Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Commencez par les scripts de cycle de vie de base fournis par HyperPod
Cette section vous présente tous les composants du processus de base de configuration de Slurm selon HyperPod une approche descendante. Il commence par la préparation d'une demande de création de HyperPod cluster pour exécuter l'CreateClusterAPI, puis explore en profondeur la structure hiérarchique jusqu'aux scripts de cycle de vie. Utilisez les exemples de scripts de cycle de vie fournis dans le GitHub référentiel Awsome Distributed Training
git clone https://github.com/aws-samples/awsome-distributed-training/
Les scripts de cycle de vie de base pour configurer un cluster Slurm SageMaker HyperPod sont disponibles sur. 1.architectures/5.sagemaker_hyperpods/LifecycleScripts/base-config
cd awsome-distributed-training/1.architectures/5.sagemaker_hyperpods/LifecycleScripts/base-config
L'organigramme suivant présente un aperçu détaillé de la manière dont vous devez concevoir les scripts de cycle de vie de base. Les descriptions situées sous le schéma et le guide de procédure expliquent leur fonctionnement lors de l'appel HyperPod CreateCluster d'API.
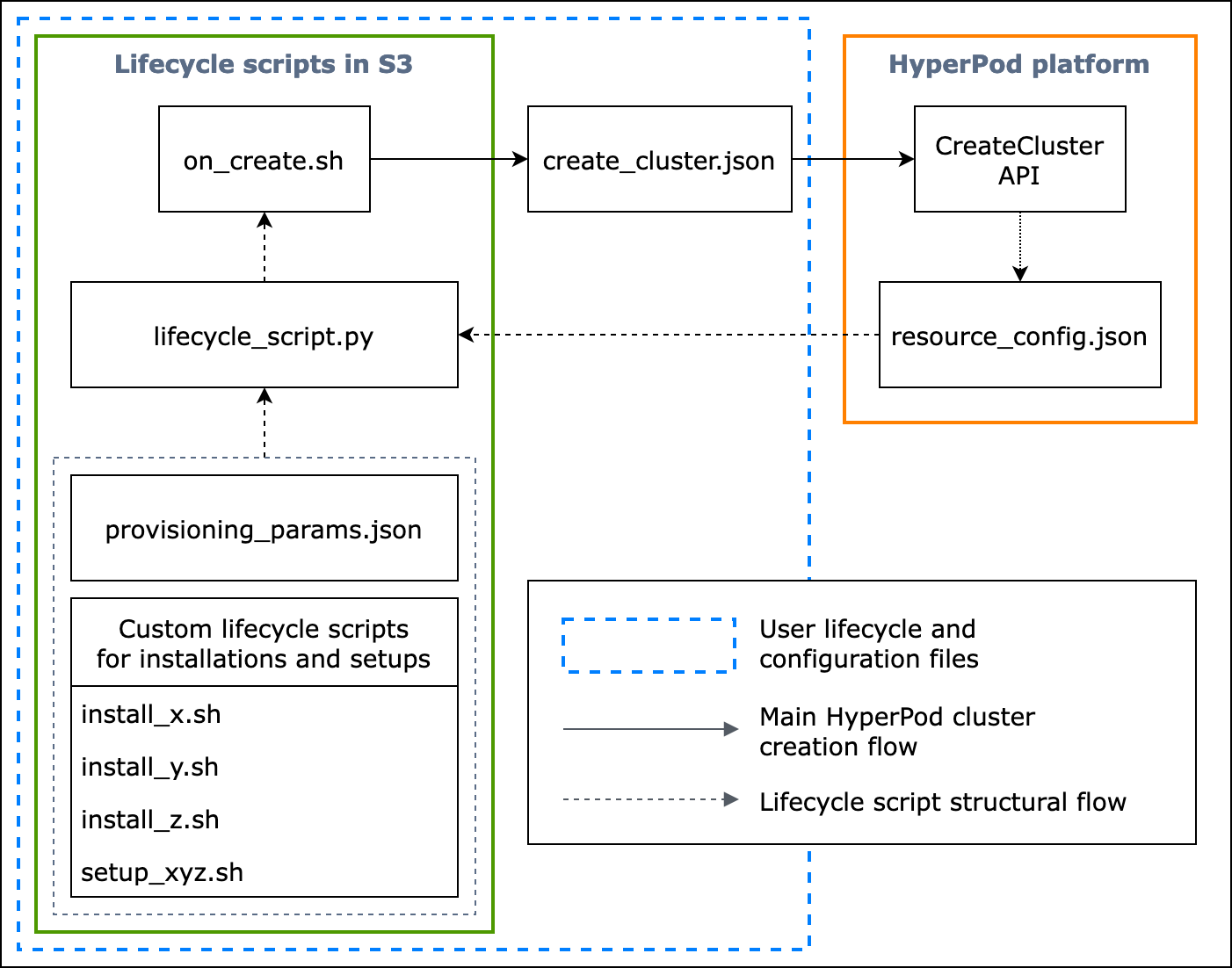
Figure : organigramme détaillé de la création de HyperPod clusters et de la structure des scripts de cycle de vie. (1) Les flèches en pointillés sont dirigées vers l'endroit où les cases sont « appelées » et indiquent le flux de préparation des fichiers de configuration et des scripts de cycle de vie. Cela commence par la préparation provisioning_parameters.json et le cycle de vie des scripts. Ils sont ensuite codés lifecycle_script.py pour une exécution collective dans l'ordre. Et l'exécution du lifecycle_script.py script est effectuée par le script on_create.sh shell, qui doit être exécuté dans le terminal de l' HyperPodinstance. (2) Les flèches continues indiquent le flux principal de création du HyperPod cluster et la manière dont les cases sont « appelées » ou « soumises à ». on_create.shest obligatoire pour la demande de création de cluster, create_cluster.json soit dans le formulaire de demande de cluster, soit dans l'interface utilisateur de la console. Après avoir soumis la demande, HyperPod exécute l'CreateClusterAPI en fonction des informations de configuration fournies par la demande et des scripts de cycle de vie. (3) La flèche en pointillés indique que la HyperPod plateforme crée des instances resource_config.json dans le cluster lors du provisionnement des ressources du cluster. resource_config.jsoncontient des informations sur les ressources du HyperPod cluster, telles que l'ARN du cluster, les types d'instances et les adresses IP. Il est important de noter que vous devez préparer les scripts de cycle de vie pour attendre le resource_config.json fichier lors de la création du cluster. Pour plus d'informations, consultez le guide de procédure ci-dessous.
Le guide de procédure suivant explique ce qui se passe lors de la création d'un HyperPod cluster et explique comment les scripts de cycle de vie de base sont conçus.
-
