Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Démonstrations et visualisation avancées de Debugger
Les démonstrations suivantes vous guident dans les cas d'utilisation et les scripts de visualisation avancés à l'aide de Debugger.
Modèles d'entraînement et d'élagage avec Amazon SageMaker Experiments et Debugger
Dr. Nathalie Rauschmayr, chercheuse AWS appliquée | Durée : 49 minutes 26 secondes
Découvrez comment Amazon SageMaker Experiments et Debugger peuvent simplifier la gestion de vos tâches de formation. Amazon SageMaker Debugger fournit une visibilité transparente sur les tâches de formation et enregistre les indicateurs de formation dans votre compartiment Amazon S3. SageMaker Experiments vous permet d'appeler les informations de formation sous forme d'essais via SageMaker Studio et permet de visualiser le travail de formation. Cela contribue à préserver la qualité élevée du modèle tout en réduisant les paramètres moins importants en fonction du niveau d'importance.
Cette vidéo présente une technique d'élagage de modèles qui rend les modèles ResNet 50 et AlexNet modèles préentraînés plus légers et abordables tout en respectant des normes élevées en matière de précision des modèles.
SageMaker AI Estimator entraîne les algorithmes fournis par le zoo de PyTorch modèles dans un PyTorch framework AWS Deep Learning Containers, et Debugger extrait les métriques d'entraînement du processus d'entraînement.
