Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Créez un modèle dans Amazon SageMaker AI avec ModelBuilder
La préparation de votre modèle pour le déploiement sur un point de terminaison basé sur l' SageMaker IA nécessite plusieurs étapes, notamment le choix d'une image de modèle, la configuration du point de terminaison, le codage de vos fonctions de sérialisation et de désérialisation pour transférer les données vers et depuis le serveur et le client, l'identification des dépendances du modèle et leur téléchargement sur Amazon S3. ModelBuilderpeut réduire la complexité de la configuration initiale et du déploiement pour vous aider à créer un modèle déployable en une seule étape.
ModelBuilderexécute les tâches suivantes pour vous :
Convertit les modèles d'apprentissage automatique formés à l'aide de divers frameworks tels que XGBoost ou PyTorch en modèles déployables en une seule étape.
Effectue une sélection automatique des conteneurs en fonction de la structure du modèle afin que vous n'ayez pas à spécifier manuellement votre conteneur. Vous pouvez toujours apporter votre propre conteneur en transmettant votre propre URI à
ModelBuilder.Gère la sérialisation des données côté client avant de les envoyer au serveur pour inférence et désérialisation des résultats renvoyés par le serveur. Les données sont correctement formatées sans traitement manuel.
Permet la capture automatique des dépendances et emballe le modèle en fonction des attentes du serveur modèle.
ModelBuilderLa capture automatique des dépendances est une approche optimale pour charger les dépendances de manière dynamique. (Nous vous recommandons de tester la capture automatique localement et de mettre à jour les dépendances en fonction de vos besoins.)Pour les cas d'utilisation d'un modèle de langage étendu (LLM), effectue éventuellement un réglage des paramètres locaux des propriétés de service qui peuvent être déployées pour améliorer les performances lors de l'hébergement sur un point de terminaison SageMaker AI.
Supporte la plupart des modèles de serveurs et de conteneurs populaires tels que TorchServe Triton DJLServing et TGI Container.
Construisez votre modèle avec ModelBuilder
ModelBuilderest une classe Python qui prend un modèle de framework, tel que XGBoost ou PyTorch, ou une spécification d'inférence spécifiée par l'utilisateur, et le convertit en un modèle déployable. ModelBuilderfournit une fonction de génération qui génère les artefacts pour le déploiement. L'artefact de modèle généré est spécifique au serveur de modèles, que vous pouvez également spécifier comme l'une des entrées. Pour plus de détails sur le ModelBuilder cours, voir ModelBuilder
Le schéma suivant illustre le flux de travail global de création de modèles lorsque vous utilisezModelBuilder. ModelBuilderaccepte un modèle ou une spécification d'inférence avec votre schéma pour créer un modèle déployable que vous pouvez tester localement avant le déploiement.
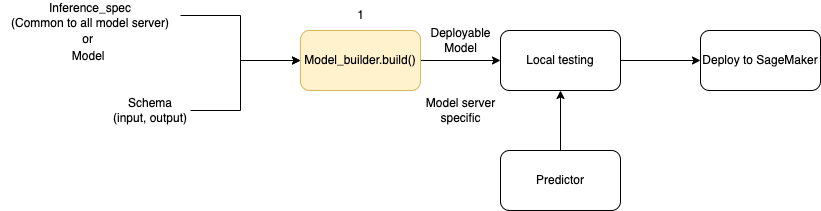
ModelBuilderpeut gérer toute personnalisation que vous souhaitez appliquer. Toutefois, pour déployer un modèle de structure, le constructeur du modèle attend au minimum un modèle, des échantillons d'entrée et de sortie, ainsi que le rôle. Dans l'exemple de code suivant, ModelBuilder il est appelé avec un modèle de framework et une instance de SchemaBuilder avec un minimum d'arguments (pour déduire les fonctions correspondantes pour la sérialisation et la désérialisation de l'entrée et de la sortie du point de terminaison). Aucun conteneur n'est spécifié et aucune dépendance empaquetée n'est transmise. SageMaker L'IA déduit automatiquement ces ressources lorsque vous créez votre modèle.