create_cluster.json— Pour soumettre une demande de création de HyperPod cluster, vous devez préparer un fichier deCreateClusterdemande au format JSON. Dans cet exemple de bonnes pratiques, nous partons du principe que le fichier de demande est nommécreate_cluster.json. Écrivezcreate_cluster.jsonpour approvisionner un HyperPod cluster avec des groupes d'instances. La meilleure pratique consiste à ajouter le même nombre de groupes d'instances que le nombre de nœuds Slurm que vous prévoyez de configurer sur le HyperPod cluster. Assurez-vous de donner des noms distinctifs aux groupes d'instances que vous allez attribuer aux nœuds Slurm que vous prévoyez de configurer.Vous devez également spécifier un chemin de compartiment S3 pour stocker l'ensemble de vos fichiers de configuration et de scripts de cycle de vie
InstanceGroups.LifeCycleConfig.SourceS3Uridans le nom du champ du formulaire deCreateClusterdemande, et spécifier le nom de fichier d'un script shell de point d'entrée (supposons qu'il est nomméon_create.sh) pour.InstanceGroups.LifeCycleConfig.OnCreateNote
Si vous utilisez le formulaire de soumission de cluster dans l'interface utilisateur de la HyperPod console, celle-ci gère le remplissage et l'envoi de la
CreateClusterdemande en votre nom, et exécute l'CreateClusterAPI dans le backend. Dans ce cas, vous n'avez pas besoin de créercreate_cluster.json; assurez-vous plutôt de spécifier les informations de configuration de cluster correctes dans le formulaire de soumission de créer un cluster. -
on_create.sh— Pour chaque groupe d'instances, vous devez fournir un script shell point d'entrée, pour exécuter des commandeson_create.sh, exécuter des scripts pour installer des packages logiciels et configurer l'environnement du HyperPod cluster avec Slurm. Les deux éléments que vous devez préparer sont un élémentprovisioning_parameters.jsonrequis HyperPod pour configurer Slurm et un ensemble de scripts de cycle de vie pour l'installation de progiciels. Ce script doit être écrit pour rechercher et exécuter les fichiers suivants, comme indiqué dans l'exemple de script à l'adresseon_create.sh. Note
Assurez-vous de télécharger l'ensemble complet des scripts de cycle de vie vers l'emplacement S3 que vous spécifiez
create_cluster.json. Vous devez également le placerprovisioning_parameters.jsonau même endroit.-
provisioning_parameters.json— C'est unFormulaire de configuration pour le provisionnement des nœuds Slurm sur HyperPod. Leon_create.shscript trouve ce fichier JSON et définit une variable d'environnement pour identifier le chemin d'accès à celui-ci. Grâce à ce fichier JSON, vous pouvez configurer les nœuds Slurm et les options de stockage telles qu'Amazon FSx pour que Lustre for Slurm communique avec. Dansprovisioning_parameters.json, assurez-vous d'attribuer les groupes d'instances de HyperPod cluster en utilisant les noms que vous avez spécifiéscreate_cluster.jsonaux nœuds Slurm de manière appropriée en fonction de la façon dont vous prévoyez de les configurer.Le schéma suivant montre un exemple de la façon dont les deux fichiers
create_cluster.jsonde configuration JSONprovisioning_parameters.jsondoivent être écrits pour attribuer des groupes d' HyperPod instances aux nœuds Slurm. Dans cet exemple, nous supposons la configuration de trois nœuds Slurm : le nœud contrôleur (gestion), le nœud de connexion (facultatif) et le nœud de calcul (travailleur).Astuce
Pour vous aider à valider ces deux fichiers JSON, l'équipe du HyperPod service fournit un script de validation,
validate-config.py. Pour en savoir plus, consultez Validez les fichiers de configuration JSON avant de créer un cluster Slurm sur HyperPod. 