La vidéo montre également comment configurer une règle personnalisée du Debugger pour vérifier la précision d'un modèle élagué, pour déclencher un CloudWatch événement Amazon et une AWS Lambda fonction lorsque la précision atteint un seuil, et pour arrêter automatiquement le processus d'élagage afin d'éviter les itérations redondantes.
Les objectifs d'apprentissage sont les suivants :
-
Découvrez comment utiliser l' SageMaker IA pour accélérer la formation des modèles de machine learning et améliorer la qualité des modèles.
-
Découvrez comment gérer les itérations d'entraînement avec SageMaker Experiments en capturant automatiquement les paramètres d'entrée, les configurations et les résultats.
-
Découvrir comment Debugger rend le processus d'entraînement transparent en capturant automatiquement les données des tenseurs en temps réel à partir de métriques telles que les pondérations, les gradients et les sorties d'activation des réseaux de neurones convolutifs.
-
CloudWatch À utiliser pour déclencher Lambda lorsque Debugger détecte des problèmes.
-
Maîtrisez le processus de SageMaker formation à l'aide d' SageMaker Experiments et de Debugger.
Vous trouverez les blocs-notes et les scripts de formation utilisés dans cette vidéo de SageMaker Debugger PyTorch Iterative
L'image suivante montre comment le processus d'élagage itératif du modèle réduit la taille de AlexNet en supprimant les 100 filtres les moins significatifs en fonction du rang d'importance évalué par les résultats d'activation et les dégradés.
Le processus de réduction a réduit le nombre initial de 50 millions de paramètres à 18 millions. Il a également réduit la taille estimée du modèle de 201 Mo à 73 Mo.
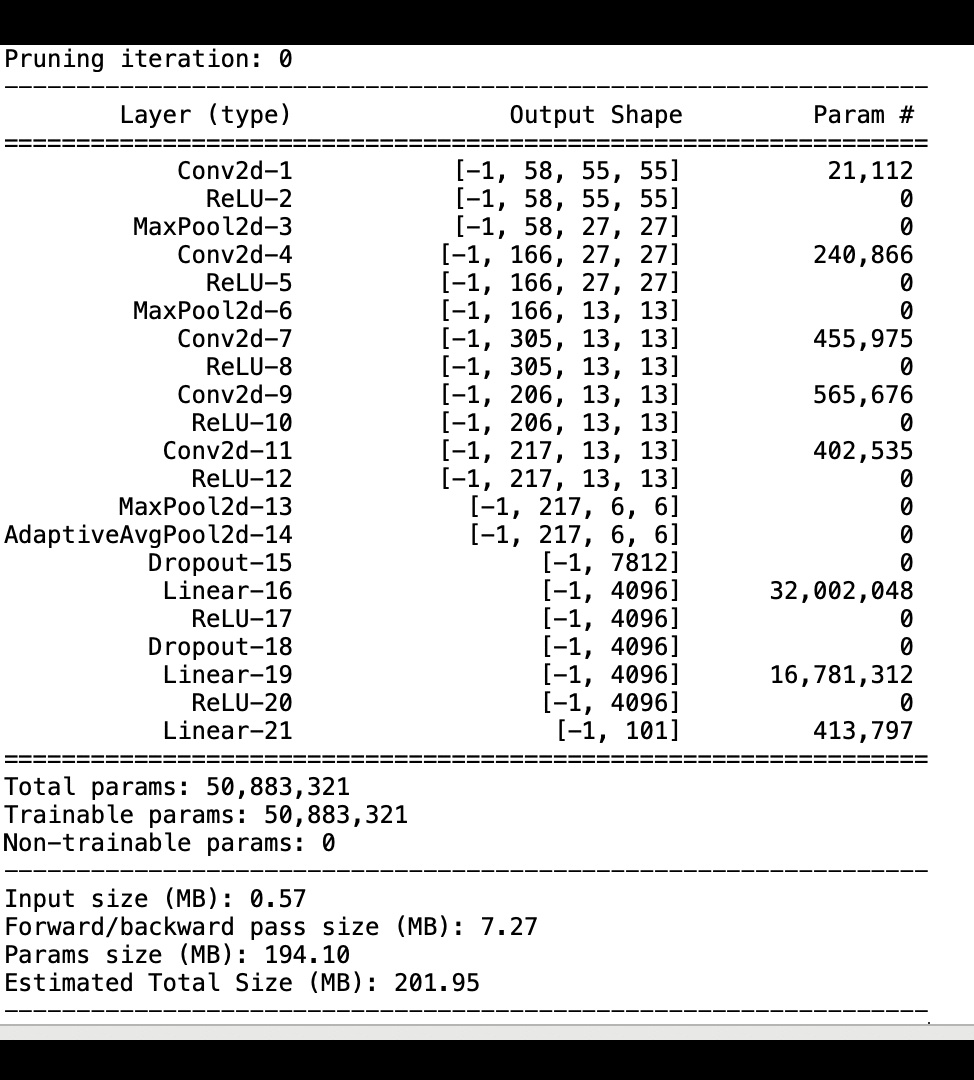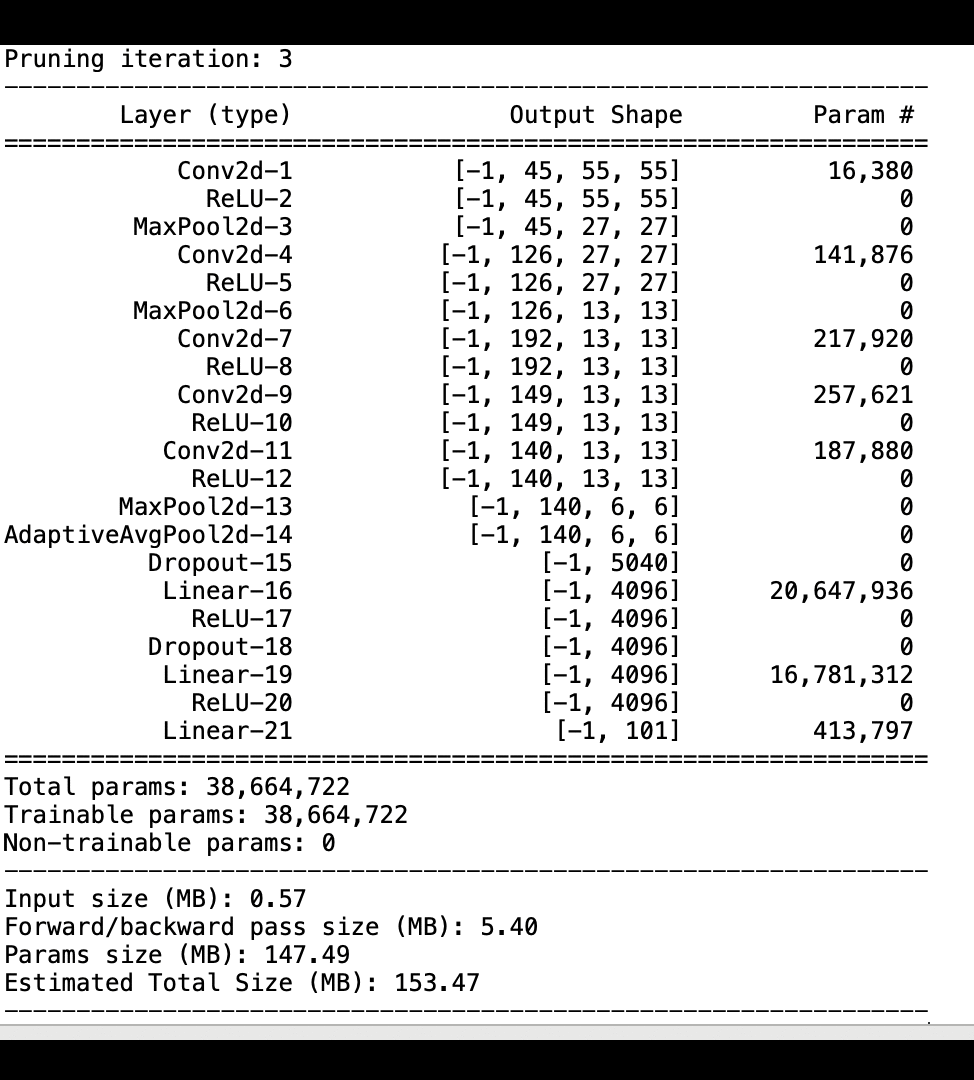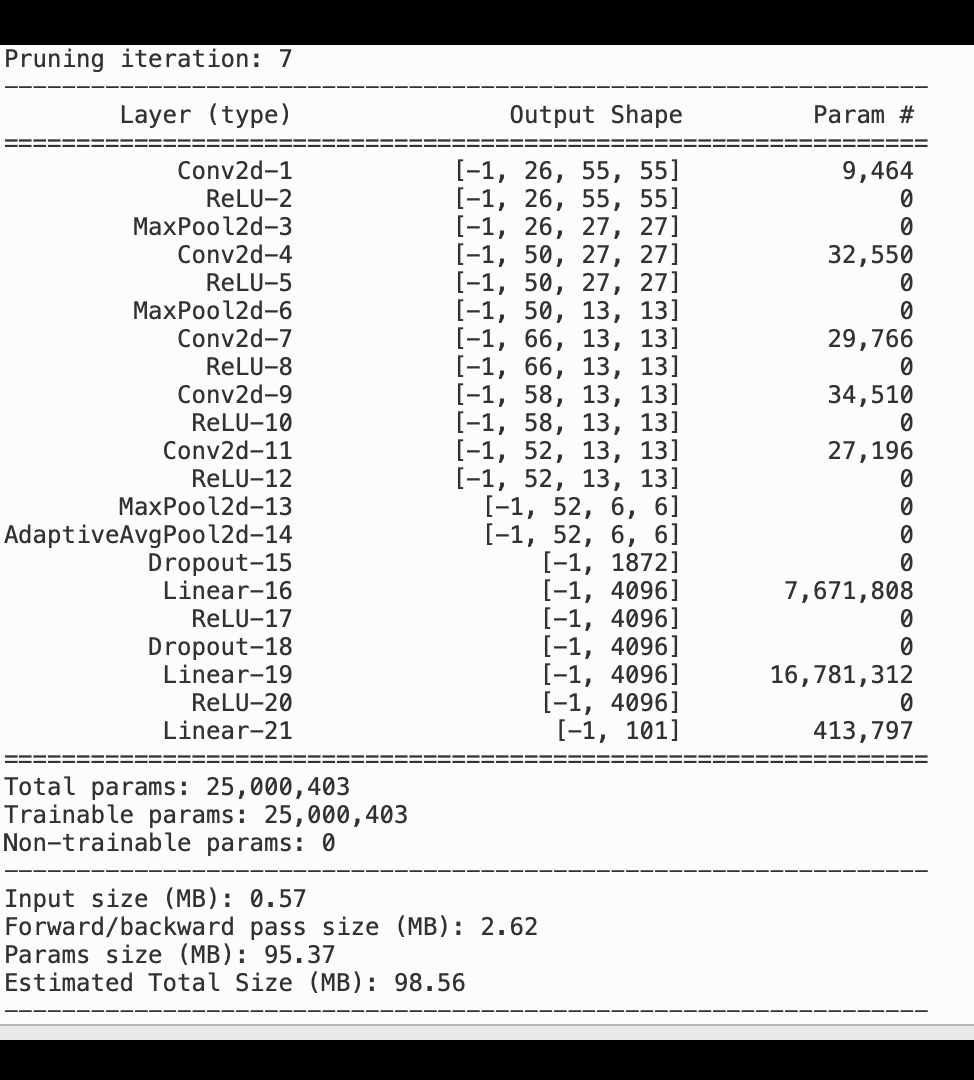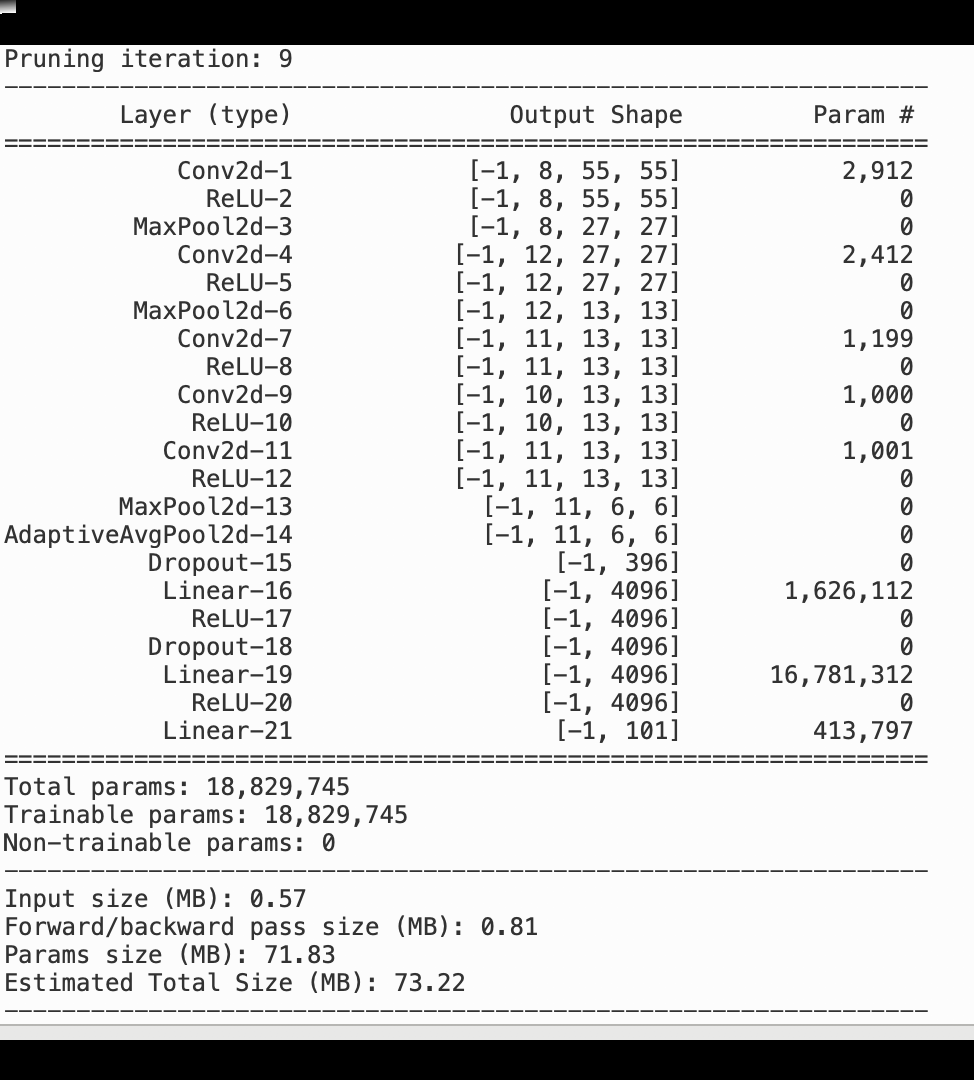
Vous devez également suivre la précision du modèle. L'image suivante montre comment tracer le processus d'élagage du modèle pour visualiser les modifications de la précision du modèle en fonction du nombre de paramètres dans SageMaker Studio.
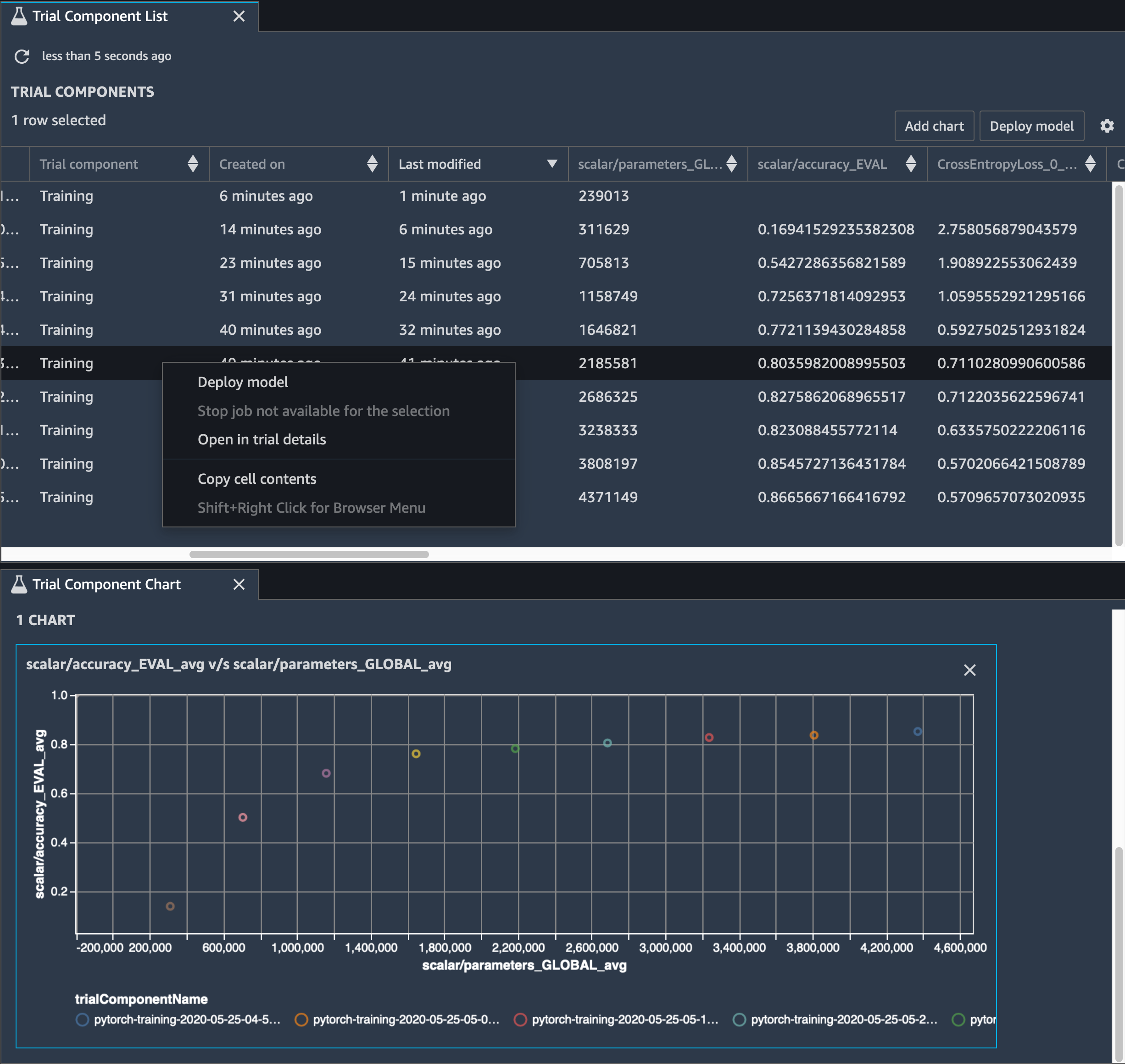
Dans SageMaker Studio, choisissez l'onglet Experiments, sélectionnez une liste de tenseurs enregistrés par Debugger lors du processus d'élagage, puis composez un panneau de liste des composants d'essai. Sélectionnez les dix itérations et choisissez Add chart (Ajouter un graphique) pour créer un Trial Component Chart (Graphique de composants d'essai). Une fois que vous avez choisi le modèle à déployer, choisissez le composant d'essai et un menu permettant d'effectuer une action ou choisissez Deploy model (Déployer le modèle).
