Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Présentation du rapport de XGBoost formation du débogueur
Cette section vous présente le rapport de XGBoost formation du Debugger. Le rapport est automatiquement agrégé en fonction de l'expression régulière du tenseur de sortie. Il reconnait le type de votre tâche d'entraînement parmi la classification binaire, la classification multiclasse et la régression.
Important
Dans le rapport, les diagrammes et les recommandations sont fournis à titre informatif et ne sont pas définitifs. Vous êtes tenu de réaliser votre propre évaluation indépendante des informations.
Rubriques
- Distribution des véritables étiquettes de l'ensemble de données
- Graphique des pertes par rapport aux échelons
- Importance des fonctionnalités
- Matrice Confusion
- Évaluation de la matrice de confusion
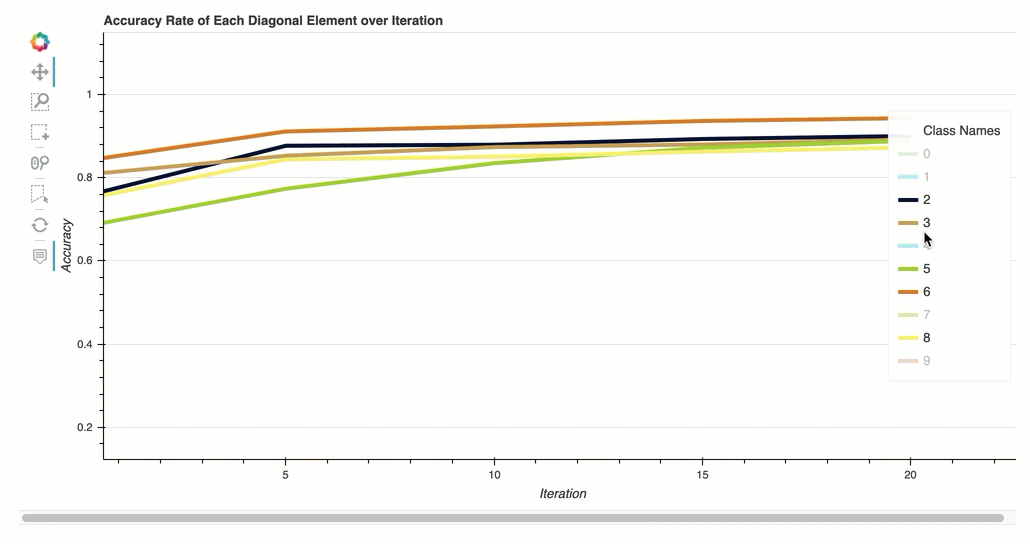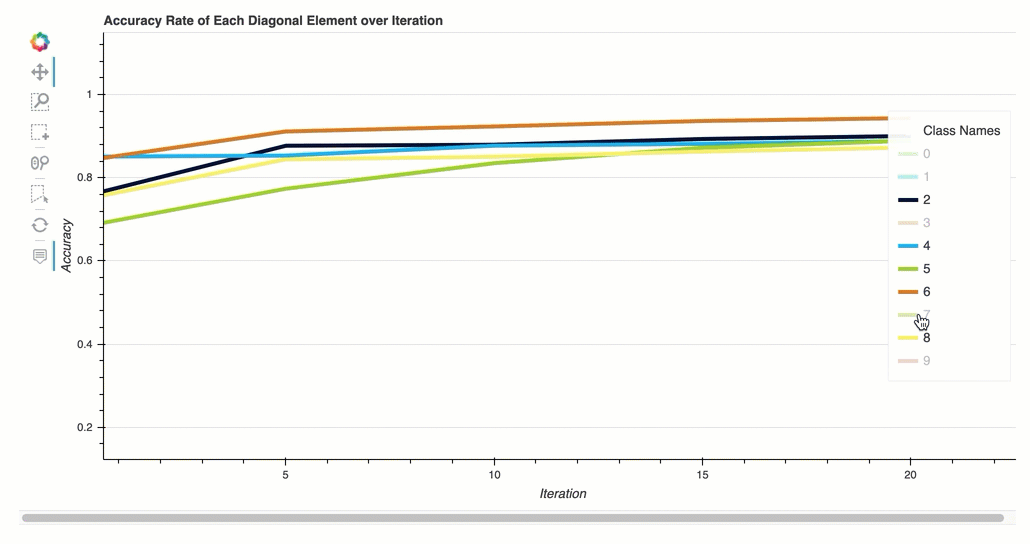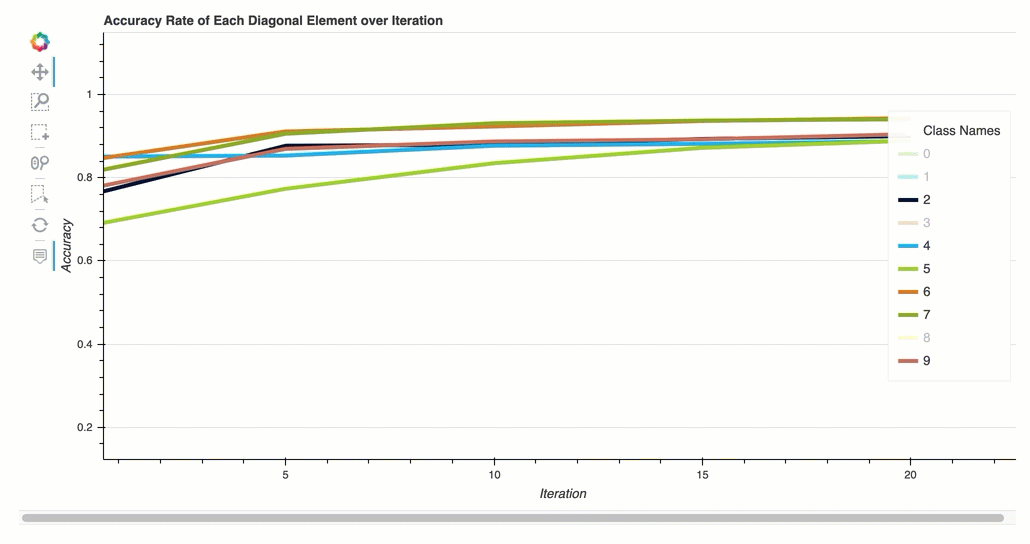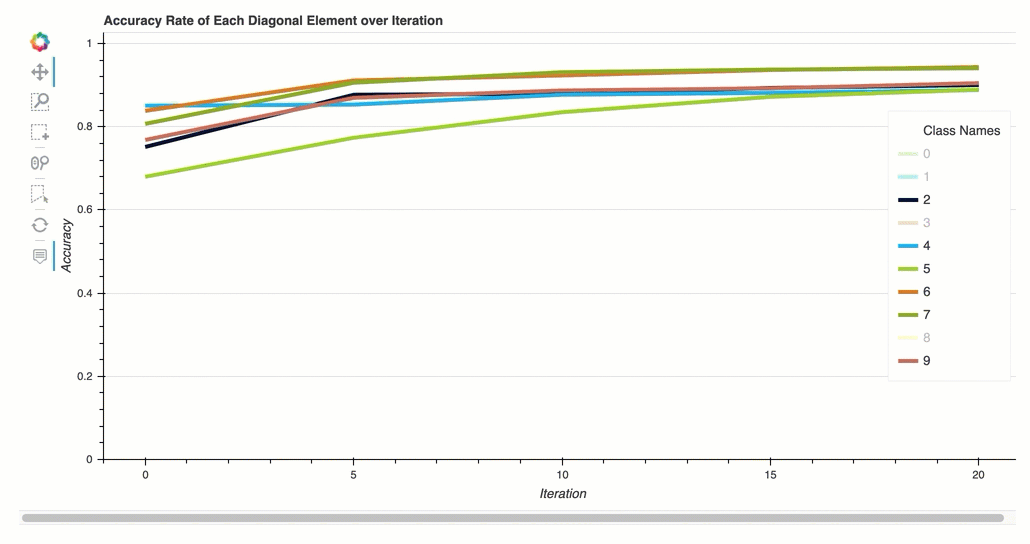
- Taux de précision de chaque élément diagonal au cours de l'itération
- Courbe caractéristique de fonctionnement du récepteur
- Répartition des valeurs résiduelles à la dernière étape enregistrée
- Erreur de validation absolue par groupe d'étiquettes au cours de l'itération
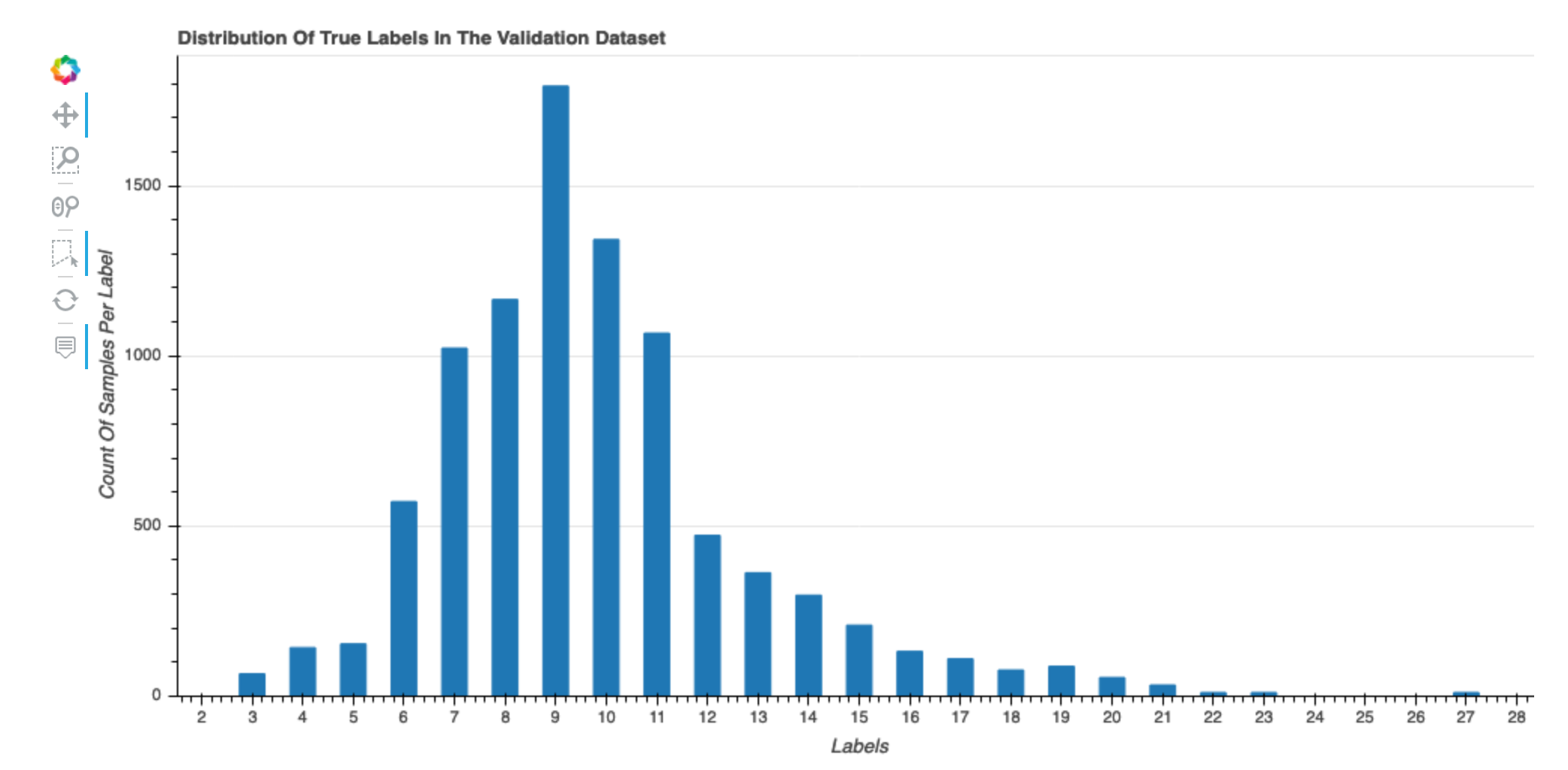
Distribution des véritables étiquettes de l'ensemble de données
Cet histogramme montre la distribution des classes étiquetées (pour la classification) ou des valeurs (pour la régression) dans votre jeu de données d'origine. L'asymétrie de votre jeu de données peut contribuer à des inexactitudes. Cette visualisation est disponible pour les types de modèles suivants : classification binaire, multiclassification et régression.
