que vous pouvez utiliser pour effectuer un zoom avant (
 ) et arrière (
) et arrière (
 ) de votre flux de données et redimensionner le flux de données pour l’adapter à l’écran (
). Utilisez l’icône de verrouillage (
) de votre flux de données et redimensionner le flux de données pour l’adapter à l’écran (
). Utilisez l’icône de verrouillage (
 ) pour verrouiller et déverrouiller l’emplacement de chaque étape sur l’écran.
) pour verrouiller et déverrouiller l’emplacement de chaque étape sur l’écran.
Ajout d’une étape à votre flux de données
Cliquez sur le symbole + en regard d’un jeu de données ou d’une étape précédemment ajoutée, puis choisissez l’une des options suivantes :
-
Edit data types (Modifier les types de données) (seulement pour une étape Data types (Types de données)) : si vous n'avez pas ajouté de transformations dans une étape Data types (Types de données), vous pouvez sélectionner Edit data types (Modifier les types de données) pour mettre à jour les types de données déduits par Data Wrangler lors de l'importation de votre jeu de données.
-
Ajouter une transformation : ajoute une nouvelle étape de transformation. Consultez Transformation de données pour en savoir plus sur les transformations de données que vous pouvez ajouter.
-
Add analysis (Ajouter une analyse) : ajoute une analyse. Vous pouvez utiliser cette option pour analyser vos données à n'importe quel moment du flux de données. Lorsque vous ajoutez une ou plusieurs analyses à une étape, une icône d'analyse (
 ) apparaît à cette étape. Consultez Analyse et visualisation pour en savoir plus sur les analyses que vous pouvez ajouter.
) apparaît à cette étape. Consultez Analyse et visualisation pour en savoir plus sur les analyses que vous pouvez ajouter. -
Joint (Joindre) : joint deux jeux de données et ajoute le jeu de données résultant au flux de données. Pour en savoir plus, consultez Joindre des jeux de données.
-
Concatenate (Concaténer) : concatène deux jeux de données et ajoute le jeu de données résultant au flux de données. Pour en savoir plus, consultez Concaténer des jeux de données.
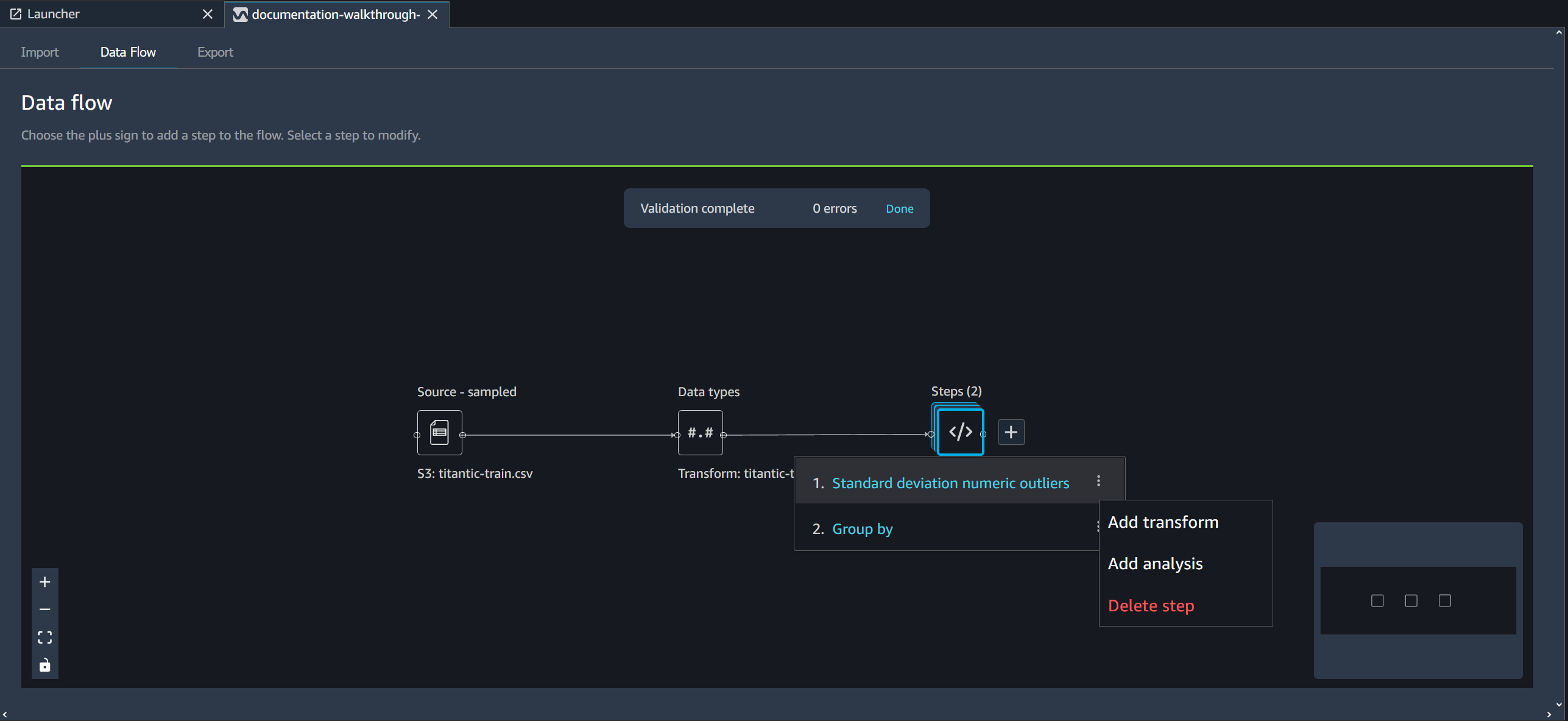
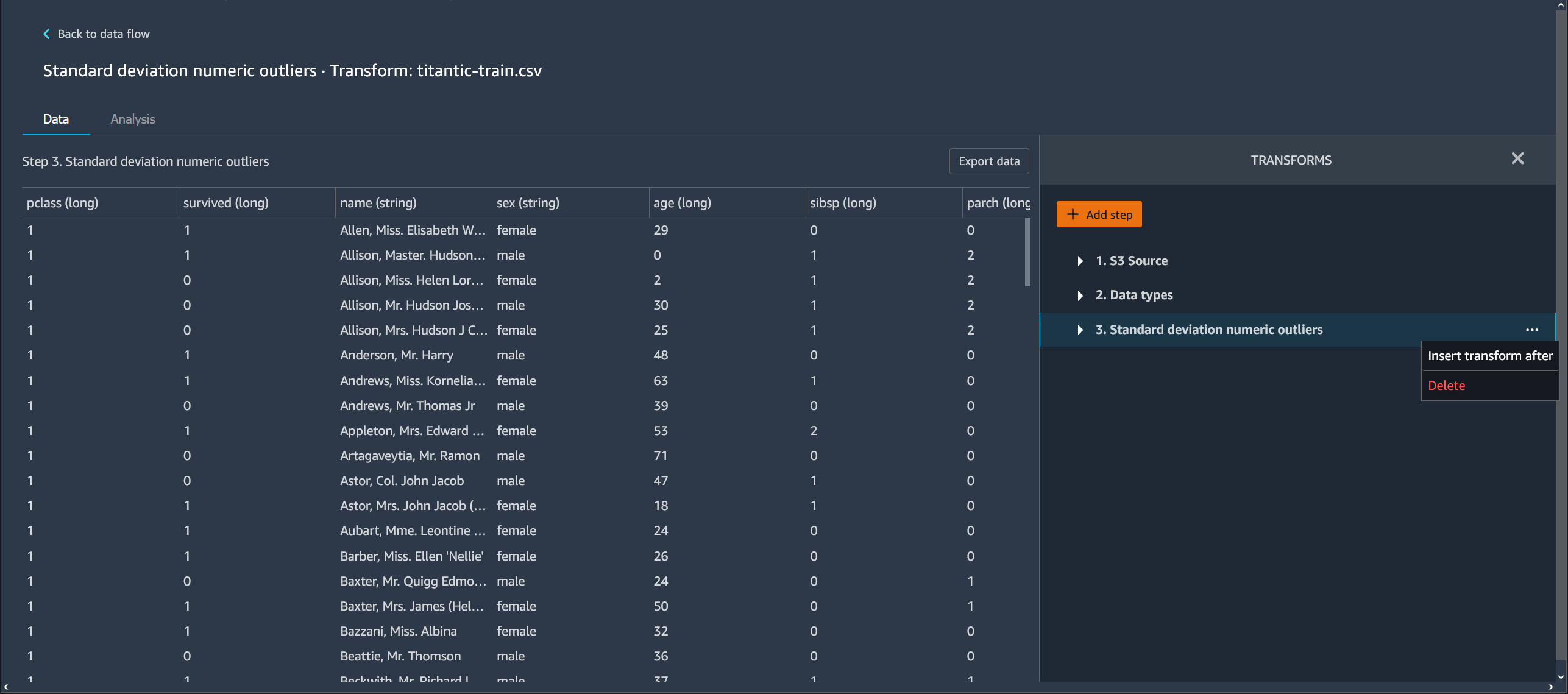
Suppression d'une étape de votre flux de données
Pour supprimer une étape, sélectionnez l’étape et sélectionnez Delete (Supprimer). Si le nœud ne contient qu'une seule entrée, vous ne supprimez que l'étape sélectionnée. La suppression d'une étape comportant une seule entrée ne supprime pas les étapes qui la suivent. Si vous supprimez une étape pour un nœud de source, de jointure ou de concaténation, toutes les étapes qui suivent sont également supprimées.