Note
Pour déployer un modèle via SageMaker Studio à l'aide de l'exemple de bloc-notes suivant, ajoutez une ligne à la fin de la train fonction dans le train.py script.
# In the train.py script, look for the train function in line 58. def train(epochs, batch_size, learning_rate): ... print('acc:{:.4f}'.format(correct/total)) hook.save_scalar("accuracy", correct/total, sm_metric=True) # Add the following code to line 128 of the train.py script to save the pruned models # under the current SageMaker Studio model directorytorch.save(model.state_dict(), os.environ['SM_MODEL_DIR'] + '/model.pt')
Utilisation du SageMaker débogueur pour surveiller l'entraînement d'un modèle d'encodeur automatique convolutif
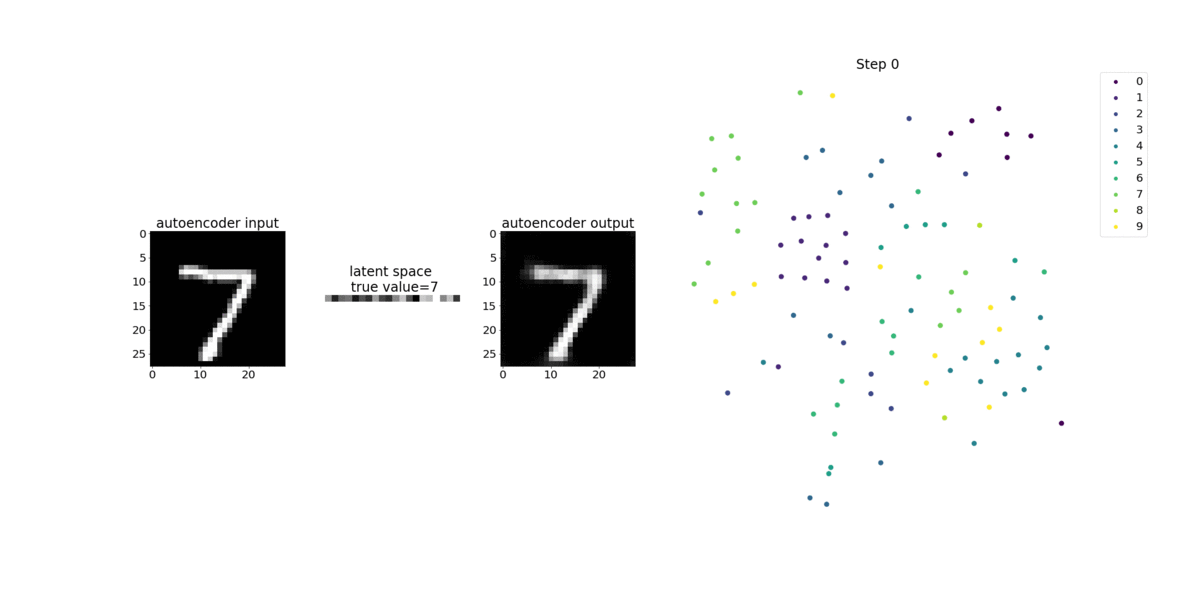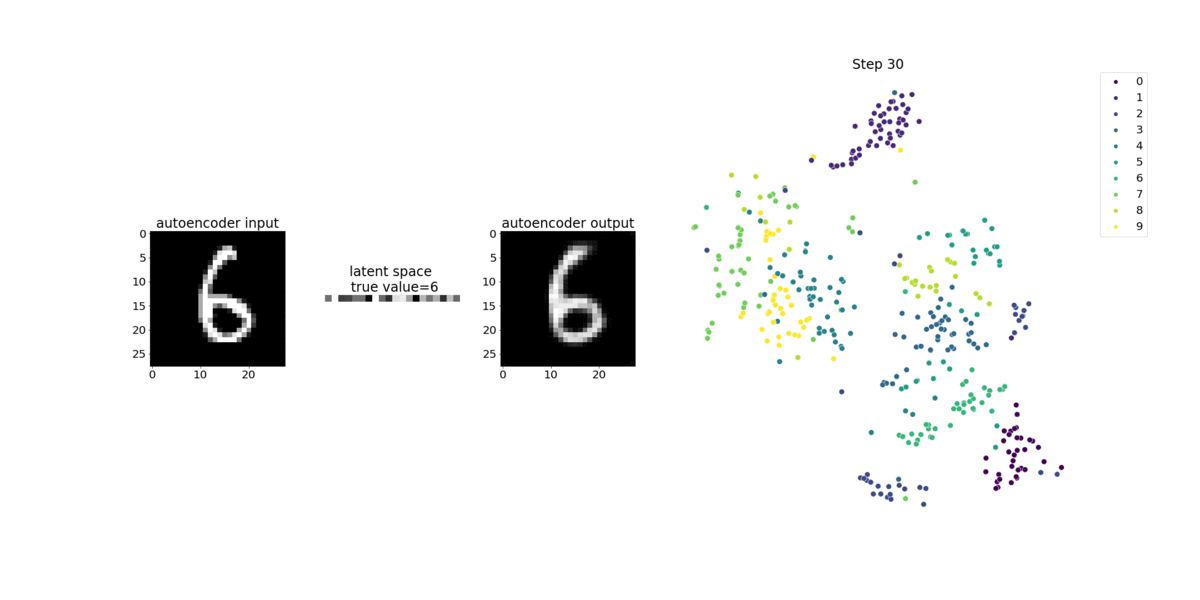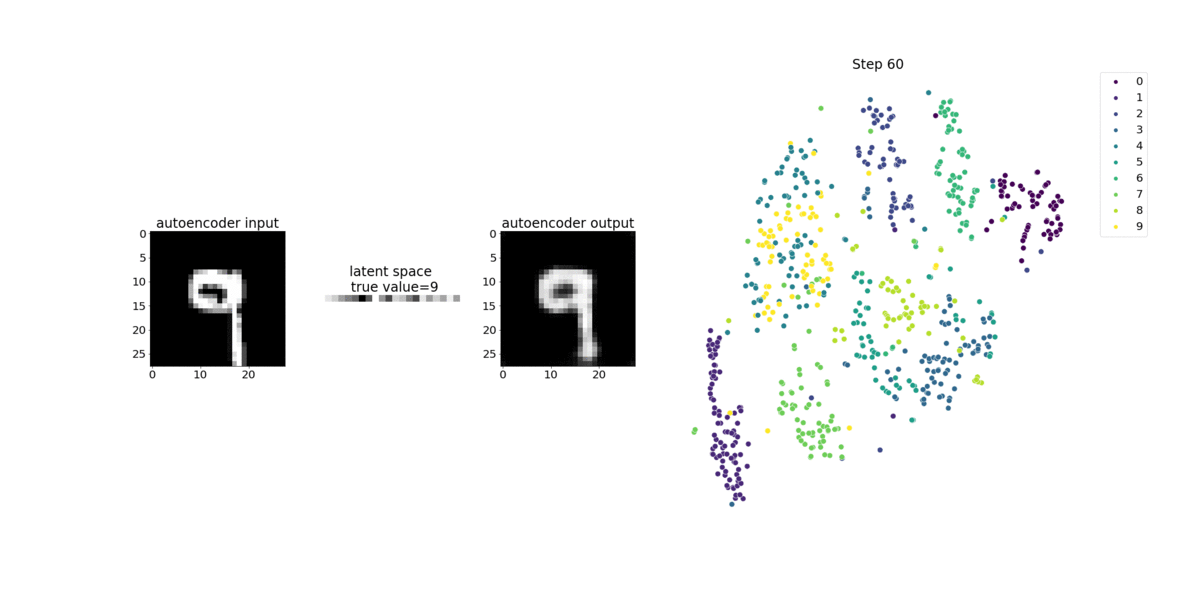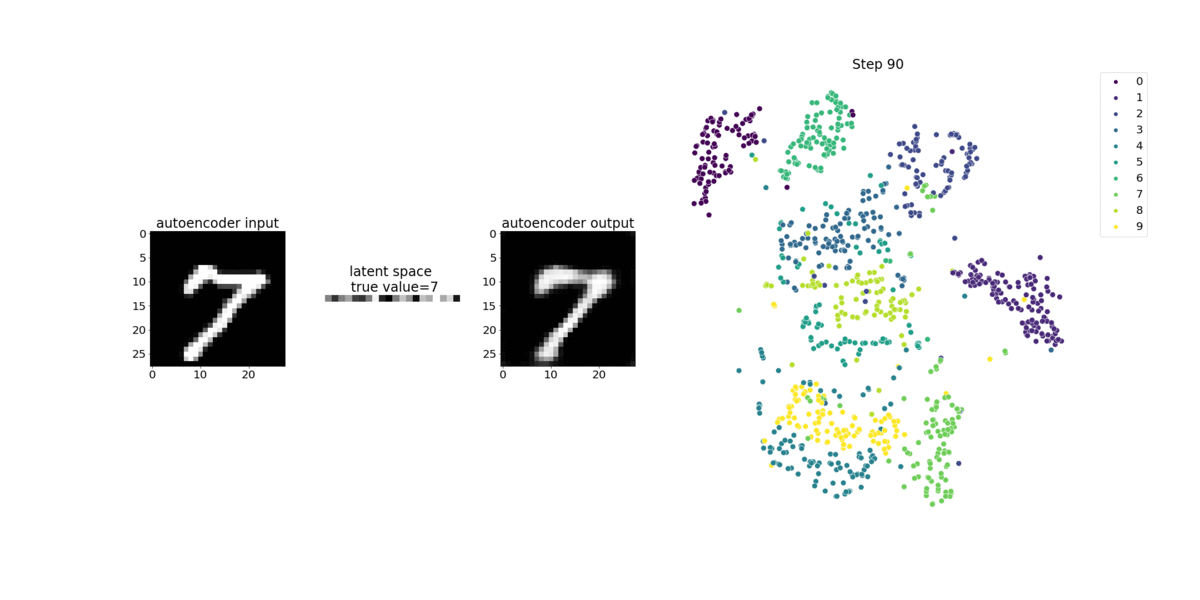
Ce bloc-notes montre comment SageMaker Debugger visualise les tenseurs issus d'un processus d'apprentissage non supervisé (ou autosupervisé) sur un jeu de données d'images MNIST contenant des nombres écrits à la main.
Le modèle d'entraînement de ce bloc-notes est un auto-encodeur convolutif avec le framework MxNet. L’auto-encodeur convolutif a un réseau neuronal convolutif en forme de goulet d’étranglement qui se compose d’une partie encodeur et d’une partie décodeur.
L'encodeur de cet exemple comporte deux couches de convolution pour produire une représentation compressée (variables latentes) des images en entrée. Dans ce cas, l'encodeur produit une variable latente de taille (1, 20) à partir d'une image d'entrée d'origine de taille (28, 28) et réduit considérablement la taille des données pour l'entraînement, de l'ordre de 40 fois.
Le décodeur dispose de deux couches déconvolutives et garantit que les variables latentes conservent les informations clés en reconstruisant les images de sortie.