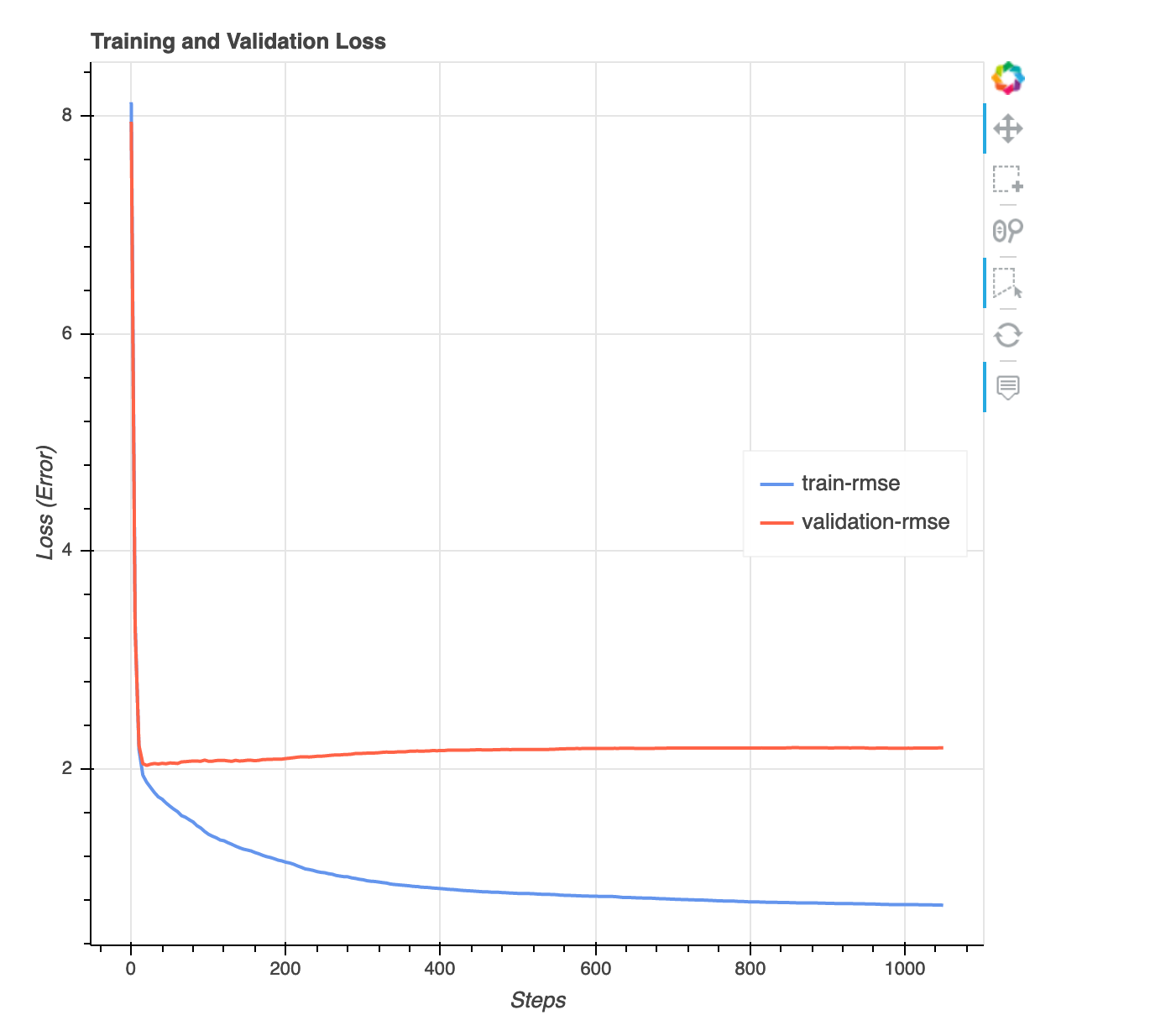
Graphique des pertes par rapport aux échelons
Il s'agit d'un graphique linéaire qui montre la progression de la perte sur les données d'entraînement et les données de validation tout au long des étapes d'entraînement. La perte est ce que vous avez défini dans votre fonction objective, comme une erreur quadratique moyenne. Vous pouvez évaluer si le modèle est trop ajusté ou inadapté à partir de ce diagramme. Cette section fournit également des informations que vous pouvez utiliser pour déterminer comment résoudre les problèmes de surajustement et de sous-ajustement. Cette visualisation est disponible pour les types de modèles suivants : classification binaire, multiclassification et régression.
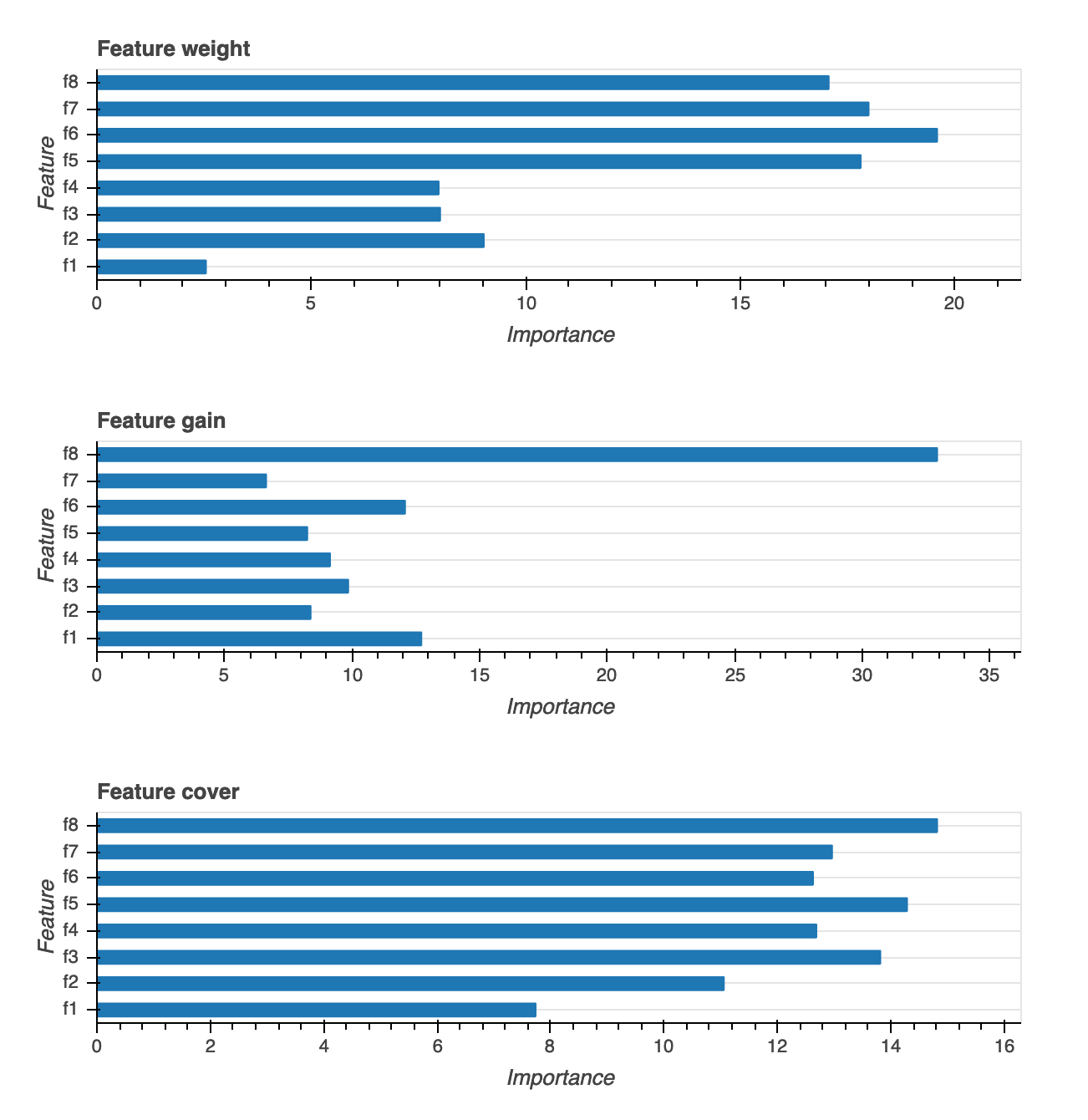
Importance des fonctionnalités