from sagemaker.serve.builder.model_builder import ModelBuilder from sagemaker.serve.builder.schema_builder import SchemaBuilder model_builder = ModelBuilder( model=model, schema_builder=SchemaBuilder(input, output), role_arn="execution-role", )
L'exemple de code suivant invoque ModelBuilder avec une spécification d'inférence (sous forme d'InferenceSpecinstance) au lieu d'un modèle, avec une personnalisation supplémentaire. Dans ce cas, l'appel au générateur de modèles inclut un chemin pour stocker les artefacts du modèle et active également la capture automatique de toutes les dépendances disponibles. Pour plus de détails surInferenceSpec, voirPersonnaliser le chargement des modèles et le traitement des demandes.
model_builder = ModelBuilder( mode=Mode.LOCAL_CONTAINER, model_path=model-artifact-directory, inference_spec=your-inference-spec, schema_builder=SchemaBuilder(input, output), role_arn=execution-role, dependencies={"auto": True} )
Définition des méthodes de sérialisation et de désérialisation
Lors de l'appel d'un point de terminaison SageMaker AI, les données sont envoyées via des charges utiles HTTP avec différents types MIME. Par exemple, une image envoyée au point de terminaison pour inférence doit être convertie en octets côté client et envoyée via une charge utile HTTP au point de terminaison. Lorsque le point de terminaison reçoit la charge utile, il doit désérialiser la chaîne d'octets pour revenir au type de données attendu par le modèle (également connu sous le nom de désérialisation côté serveur). Une fois que le modèle a terminé la prédiction, les résultats doivent également être sérialisés en octets qui peuvent être renvoyés par le biais de la charge utile HTTP à l'utilisateur ou au client. Une fois que le client reçoit les données d'octets de réponse, il doit effectuer une désérialisation côté client pour reconvertir les données d'octets au format de données attendu, tel que JSON. Vous devez au minimum convertir les données pour les tâches suivantes :
Sérialisation des demandes d'inférence (gérée par le client)
Désérialisation des demandes d'inférence (gérée par le serveur ou l'algorithme)
Invoquer le modèle par rapport à la charge utile et renvoyer la charge utile de réponse
Sérialisation des réponses d'inférence (gérée par le serveur ou l'algorithme)
Désérialisation des réponses d'inférence (gérée par le client)
Le schéma suivant montre les processus de sérialisation et de désérialisation qui se produisent lorsque vous appelez le point de terminaison.
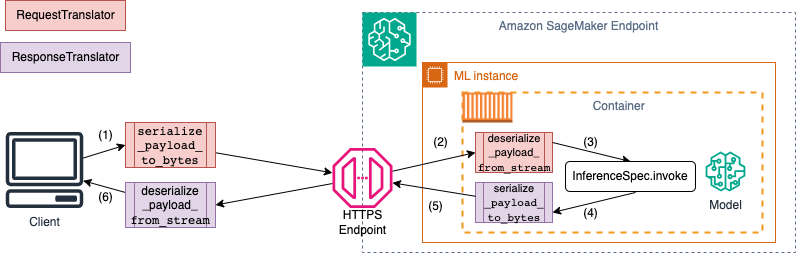
Lorsque vous fournissez des échantillons d'entrée et de sortie àSchemaBuilder, le générateur de schéma génère les fonctions de regroupement correspondantes pour sérialiser et désérialiser l'entrée et la sortie. Vous pouvez personnaliser davantage vos fonctions de sérialisation avecCustomPayloadTranslator. Mais dans la plupart des cas, un simple sérialiseur tel que le suivant fonctionnerait :
input = "How is the demo going?" output = "Comment la démo va-t-elle?" schema = SchemaBuilder(input, output)
Pour plus de détails surSchemaBuilder, voir SchemaBuilder
L'extrait de code suivant décrit un exemple dans lequel vous souhaitez personnaliser les fonctions de sérialisation et de désérialisation côté client et côté serveur. Vous pouvez définir vos propres traducteurs de demandes et de réponses CustomPayloadTranslator et les transmettre à ces traducteursSchemaBuilder.