L'encodeur convolutif alimente les algorithmes de clustering avec une taille de données d'entrée plus petite, ainsi que les performances des algorithmes de clustering tels que k-moyennes (k-means), k-nn et T-SNE (Stochastic Neighbor Embedding) distribuée.
Cet exemple de bloc-notes montre comment visualiser les variables latentes à l'aide de Debugger, comme illustré dans l'animation suivante. Il montre également comment l'algorithme T-SNE classe les variables latentes en dix groupes et les projette dans un espace à deux dimensions. Le diagramme de points en couleur situé sur la droite de l'image reflète les vraies valeurs pour montrer l'efficacité de l'organisation des variables latentes dans les clusters par le modèle BERT et l'algorithme T-SNE.
Utilisation du SageMaker débogueur pour surveiller les attentions lors de l'entraînement du modèle BERT
Le modèle BERT (Bidirectional Encode Representations from Transformers) est un modèle de représentation linguistique. Comme le reflète son nom, le modèle BERT s'appuie sur l'apprentissage par transfert et sur le modèle de transformateur pour le traitement du langage naturel.
Le modèle BERT est préentraîné pour des tâches non supervisées, comme la prédiction des mots manquants dans une phrase ou la prédiction de la phrase qui suit naturellement une phrase. Les données d'entraînement contiennent 3,3 milliards de mots (jetons) de texte anglais, provenant de sources telles que Wikipédia et des livres électroniques. Pour vous donner un exemple simple, le modèle BERT peut accorder une grande attention aux jetons de verbe appropriés ou aux jetons de pronom d'un jeton sujet.
Le modèle BERT préentraîné peut être affiné à l'aide d'une couche de sortie supplémentaire afin d'obtenir un entraînement du modèle de pointe dans les tâches de traitement du langage naturel, par exemple des réponses automatiques à des questions, la classification de textes, etc.
