Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Réparations de clusters en cas d'GPUerreurs
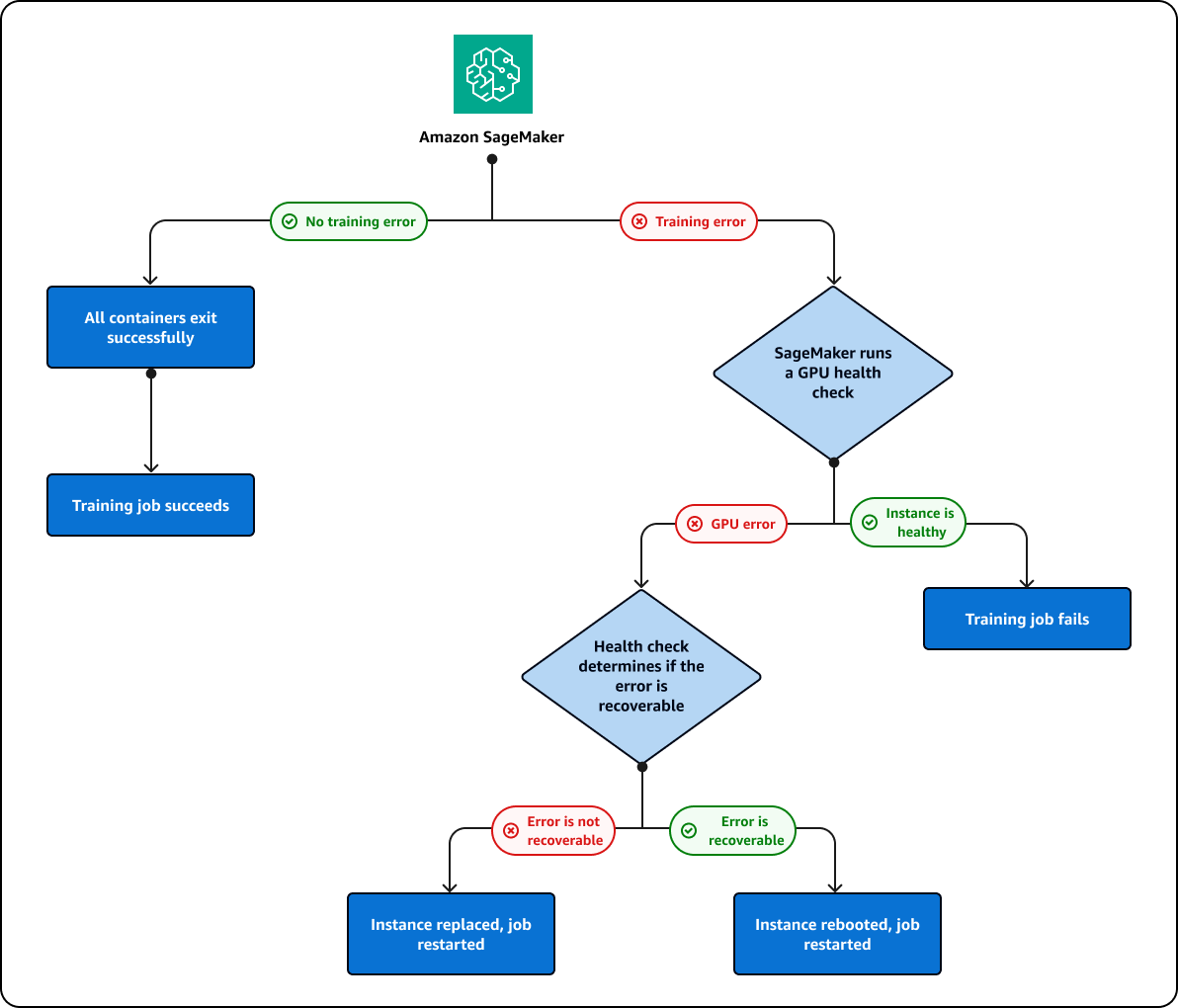
Si vous exécutez une tâche de formation qui échoue sur unGPU, vous SageMaker effectuerez un GPU bilan de santé pour déterminer si l'échec est lié à un GPU problème. SageMaker prend les mesures suivantes en fonction des résultats du bilan de santé :
Si l'erreur est récupérable et peut être corrigée en redémarrant l'instance ou en la réinitialisantGPU, SageMaker elle redémarrera l'instance.
Si l'erreur n'est pas récupérable et qu'elle est causée par une GPU instance qui doit être remplacée, l'instance SageMaker sera remplacée.
L'instance est remplacée ou redémarrée dans le cadre d'un processus de réparation du SageMaker cluster. Au cours de ce processus, le message suivant s'affichera dans le statut de votre poste de formation :
Repairing training cluster due to hardware failure
SageMaker tentera de réparer le cluster 10 plusieurs fois. Si la réparation du cluster est réussie, la tâche de formation SageMaker redémarrera automatiquement à partir du point de contrôle précédent. Si la réparation du cluster échoue, la tâche de formation échouera également. Le processus de réparation du cluster ne vous est pas facturé. Les réparations de clusters ne débuteront que si votre formation échoue. Si un GPU problème est détecté pour un cluster Warmpool, celui-ci passe en mode réparation pour redémarrer ou remplacer l'instance défectueuse. Après réparation, le cluster peut toujours être utilisé comme cluster Warmpool.
Le processus de réparation des clusters et des instances décrit précédemment est illustré dans le schéma suivant :