Pour supprimer une étape d’une pile d’étapes, sélectionnez la pile, puis sélectionnez l’étape à supprimer.
Vous pouvez utiliser l'une des procédures suivantes pour supprimer une étape sans supprimer les étapes en aval.
Modification d’une étape dans votre flux Data Wrangler
Vous pouvez modifier chaque étape que vous avez ajoutée au flux Data Wrangler. En modifiant les étapes, vous pouvez modifier les transformations ou les types de données des colonnes. Vous pouvez modifier les étapes pour apporter des modifications qui vous permettent d’effectuer de meilleures analyses.
Il existe de nombreuses façons de modifier une étape. Par exemple, il est possible de modifier la méthode d'imputation ou d'adapter le seuil pour qu'une valeur soit considérée comme une valeur aberrante.
Suivez la procédure ci-dessous pour modifier une étape.
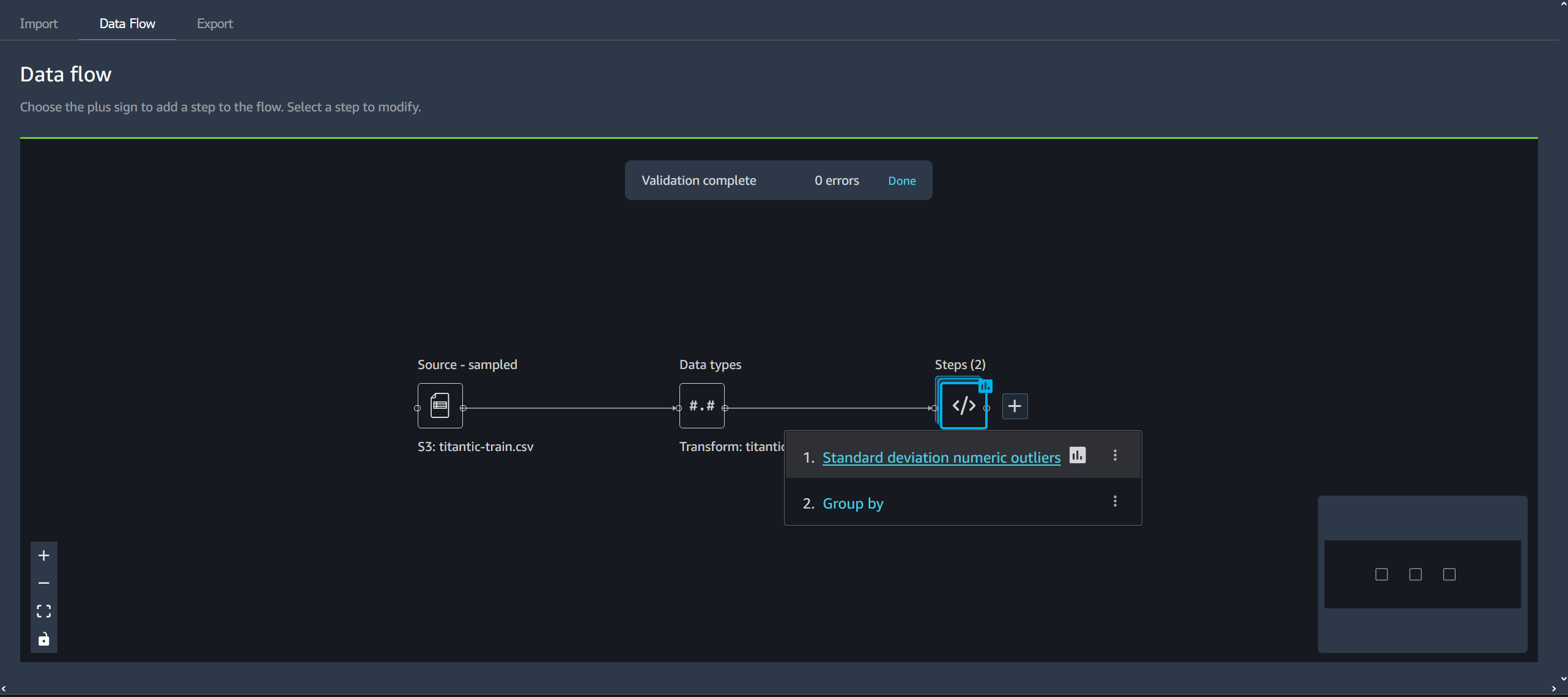
Pour modifier une étape, procédez comme suit.
