Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Vous devez satisfaire à la section des prérequis si le modèle a été compilé à l'aide AWS SDK for Python (Boto3) de la AWS CLI console Amazon AI ou de la console Amazon SageMaker AI. Suivez les étapes ci-dessous pour créer et déployer un modèle compilé SageMaker AI Neo à l'aide de la console SageMaker AI https://console.aws.amazon.com SageMaker /AI
Rubriques
Déploiement du modèle
Une fois les prérequis satisfaits, procédez comme suit pour déployer un modèle compilé avec Neo :
-
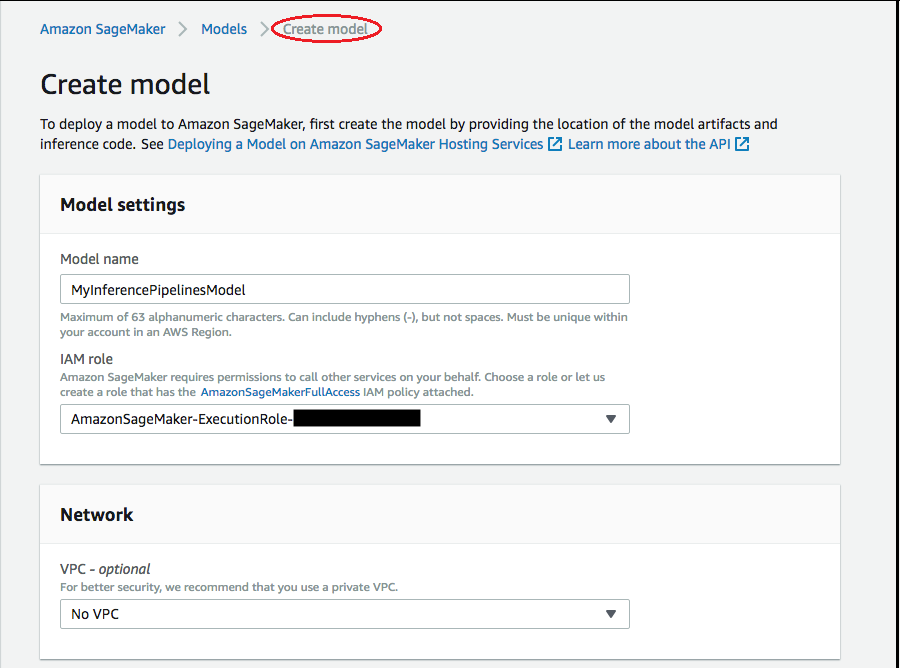
Choisissez Modèles, puis Créer des modèles depuis le groupe Déduction. Sur la page Create model (Créer un modèle), renseignez les champs Model name (Nom du modèle), IAM role (Rôle IAM) et VPC, si nécessaire.
-
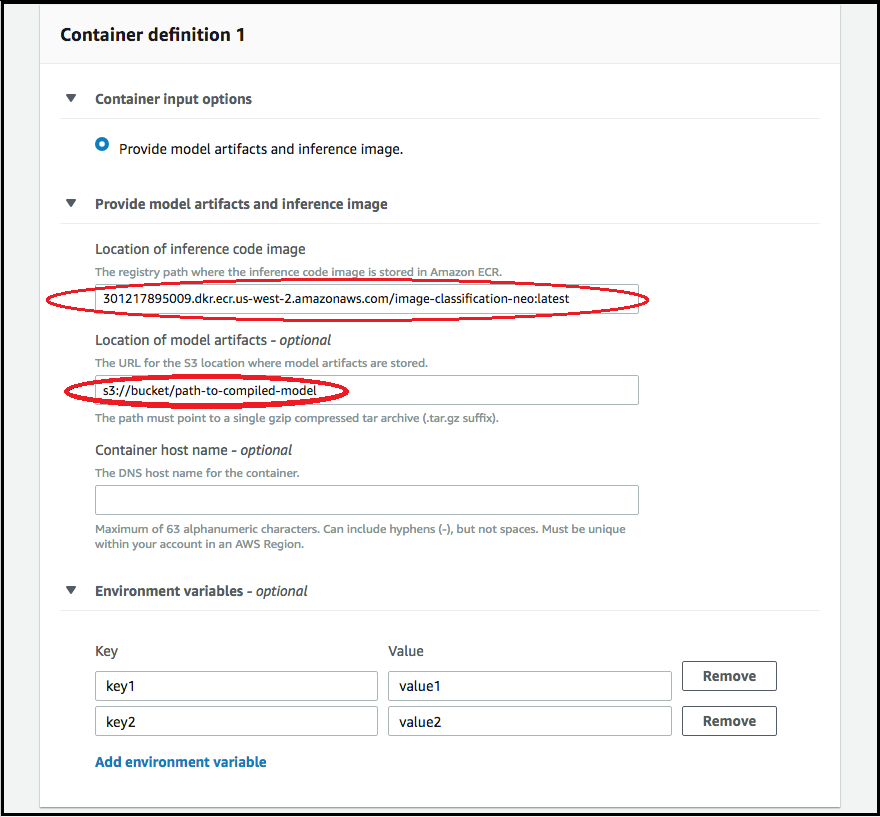
Pour ajouter des informations sur le conteneur utilisé pour déployer votre modèle, choisissez Add container (Ajouter un conteneur), puis Next (Suivant). Renseignez les champs Container input options (Options d'entrée du conteneur), Location of inference code image (Emplacement de l'image du code d'inférence), Location of model artifacts (Emplacement des artefacts du modèle), ainsi que Container host name (Nom d'hôte du conteneur) et Environmental variables (Variables d'environnement) éventuellement.