Debugger collecte les tenseurs du processus de réglage précis. Dans le contexte du traitement du langage naturel, la pondération des neurones est appelée attention.
Ce carnet explique comment utiliser le modèle BERT préentraîné du zoo de modèles GluonNLP sur l'ensemble
Le tracé des scores d'attention et des neurones individuels dans la requête et les vecteurs clés peut aider à identifier les causes de prédictions erronées du modèle. Avec SageMaker AI Debugger, vous pouvez récupérer les tenseurs et tracer la vue attention-tête en temps réel au fur et à mesure que l'entraînement progresse et comprendre ce que le modèle apprend.
L'animation suivante montre les scores d'attention des 20 premiers jetons d'entrée pour dix itérations dans la tâche d'entraînement fournie dans l'exemple de bloc-notes.
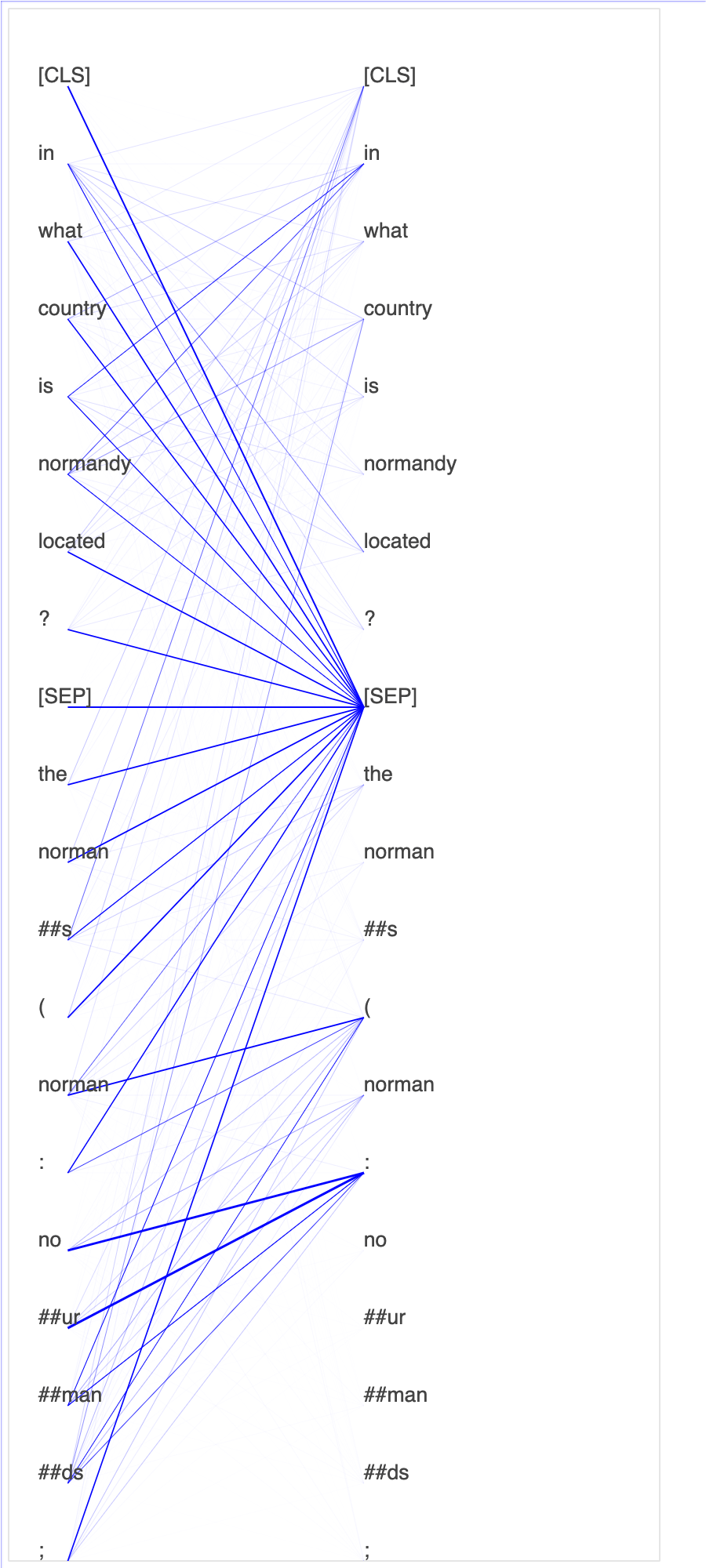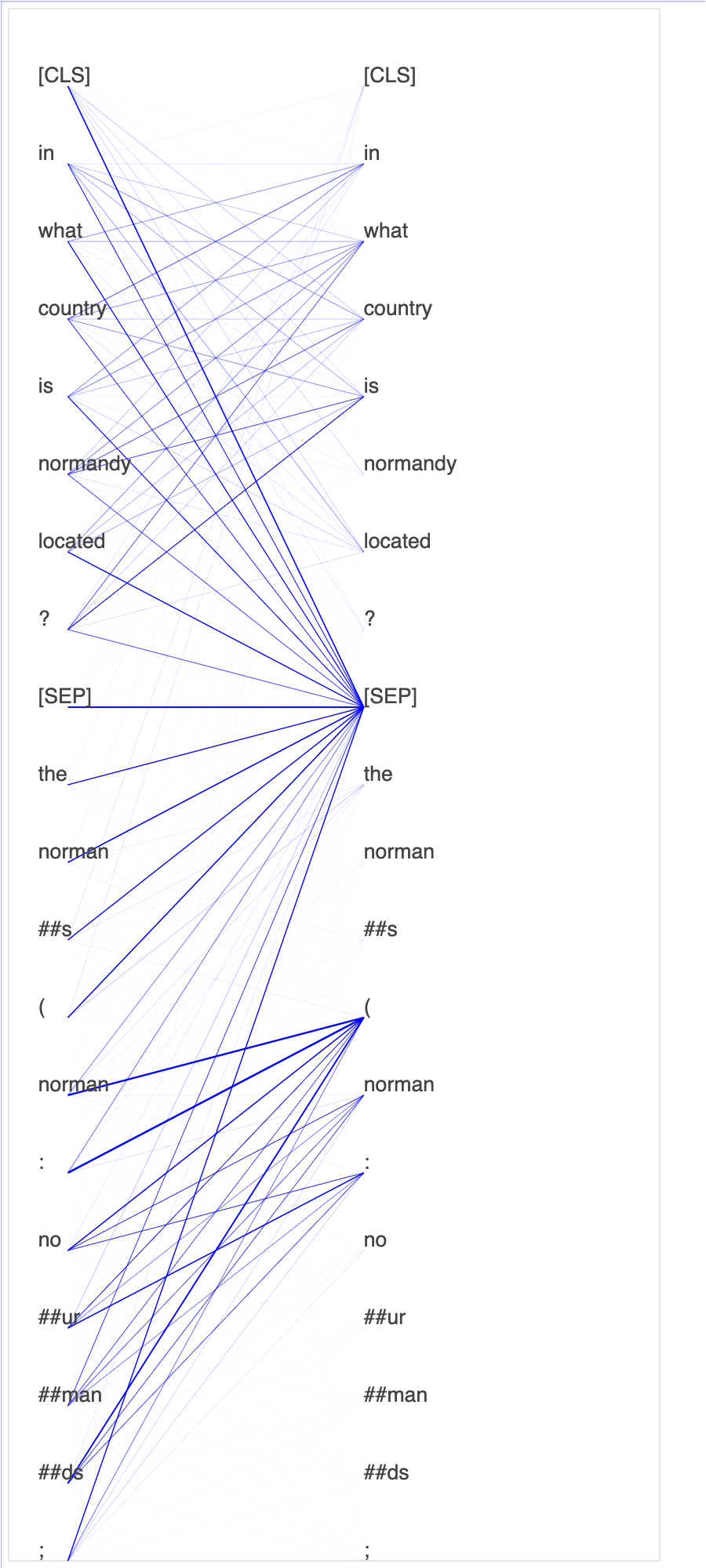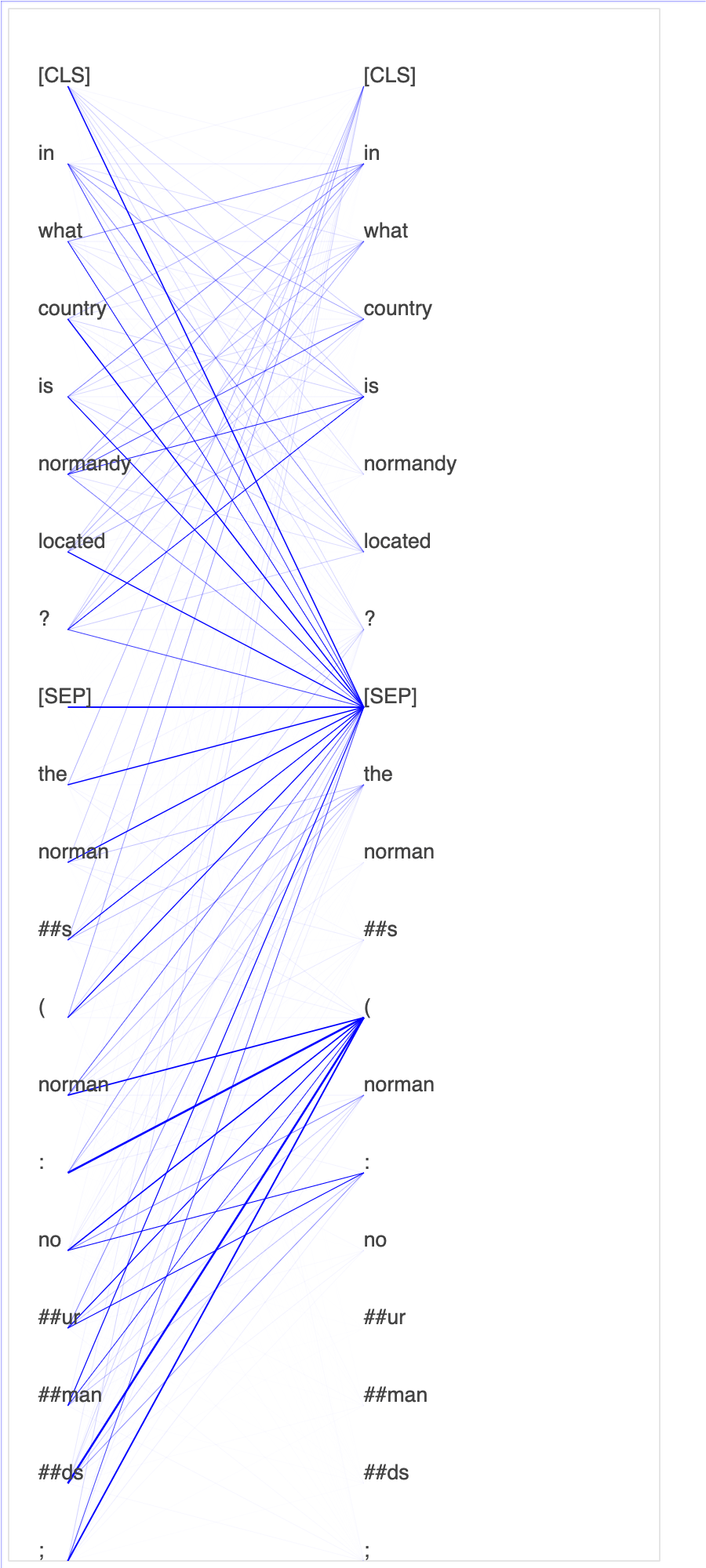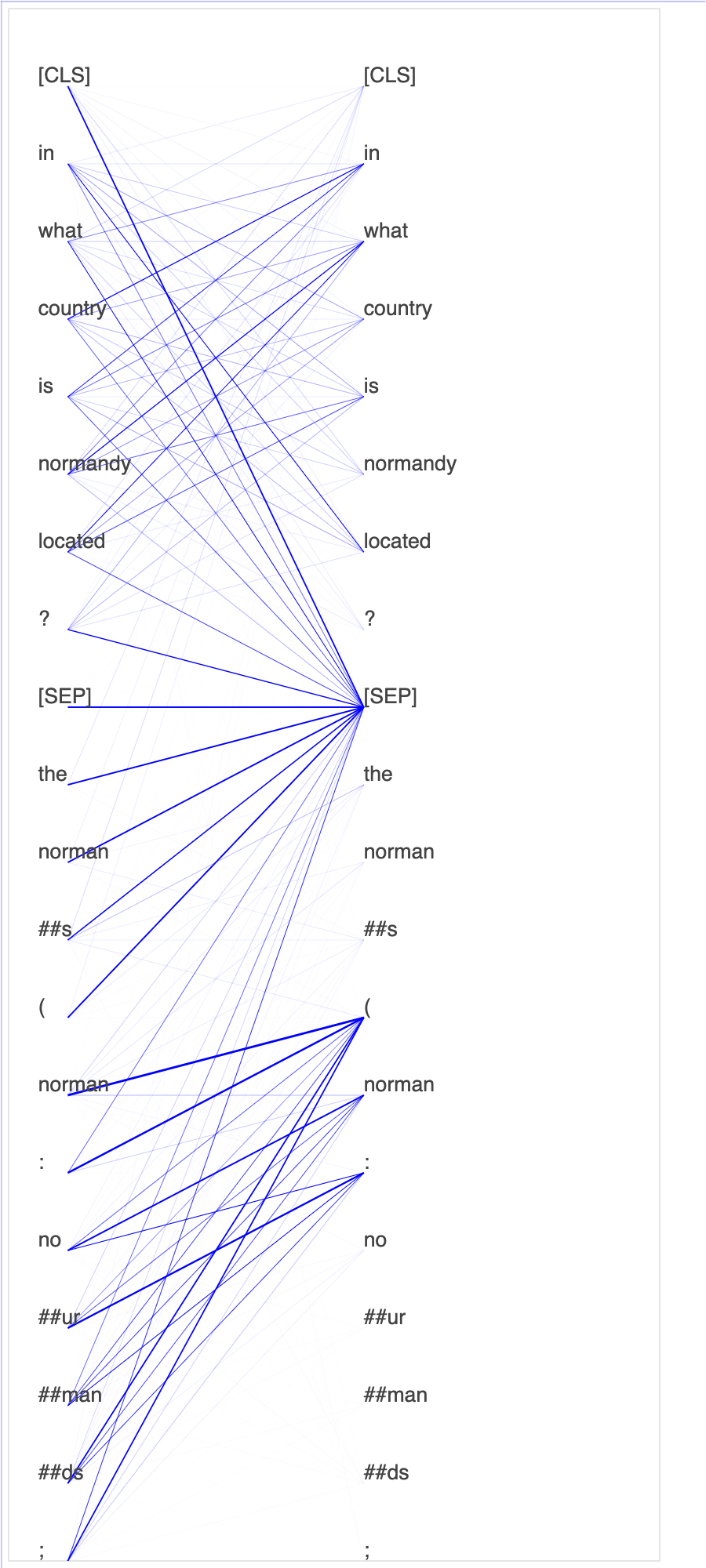