Il existe trois différents types de visualisations de l'importance des fonctions : Weight (Pondération), Gain et Coverage (Couverture). Le rapport contient des définitions détaillées pour chacune des trois fonctions. Les visualisations de l'importance des fonctions vous aident à déterminer quelles fonctions de votre jeu de données d'entraînement ont contribué aux prédictions. Les visualisations de l'importance des fonctions sont disponibles pour les types de modèles suivants : classification binaire, multiclassification et régression.
Matrice Confusion
Cette visualisation s'applique uniquement aux modèles de classification binaires et multiclasses. La précision à elle seule peut ne pas suffire à évaluer les performances du modèle. Pour certains cas d'utilisation, comme les soins de santé et la détection de fraude, il est également important de connaître le taux de faux positifs et le taux de faux négatifs. Une matrice Confusion vous donne les dimensions supplémentaires pour évaluer les performances de votre modèle.

Évaluation de la matrice de confusion
Cette section vous fournit plus d'informations sur les métriques micro, macro et pondérées en matière de précision, de rappel et de score F1 pour votre modèle.
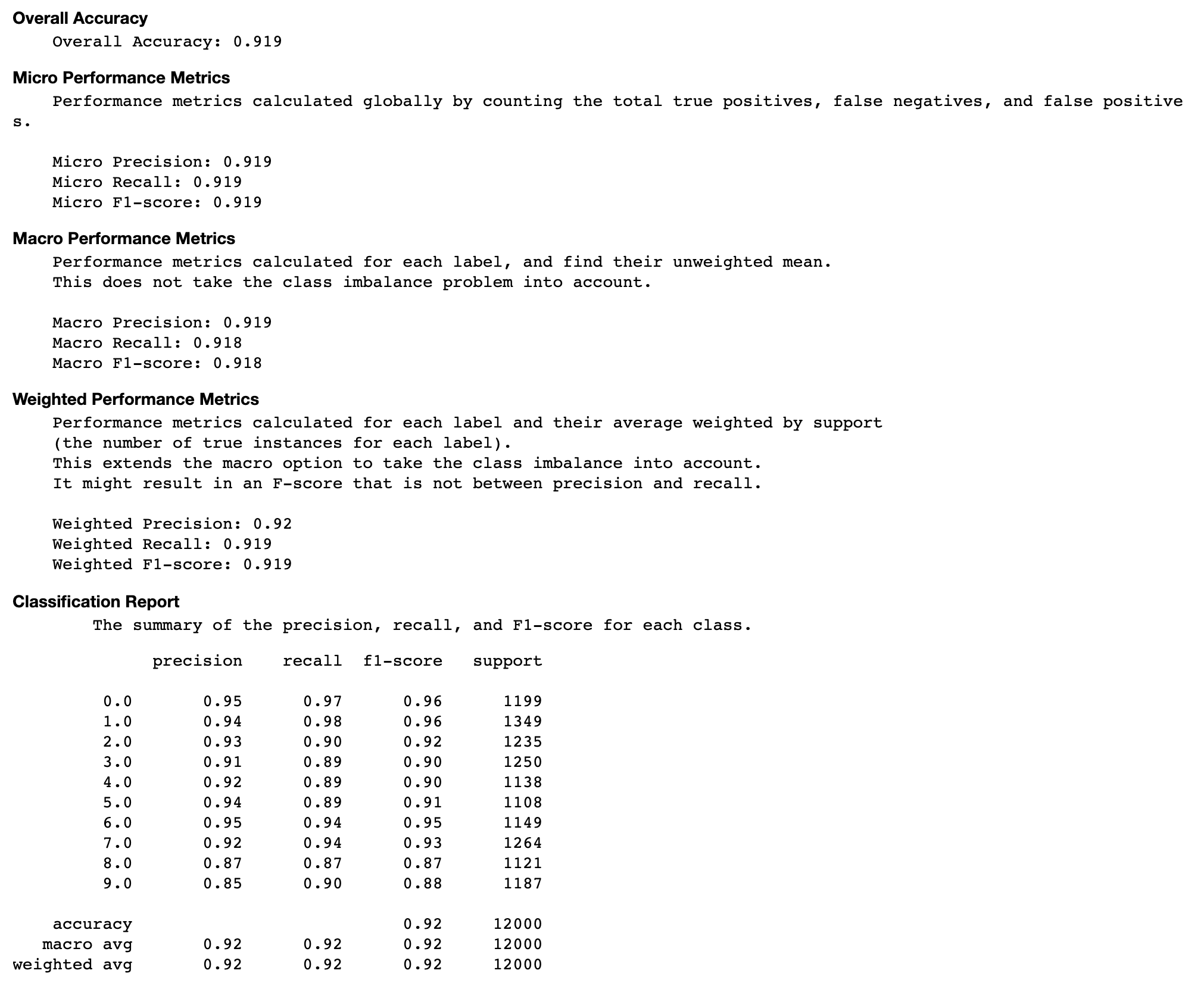
Taux de précision de chaque élément diagonal au cours de l'itération
Cette visualisation s'applique uniquement aux modèles de classification binaires et multiclasses. Il s'agit d'un graphique linéaire qui trace les valeurs diagonales de la matrice Confusion tout au long des étapes d'entraînement pour chaque classe. Ce graphique vous montre comment la précision de chaque classe progresse tout au long des étapes d'entraînement. Vous pouvez identifier les classes sous-performantes à partir de ce diagramme.
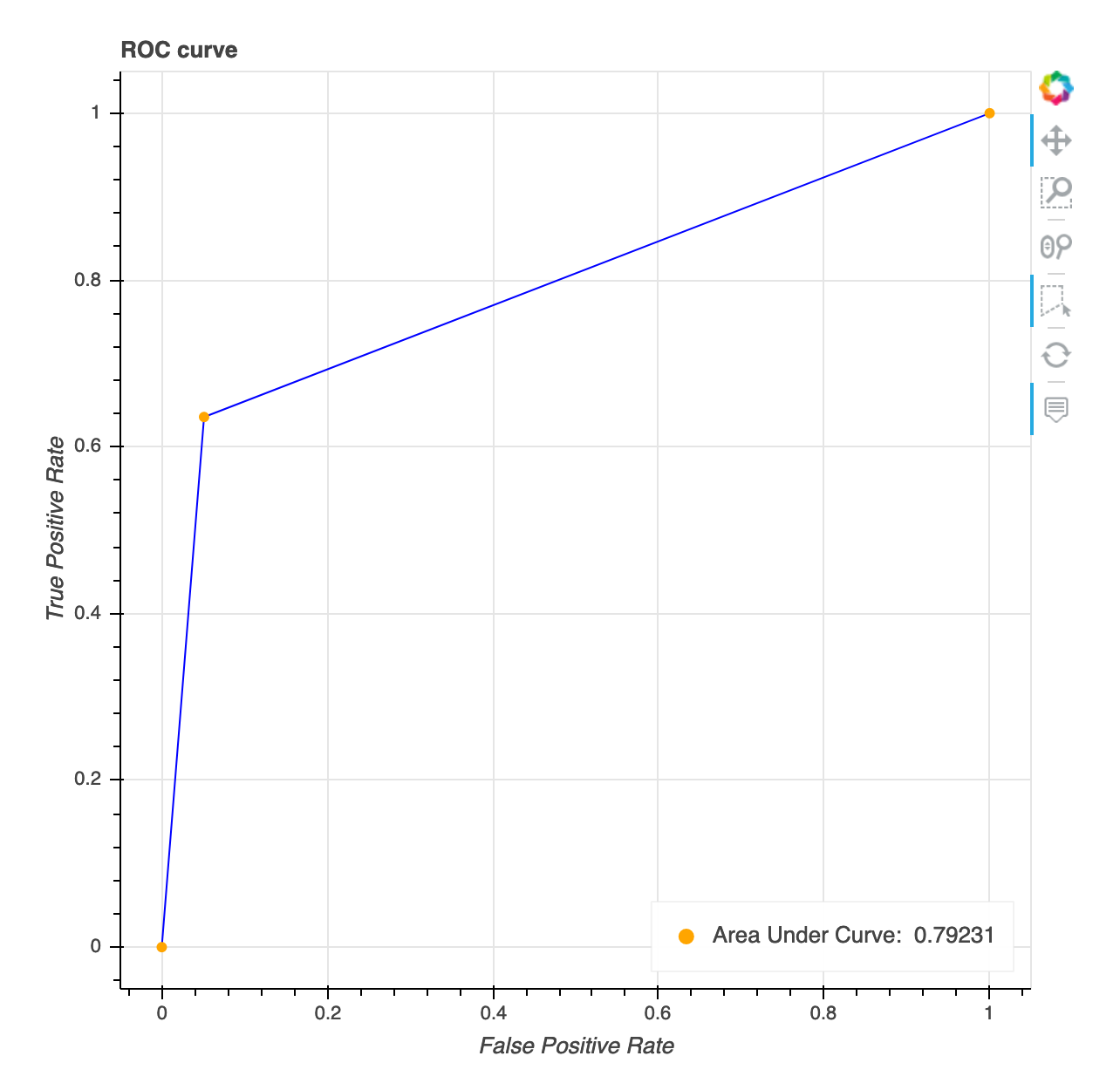
Courbe caractéristique de fonctionnement du récepteur
Cette visualisation s'applique uniquement aux modèles de classification binaire. La courbe de caractéristique de fonctionnement du récepteur est communément utilisée pour évaluer les performances du modèle de classification binaire. L'axe Y de la courbe est True Positive Rate (TPF) et l'axe X est Faussement Positive Rate ()FPR. Le graphique affiche également la valeur de la zone située sous la courbe (AUC). Plus la AUC valeur est élevée, plus votre classificateur est prédictif. Vous pouvez également utiliser la ROC courbe pour comprendre le compromis entre TPR et FPR et identifier le seuil de classification optimal pour votre cas d'utilisation. Le seuil de classification peut être modifié pour ajuster le comportement du modèle et ainsi réduire plus d'un ou un autre type d'erreur (FP/FN).
