Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Découvrez les options de déploiement de modèles et d'obtention d'inférences sur Amazon SageMaker
Pour vous aider à démarrer avec l' SageMaker inférence, consultez les sections suivantes qui expliquent les options qui s'offrent à vous pour déployer votre modèle SageMaker et obtenir des inférences. La Options d'inférence sur Amazon SageMaker section peut vous aider à déterminer quelle fonctionnalité correspond le mieux à votre cas d'utilisation pour l'inférence.
Vous pouvez consulter Ressources cette section pour plus d'informations de dépannage et de référence, des blogs et des exemples pour vous aider à démarrer, ainsi que des informations courantesFAQs.
Rubriques
Avant de commencer
Ces rubriques supposent que vous avez créé et entraîné un modèle de machine learning, et que vous êtes prêt à le déployer. Vous n'avez pas besoin d'entraîner votre modèle pour le déployer SageMaker et obtenir des déductions. SageMaker Si vous ne possédez pas votre propre modèle, vous pouvez également utiliser SageMaker les algorithmes intégrés ou les modèles préentraînés.
Si vous débutez SageMaker et que vous n'avez pas encore choisi de modèle à déployer, suivez les étapes du SageMaker didacticiel Get Started with Amazon. Utilisez le didacticiel pour vous familiariser avec la SageMaker gestion du processus de science des données et la manière dont il gère le déploiement des modèles. Pour plus d'informations sur l'entraînement d'un modèle, consultez Entraîner des modèles.
Pour obtenir des informations, des références et des exemples supplémentaires, consultez Ressources.
Étapes du déploiement d'un modèle
Pour les points de terminaison d'inférence, le flux de travail général se compose des opérations suivantes :
Créez un modèle dans SageMaker Inference en pointant vers des artefacts de modèle stockés dans Amazon S3 et une image de conteneur.
Sélectionnez une option d'inférence. Pour de plus amples informations, veuillez consulter Options d'inférence sur Amazon SageMaker.
Créez une configuration de point de terminaison d' SageMaker inférence en choisissant le type d'instance et le nombre d'instances dont vous avez besoin derrière le point de terminaison. Vous pouvez utiliser Amazon SageMaker Inference Recommender pour obtenir des recommandations pour les types d'instances. Pour l'inférence sans serveur, il vous suffit de fournir la configuration de mémoire dont vous avez besoin en fonction de la taille de votre modèle.
Créez un point de terminaison SageMaker d'inférence.
Invoquez votre point de terminaison pour recevoir une inférence en tant que réponse.
Le schéma suivant illustre le flux de travail précédent.
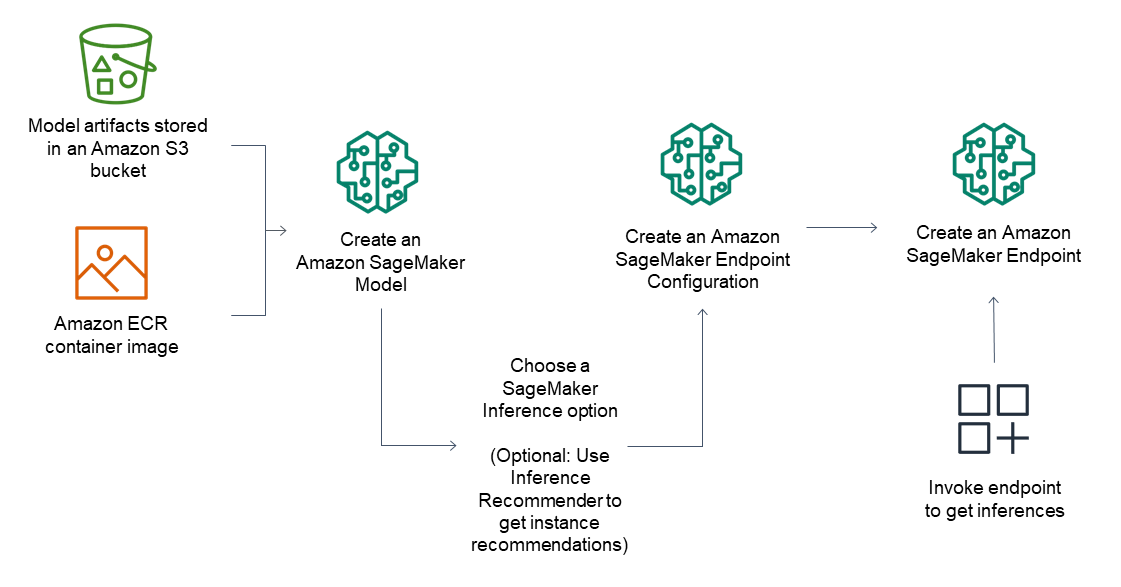
Vous pouvez effectuer ces actions à l'aide de la AWS console AWS SDKs, du SageMaker Python SDK AWS CloudFormation ou du AWS CLI.
Pour l'inférence par lots avec transformation par lots, pointez sur les artefacts de votre modèle et les données d'entrée, puis créez une tâche d'inférence par lots. Au lieu d'héberger un point de terminaison à des fins d'inférence, SageMaker envoie vos inférences à l'emplacement Amazon S3 de votre choix.