-
Pour déployer des modèles compilés par Neo, choisissez l'une des options suivantes :
-
Container input options (Options d'entrée du conteneur) : fournissez des artefacts du modèle et une image d'inférence.
-
Location of inference code image (Emplacement de l'image du code d'inférence) : choisissez l'URI de l'image d'inférence dans Neo Inference Container Images (Images du conteneur d'inférence Neo) en fonction de la région AWS et du type d'application.
-
Location of model artifacts (Emplacement des artefacts du modèle) : saisissez l'URI du compartiment Amazon S3 de l'artefact du modèle compilé généré par l'API de compilation Neo.
-
Variables d'environnement :
-
Laissez ce champ vide pour SageMaker XGBoost.
-
Si vous avez entraîné votre modèle à l'aide de l' SageMaker IA, spécifiez la variable d'environnement
SAGEMAKER_SUBMIT_DIRECTORYsous la forme de l'URI du compartiment Amazon S3 qui contient le script d'entraînement. -
Si vous n'avez pas entraîné votre modèle à l'aide de l' SageMaker IA, spécifiez les variables d'environnement suivantes :
Clé Valeurs pour MXNet et PyTorch Valeurs TensorFlow SAGEMAKER_PROGRAM inference.py inference.py SAGEMAKER_SUBMIT_DIRECTORY /opt/ml/model/code /opt/ml/model/code SAGEMAKER_CONTAINER_LOG_LEVEL 20 20 SAGEMAKER_REGION <your region> <your region> MMS_DEFAULT_RESPONSE_TIMEOUT 500 Laissez ce champ vide pour TF
-
-
-
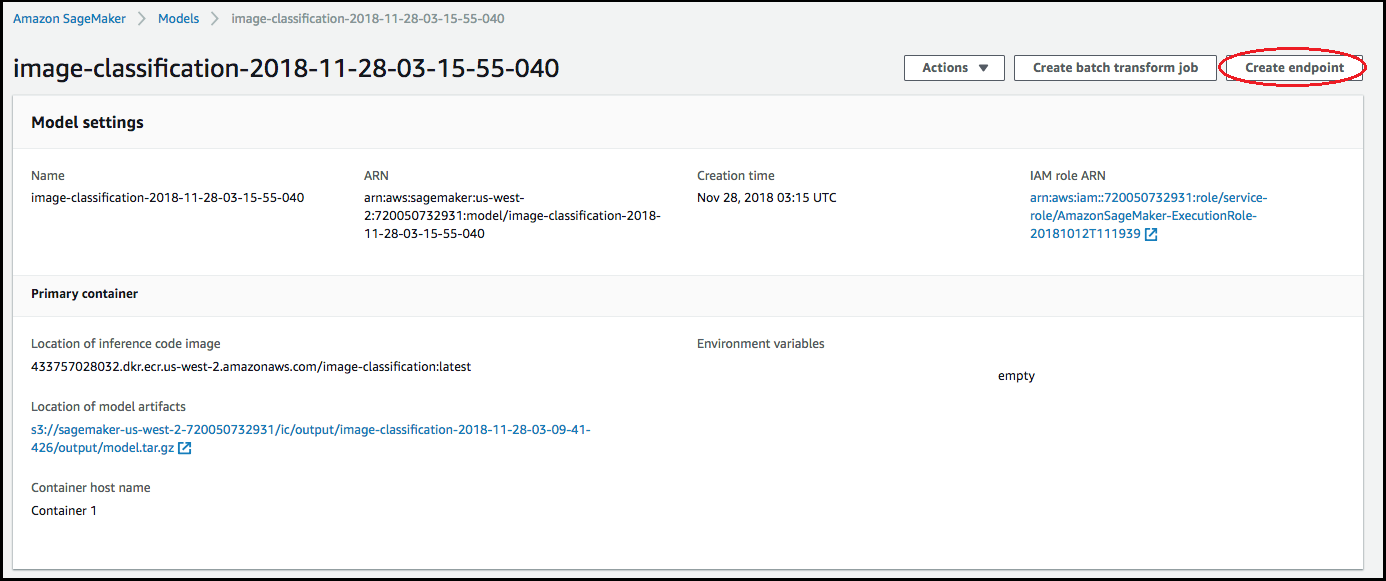
Confirmez l'exactitude des informations des conteneurs, puis choisissez Create model (Créer un modèle). Sur la Create model landing page (page d'accueil Créer un modèle), choisissez Create endpoint (Créer un point de terminaison).