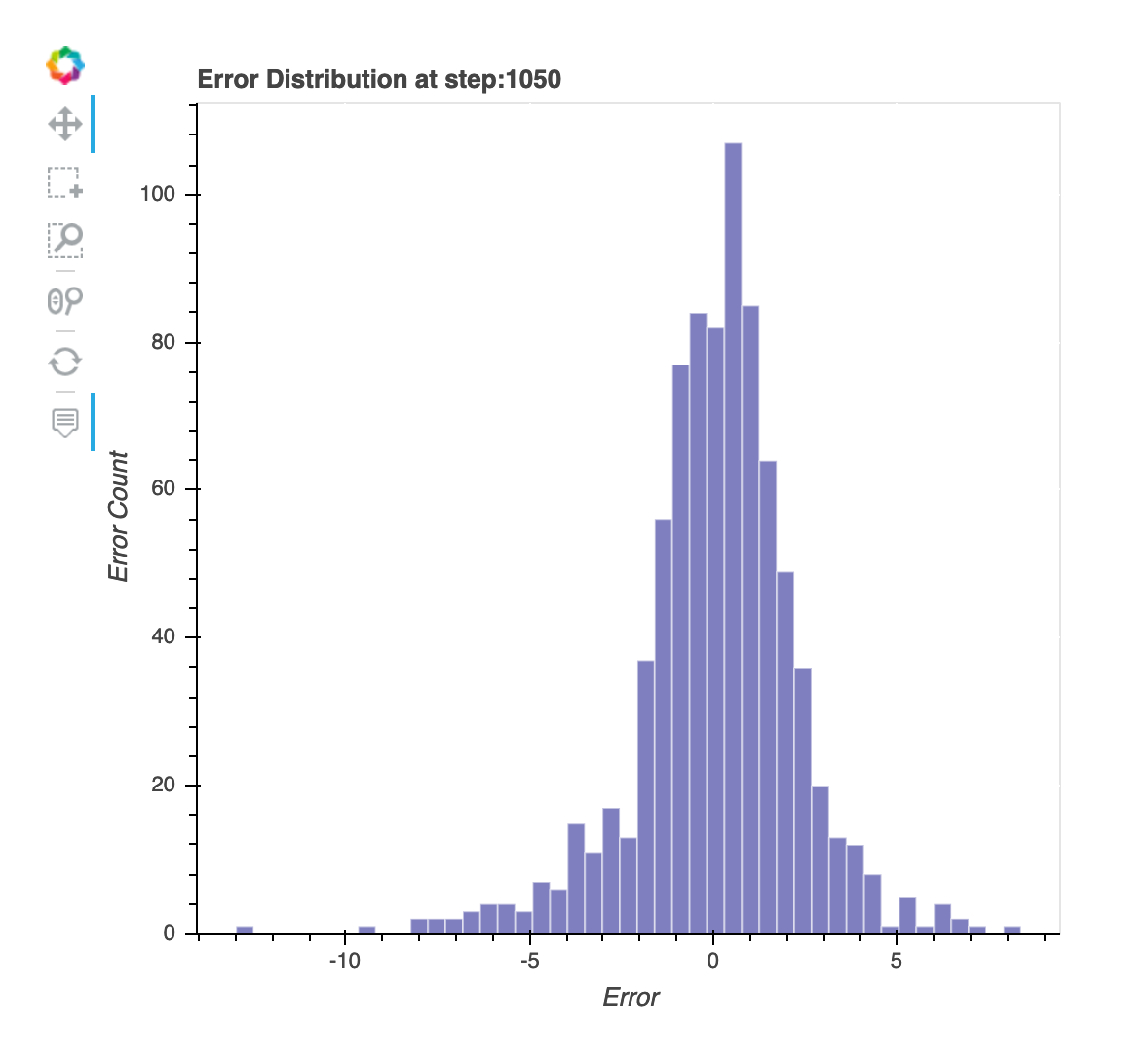
Répartition des valeurs résiduelles à la dernière étape enregistrée
Cette visualisation est un graphique en colonnes qui montre les distributions résiduelles dans la dernière étape capturée par Debugger. Dans cette visualisation, vous pouvez vérifier si la distribution résiduelle est proche de la distribution normale, centrée sur zéro. Si les valeurs résiduelles sont biaisées, il se peut que vos fonctions ne soient pas suffisantes pour prédire les étiquettes.