En incluant les entrées et les sorties dans les traducteurs, le constructeur du modèle peut extraire le format de données attendu par le modèle. Supposons, par exemple, que l'exemple d'entrée soit une image brute et que vos traducteurs personnalisés recadrent l'image et envoient l'image recadrée au serveur sous forme de tenseur. ModelBuildera besoin à la fois de l'entrée brute et de tout code de prétraitement ou de post-traitement personnalisé pour obtenir une méthode permettant de convertir les données à la fois du côté client et du côté serveur.
from sagemaker.serve import CustomPayloadTranslator # request translator class MyRequestTranslator(CustomPayloadTranslator): # This function converts the payload to bytes - happens on client side def serialize_payload_to_bytes(self, payload: object) -> bytes: # converts the input payload to bytes ... ... return //return object as bytes # This function converts the bytes to payload - happens on server side def deserialize_payload_from_stream(self, stream) -> object: # convert bytes to in-memory object ... ... return //return in-memory object # response translator class MyResponseTranslator(CustomPayloadTranslator): # This function converts the payload to bytes - happens on server side def serialize_payload_to_bytes(self, payload: object) -> bytes: # converts the response payload to bytes ... ... return //return object as bytes # This function converts the bytes to payload - happens on client side def deserialize_payload_from_stream(self, stream) -> object: # convert bytes to in-memory object ... ... return //return in-memory object
Vous transmettez les exemples d'entrée et de sortie ainsi que les traducteurs personnalisés définis précédemment lorsque vous créez l'SchemaBuilderobjet, comme indiqué dans l'exemple suivant :
my_schema = SchemaBuilder( sample_input=image, sample_output=output, input_translator=MyRequestTranslator(), output_translator=MyResponseTranslator() )
Vous transmettez ensuite les exemples d'entrée et de sortie, ainsi que les traducteurs personnalisés définis précédemment, à l'SchemaBuilderobjet.
my_schema = SchemaBuilder( sample_input=image, sample_output=output, input_translator=MyRequestTranslator(), output_translator=MyResponseTranslator() )
Les sections suivantes expliquent en détail comment créer votre modèle avec ModelBuilder et utiliser ses classes de support pour personnaliser l'expérience en fonction de votre cas d'utilisation.
Rubriques
Personnaliser le chargement des modèles et le traitement des demandes
Le fait de fournir votre propre code d'inférence InferenceSpec offre une couche supplémentaire de personnalisation. Vous pouvez ainsi personnaliser le mode de chargement du modèle et la manière dont il gère les demandes d'inférence entrantes, en contournant ses mécanismes de chargement et de gestion des inférences par défaut. InferenceSpec Cette flexibilité est particulièrement utile lorsque vous travaillez avec des modèles non standard ou des pipelines d'inférence personnalisés. Vous pouvez personnaliser la invoke méthode pour contrôler la manière dont le modèle prétraite et post-traite les demandes entrantes. La invoke méthode garantit que le modèle gère correctement les demandes d'inférence. L'exemple suivant permet InferenceSpec de générer un modèle avec le HuggingFace pipeline. Pour plus de détails surInferenceSpec, reportez-vous au InferenceSpec
from sagemaker.serve.spec.inference_spec import InferenceSpec from transformers import pipeline class MyInferenceSpec(InferenceSpec): def load(self, model_dir: str): return pipeline("translation_en_to_fr", model="t5-small") def invoke(self, input, model): return model(input) inf_spec = MyInferenceSpec() model_builder = ModelBuilder( inference_spec=your-inference-spec, schema_builder=SchemaBuilder(X_test, y_pred) )
L'exemple suivant illustre une variante plus personnalisée d'un exemple précédent. Un modèle est défini avec une spécification d'inférence comportant des dépendances. Dans ce cas, le code de la spécification d'inférence dépend du package lang-segment. L'argument for dependencies contient une instruction qui demande au générateur d'installer lang-segment à l'aide de Git. Étant donné que l'utilisateur demande au générateur de modèles d'installer une dépendance de manière personnalisée, l'autoessentiel est False de désactiver la capture automatique des dépendances.