Utiliser SageMaker Debugger pour visualiser des cartes d'activation de classes dans des réseaux neuronaux convolutifs (CNN)
Ce bloc-notes explique comment utiliser SageMaker Debugger pour tracer des cartes d'activation de classes pour la détection et la classification d'images dans les réseaux neuronaux convolutifs (CNN). En apprentissage profond, un réseau neuronal convolutif (CNN ou ConvNet) est une classe de réseaux neuronaux profonds, le plus souvent utilisés pour analyser des images visuelles. Les voitures autonomes illustrent une application qui adopte les cartes d'activation de classes. En effet, elles nécessitent la détection instantanée et la classification des images telles que les panneaux de signalisation, les routes et les obstacles.
Dans ce bloc-notes, le PyTorch ResNet modèle est entraîné sur le jeu de données allemand sur les panneaux de signalisation
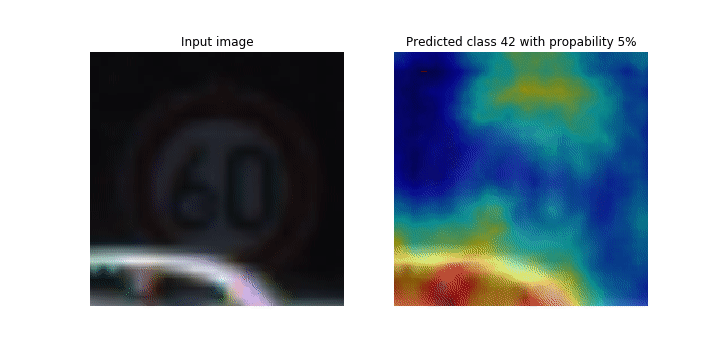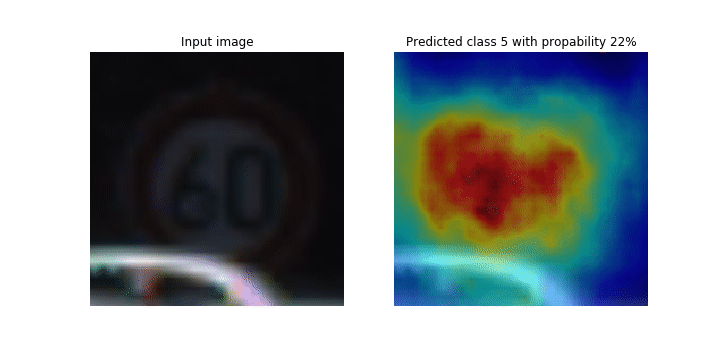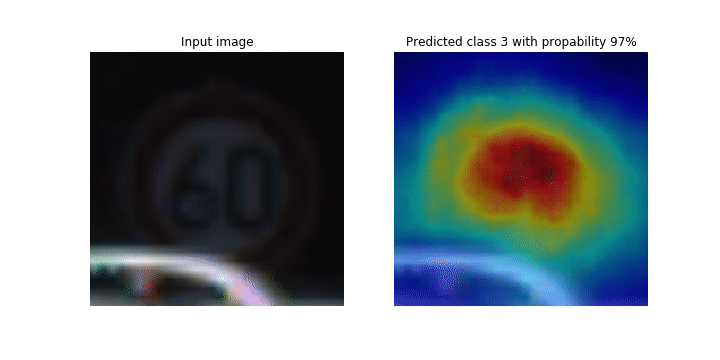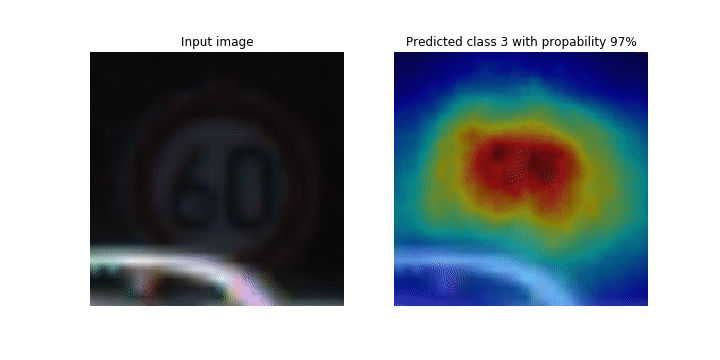
Au cours du processus de formation, SageMaker Debugger collecte des tenseurs pour tracer les cartes d'activation des classes en temps réel. Comme illustré dans l'image animée, la carte d'activation des classes (également appelée carte de saillance) met en évidence les régions à forte activation en rouge.
À l'aide des tenseurs capturés par Debugger, vous pouvez visualiser l'évolution de la carte d'activation au cours de l'entraînement du modèle. Le modèle commence par détecter le bord dans le coin inférieur gauche au début de la tâche d'entraînement. Au fur et à mesure que l'entraînement progresse, l'accent est mis sur le centre et détecte le panneau de limitation de vitesse, et le modèle prédit avec succès l'image d'entrée comme étant de classe 3, qui est une classe de 60km/h panneaux de limitation de vitesse, avec un niveau de confiance de 97 %.