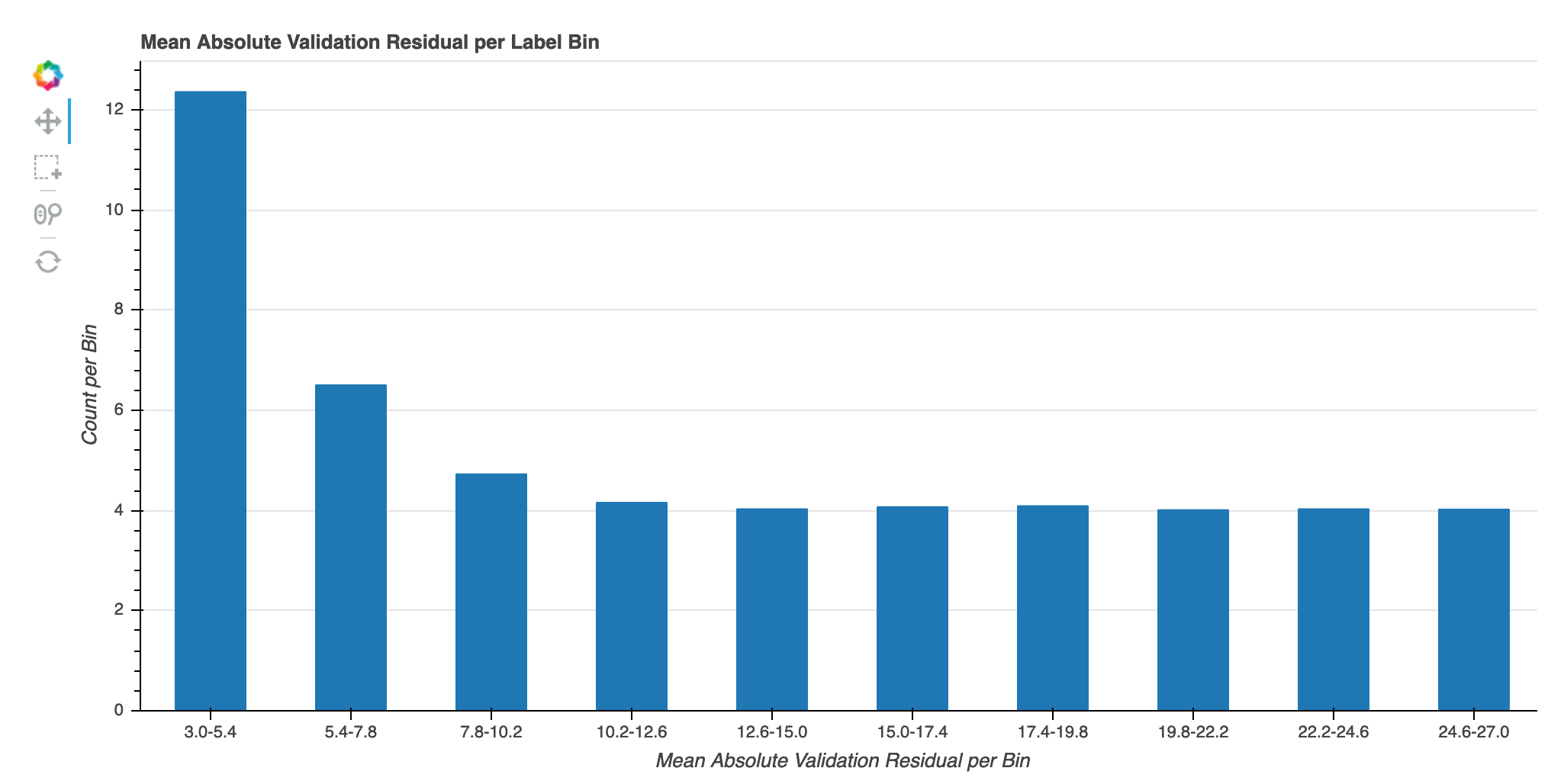
Erreur de validation absolue par groupe d'étiquettes au cours de l'itération
Cette visualisation s'applique uniquement aux modèles de régression. Les valeurs cibles réelles sont divisées en 10 intervalles. Cette visualisation montre comment les erreurs de validation progressent pour chaque intervalle tout au long des étapes d'entraînement à travers un tracé linéaire. L'erreur de validation absolue est la valeur absolue de la différence entre la prédiction et la valeur réelle pendant la validation. Vous pouvez identifier les intervalles sous-performants à partir de cette visualisation.