-
Choisissez une étape du flux Data Wrangler pour ouvrir la vue de table.
-
Choisissez une étape dans le flux de données.
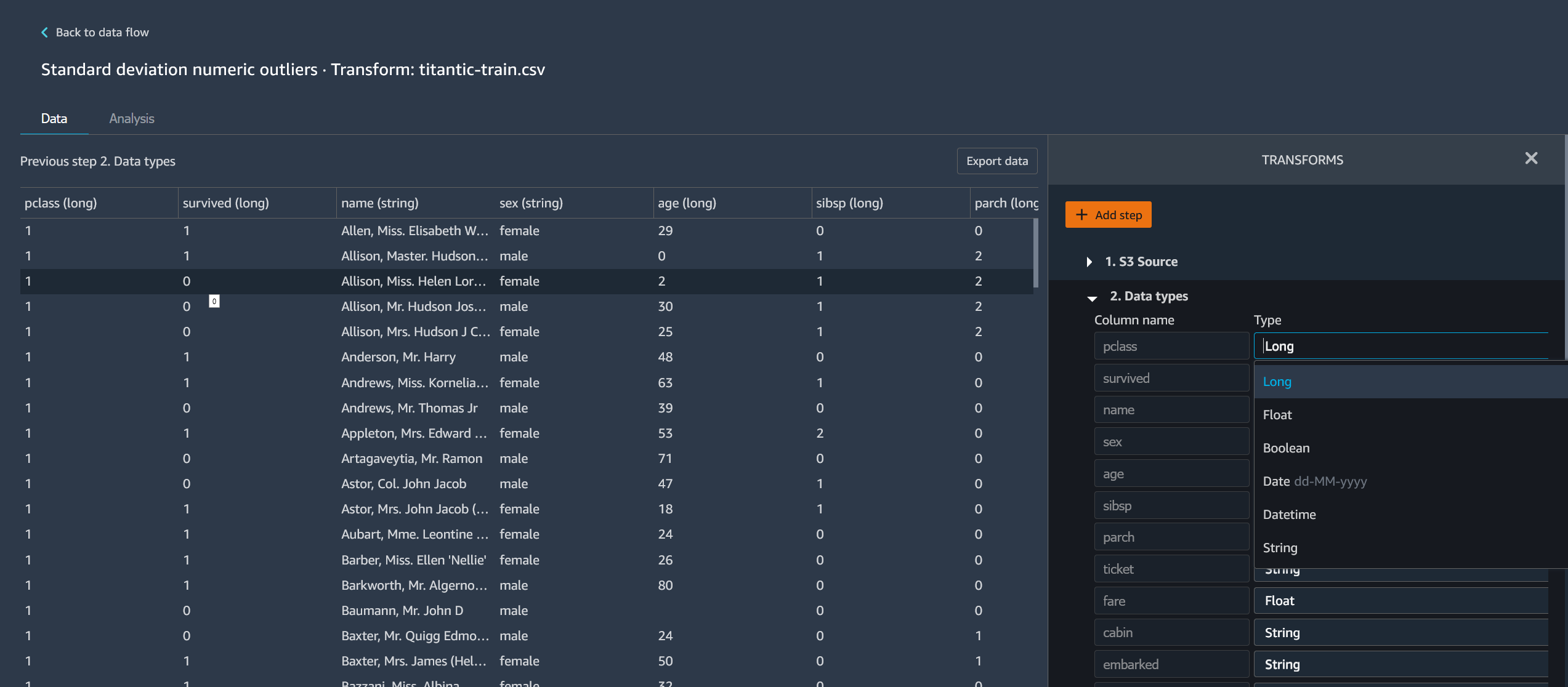
-
Modifiez l’étape.
L’image suivante montre un exemple de modification d’une étape.
Note
Vous pouvez utiliser les espaces partagés de votre domaine Amazon SageMaker AI pour travailler en collaboration sur vos flux Data Wrangler. Dans un espace partagé, vous et vos collaborateurs pouvez modifier un fichier de flux en temps réel. Toutefois, ni vous ni vos collaborateurs ne pouvez voir les modifications en temps réel. Quand quelqu'un modifie le flux Data Wrangler, il doit l'enregistrer immédiatement. Quand quelqu'un enregistre un fichier, un collaborateur ne peut pas le voir à moins de fermer le fichier et de le rouvrir. Toutes les modifications qui ne sont pas enregistrées par une personne sont remplacées par la personne qui a enregistré ses modifications.