model_builder = ModelBuilder( mode=Mode.LOCAL_CONTAINER, model_path=model-artifact-directory, inference_spec=your-inference-spec, schema_builder=SchemaBuilder(input, output), role_arn=execution-role, dependencies={"auto": False, "custom": ["-e git+https://github.com/luca-medeiros/lang-segment-anything.git#egg=lang-sam"],} )
Créez votre modèle et déployez-le
Appelez la build fonction pour créer votre modèle déployable. Cette étape crée un ou plusieurs codes d'inférence dans votre répertoire de travail avec le code nécessaire pour créer votre schéma, exécuter la sérialisation et la désérialisation des entrées et des sorties, et exécuter d'autres logiques personnalisées spécifiées par l'utilisateur. inference.py
À des fins de contrôle d'intégrité, l' SageMaker IA empaquète et sélectionne les fichiers nécessaires au déploiement dans le cadre de la fonction de ModelBuilder génération. Au cours de ce processus, SageMaker AI crée également une signature HMAC pour le fichier pickle et ajoute la clé secrète dans l'CreateModelAPI en tant que variable d'environnement pendant deploy (oucreate). Le lancement du point de terminaison utilise la variable d'environnement pour valider l'intégrité du fichier pickle.
# Build the model according to the model server specification and save it as files in the working directory model = model_builder.build()
Déployez votre modèle avec la deploy méthode existante du modèle. Au cours de cette étape, l' SageMaker IA configure un point de terminaison pour héberger votre modèle lorsqu'il commence à faire des prédictions sur les demandes entrantes. Bien que cela ModelBuilder déduit les ressources du point de terminaison nécessaires au déploiement de votre modèle, vous pouvez remplacer ces estimations par vos propres valeurs de paramètres. L'exemple suivant indique à SageMaker AI de déployer le modèle sur une seule ml.c6i.xlarge instance. Un modèle construit à partir de ModelBuilder permet la journalisation en direct pendant le déploiement en tant que fonctionnalité supplémentaire.
predictor = model.deploy( initial_instance_count=1, instance_type="ml.c6i.xlarge" )
Si vous souhaitez contrôler de manière plus précise les ressources de point de terminaison attribuées à votre modèle, vous pouvez utiliser un ResourceRequirements objet. Avec l'ResourceRequirementsobjet, vous pouvez demander un nombre minimum de modèles CPUs, d'accélérateurs et de copies des modèles que vous souhaitez déployer. Vous pouvez également demander une limite de mémoire minimale et maximale (en Mo). Pour utiliser cette fonctionnalité, vous devez spécifier le type de point de terminaison commeEndpointType.INFERENCE_COMPONENT_BASED. L'exemple suivant demande le déploiement de quatre accélérateurs, d'une taille de mémoire minimale de 1024 Mo et d'une copie de votre modèle sur un point de terminaison de ce typeEndpointType.INFERENCE_COMPONENT_BASED.
resource_requirements = ResourceRequirements( requests={ "num_accelerators": 4, "memory": 1024, "copies": 1, }, limits={}, ) predictor = model.deploy( mode=Mode.SAGEMAKER_ENDPOINT, endpoint_type=EndpointType.INFERENCE_COMPONENT_BASED, resources=resource_requirements, role="role" )
Apportez votre propre conteneur (BYOC)
Si vous souhaitez apporter votre propre conteneur (étendu à partir d'un conteneur SageMaker AI), vous pouvez également spécifier l'URI de l'image comme indiqué dans l'exemple suivant. Vous devez également identifier le serveur de modèles correspondant à l'image ModelBuilder afin de générer des artefacts spécifiques au serveur de modèles.
model_builder = ModelBuilder( model=model, model_server=ModelServer.TORCHSERVE, schema_builder=SchemaBuilder(X_test, y_pred), image_uri="123123123123.dkr.ecr.ap-southeast-2.amazonaws.com/byoc-image:xgb-1.7-1") )
Utilisation ModelBuilder en mode local
Vous pouvez déployer votre modèle localement en utilisant l'modeargument pour passer du test local au déploiement vers un point de terminaison. Vous devez stocker les artefacts du modèle dans le répertoire de travail, comme indiqué dans l'extrait suivant :
model = XGBClassifier() model.fit(X_train, y_train) model.save_model(model_dir + "/my_model.xgb")
Passez l'objet du modèle, une SchemaBuilder instance et le mode set àMode.LOCAL_CONTAINER. Lorsque vous appelez la build fonction, elle identifie ModelBuilder automatiquement le conteneur du framework pris en charge et analyse les dépendances. L'exemple suivant illustre la création d'un modèle avec un XGBoost modèle en mode local.
