Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Génération augmentée de récupération
Les modèles de fondation sont généralement entraînés hors connexion, ce qui les rend indépendants des données créées après l'entraînement du modèle. De plus, les modèles de fondation sont entraînés sur des corps de domaines très généraux, ce qui les rend moins efficaces pour les tâches spécifiques à un domaine. Vous pouvez utiliser Retrieval Augmented Generation (RAG) pour récupérer des données en dehors d'un modèle de base et augmenter vos instructions en ajoutant les données extraites pertinentes dans leur contexte. Pour plus d'informations sur les architectures de RAG modèles, voir Génération augmentée par extraction pour les tâches
AvecRAG, les données externes utilisées pour augmenter vos demandes peuvent provenir de plusieurs sources de données, telles que des référentiels de documents, des bases de données ou. APIs La première étape consiste à convertir vos documents et toutes les requêtes utilisateurs dans un format compatible pour effectuer une recherche pertinente. Pour rendre les formats compatibles, une collection de documents, ou bibliothèque de connaissances, et les requêtes soumises par les utilisateurs sont converties en représentations numériques à l'aide de modèles de langue d'incorporation. L'incorporation est le processus par lequel le texte est représenté numériquement dans un espace vectoriel. RAGles architectures de modèles comparent les incorporations des requêtes des utilisateurs dans le vecteur de la bibliothèque de connaissances. L'invite utilisateur d'origine est ensuite ajoutée avec le contexte pertinent provenant de documents similaires de la bibliothèque de connaissances. Cette invite augmentée est ensuite envoyée au modèle de fondation. Vous pouvez mettre à jour les bibliothèques de connaissances et leurs incorporations pertinentes de manière asynchrone.
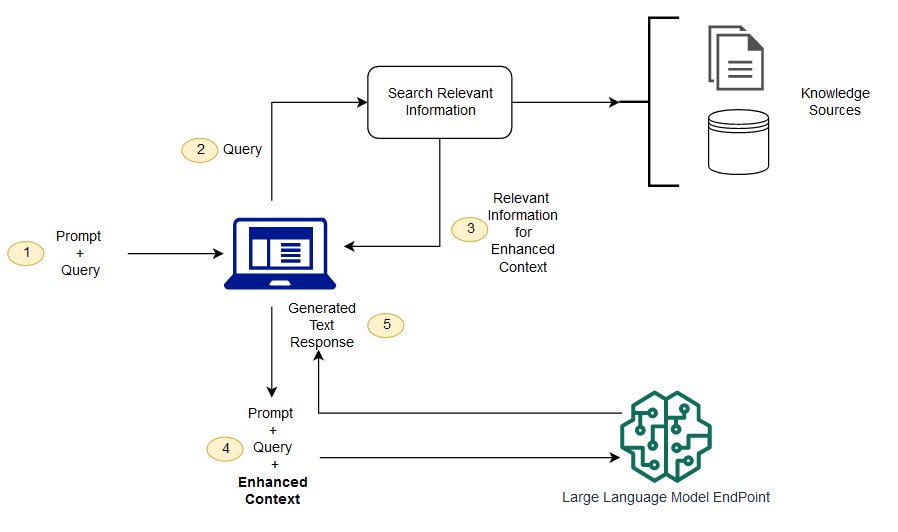
Le document extrait doit être suffisamment grand pour contenir un contexte utile permettant d'augmenter l'invite, mais suffisamment petit pour correspondre à la longueur de séquence maximale de l'invite. Vous pouvez utiliser des JumpStart modèles spécifiques à une tâche, tels que le modèle General Text Embeddings (GTE) deHugging Face, pour fournir les intégrations de vos invites et des documents de la bibliothèque de connaissances. Après avoir comparé l'invite et l'intégration du document pour trouver les documents les plus pertinents, créez une nouvelle invite avec le contexte supplémentaire. Transmettez ensuite l'invite augmentée à un modèle de génération de texte de votre choix.
Exemples de blocs-notes
Pour plus d'informations sur les solutions du modèle de RAG base, consultez les exemples de blocs-notes suivants :
Vous pouvez cloner le référentiel d' SageMaker exemples Amazon