-
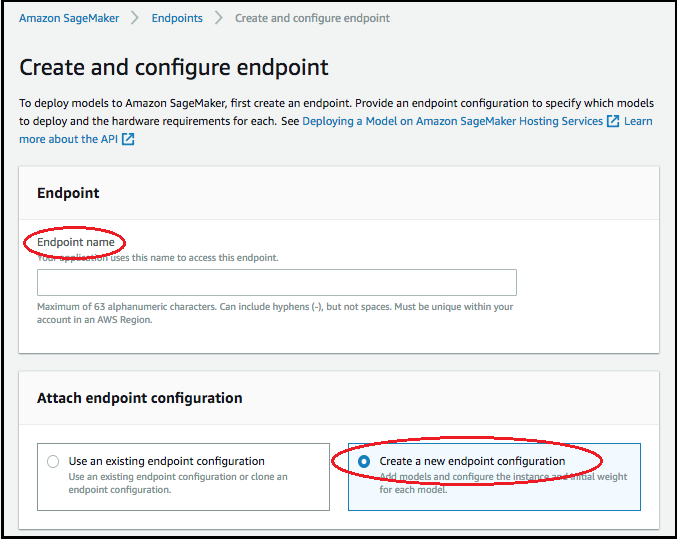
Sur le schéma, Créer et configurer un point de terminaison, spécifiez le Nom du point de terminaison. Pour Attach endpoint configuration (Attacher une configuration de point de terminaison) choisissez Create a new endpoint configuration (Créer une nouvelle configuration de point de terminaison).
-
Sur la page Nouvelle configuration du point de terminaison, spécifiez le Nom de configuration du point de terminaison.
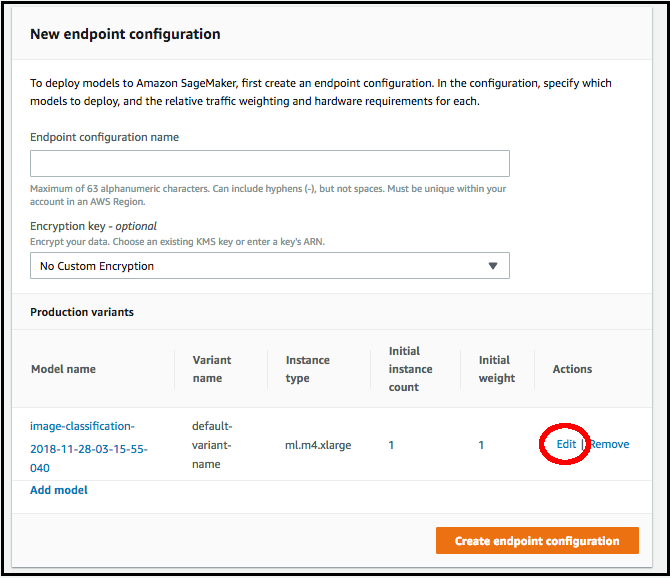
-
Choisissez Edit (Modifier) en regard du nom du modèle et spécifiez le Type d'instance correct sur la page Edit Production Variant (Modifier la variante de production). Il est impératif que la valeur Type d'instance corresponde à celle spécifiée dans votre tâche de compilation.
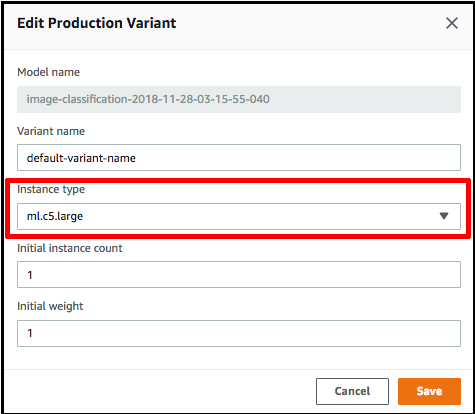
-
Choisissez Save (Enregistrer).
-
Sur la page New endpoint configuration (Nouvelle configuration de point de terminaison), choisissez Create endpoint configuration (Créer une configuration de point de terminaison), puis choisissez Create endpoint (Créer un point de terminaison).