model_builder_local = ModelBuilder( model=model, schema_builder=SchemaBuilder(X_test, y_pred), role_arn=execution-role, mode=Mode.LOCAL_CONTAINER ) xgb_local_builder = model_builder_local.build()
Appelez la deploy fonction pour effectuer un déploiement local, comme indiqué dans l'extrait suivant. Si vous spécifiez des paramètres pour le type ou le nombre d'instances, ces arguments sont ignorés.
predictor_local = xgb_local_builder.deploy()
Résolution des problèmes en mode local
En fonction de votre configuration locale individuelle, vous pouvez rencontrer des difficultés pour ModelBuilder fonctionner correctement dans votre environnement. Consultez la liste suivante pour connaître certains problèmes que vous pourriez rencontrer et savoir comment les résoudre.
Déjà utilisé : il se peut que vous rencontriez une
Address already in useerreur. Dans ce cas, il est possible qu'un conteneur Docker soit en cours d'exécution sur ce port ou qu'un autre processus l'utilise. Vous pouvez suivre l'approche décrite dans la documentation Linuxpour identifier le processus et rediriger gracieusement votre processus local du port 8080 vers un autre port ou nettoyer l'instance Docker. Problème d'autorisation IAM : vous pouvez rencontrer un problème d'autorisation lorsque vous essayez d'extraire une image Amazon ECR ou d'accéder à Amazon S3. Dans ce cas, accédez au rôle d'exécution du bloc-notes ou de l'instance Studio Classic pour vérifier la politique
SageMakerFullAccessou les autorisations d'API respectives.Problème de capacité du volume EBS : si vous déployez un modèle de langage étendu (LLM), vous risquez de manquer d'espace lors de l'exécution de Docker en mode local ou de rencontrer des limites d'espace pour le cache Docker. Dans ce cas, vous pouvez essayer de déplacer votre volume Docker vers un système de fichiers disposant de suffisamment d'espace. Pour déplacer votre volume Docker, procédez comme suit :
Ouvrez un terminal et exécutez-le
dfpour afficher l'utilisation du disque, comme indiqué dans le résultat suivant :(python3) sh-4.2$ df Filesystem 1K-blocks Used Available Use% Mounted on devtmpfs 195928700 0 195928700 0% /dev tmpfs 195939296 0 195939296 0% /dev/shm tmpfs 195939296 1048 195938248 1% /run tmpfs 195939296 0 195939296 0% /sys/fs/cgroup /dev/nvme0n1p1 141545452 135242112 6303340 96% / tmpfs 39187860 0 39187860 0% /run/user/0 /dev/nvme2n1 264055236 76594068 176644712 31% /home/ec2-user/SageMaker tmpfs 39187860 0 39187860 0% /run/user/1002 tmpfs 39187860 0 39187860 0% /run/user/1001 tmpfs 39187860 0 39187860 0% /run/user/1000Déplacez le répertoire Docker par défaut de
/dev/nvme0n1p1vers/dev/nvme2n1afin de pouvoir utiliser pleinement le volume SageMaker AI de 256 Go. Pour plus de détails, consultez la documentation sur la façon de déplacer votre répertoire Docker. Arrêtez Docker avec la commande suivante :
sudo service docker stopAjoutez un
daemon.jsonblob JSON/etc/dockerou ajoutez le blob JSON suivant au blob existant.{ "data-root": "/home/ec2-user/SageMaker/{created_docker_folder}" }Déplacez le répertoire Docker
/var/lib/dockervers à l'/home/ec2-user/SageMaker AIaide de la commande suivante :sudo rsync -aP /var/lib/docker/ /home/ec2-user/SageMaker/{created_docker_folder}Démarrez Docker avec la commande suivante :
sudo service docker startNettoyez la corbeille à l'aide de la commande suivante :
cd /home/ec2-user/SageMaker/.Trash-1000/files/* sudo rm -r *Si vous utilisez une instance de SageMaker bloc-notes, vous pouvez suivre les étapes du fichier de préparation Docker
pour préparer Docker au mode local.
ModelBuilder exemples
Pour d'autres exemples d'utilisation ModelBuilder pour créer vos modèles, consultez les ModelBuilderexemples de blocs-notes