Figure : Comparaison directe entre la création
create_cluster.jsonde HyperPod clusters et la configurationprovisiong_params.jsonde Slurm. Le nombre de groupes d'instancescreate_cluster.jsondoit correspondre au nombre de nœuds que vous souhaitez configurer en tant que nœuds Slurm. Dans le cas de l'exemple de la figure, trois nœuds Slurm seront configurés sur un HyperPod cluster de trois groupes d'instances. Vous devez attribuer les groupes d'instances du HyperPod cluster aux nœuds Slurm en spécifiant les noms des groupes d'instances en conséquence. -
resource_config.json— Lors de la création du cluster, lelifecycle_script.pyscript est écrit pour attendre unresource_config.jsonfichier de HyperPod. Ce fichier contient des informations sur le cluster, telles que les types d'instances et les adresses IP.Lorsque vous exécutez l'
CreateClusterAPI, HyperPod crée un fichier de configuration des ressources sur la/opt/ml/config/resource_config.jsonbase ducreate_cluster.jsonfichier. Le chemin du fichier est enregistré dans la variable d'environnement nomméeSAGEMAKER_RESOURCE_CONFIG_PATH.Important
Le
resource_config.jsonfichier est généré automatiquement par la HyperPod plateforme et vous n'avez PAS besoin de le créer. Le code suivant montre un exemple deresource_config.jsonce qui serait créé à partir de la création du cluster surcreate_cluster.jsonla base de l'étape précédente, et pour vous aider à comprendre ce qui se passe dans le backend et à quoiresource_config.jsonressemblerait une génération automatique.{ "ClusterConfig": { "ClusterArn": "arn:aws:sagemaker:us-west-2:111122223333:cluster/abcde01234yz", "ClusterName": "your-hyperpod-cluster" }, "InstanceGroups": [ { "Name": "controller-machine", "InstanceType": "ml.c5.xlarge", "Instances": [ { "InstanceName": "controller-machine-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] }, { "Name": "login-group", "InstanceType": "ml.m5.xlarge", "Instances": [ { "InstanceName": "login-group-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] }, { "Name": "compute-nodes", "InstanceType": "ml.trn1.32xlarge", "Instances": [ { "InstanceName": "compute-nodes-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-2", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-3", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-4", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] } ] } -
lifecycle_script.py— Il s'agit du script Python principal qui exécute collectivement les scripts de cycle de vie configurant Slurm sur le HyperPod cluster pendant le provisionnement. Ce script litprovisioning_parameters.jsonetresource_config.jsonextrait les chemins spécifiés ou identifiés danson_create.sh, transmet les informations pertinentes à chaque script de cycle de vie, puis exécute les scripts de cycle de vie dans l'ordre.Les scripts Lifecycle sont un ensemble de scripts que vous pouvez personnaliser en toute flexibilité pour installer des packages logiciels et configurer les configurations nécessaires ou personnalisées lors de la création du cluster, telles que la configuration de Slurm, la création d'utilisateurs, l'installation de Conda ou Docker. L'exemple de
lifecycle_script.pyscript est préparé pour exécuter d'autres scripts de cycle de vie de base dans le référentiel, tels que le lancement de Slurm deamons () start_slurm.sh, le montage d'Amazon FSx pour Lustre ( mount_fsx.sh) et la configuration de la comptabilité MariaDB () et de la comptabilité RDS (). setup_mariadb_accounting.shsetup_rds_accounting.shVous pouvez également ajouter d'autres scripts, les regrouper dans le même répertoire et ajouter des lignes de code pour lifecycle_script.pypermettre l' HyperPod exécution des scripts. Pour plus d'informations sur les scripts de cycle de vie de base, voir également 3.1 Scripts de cyclede vie dans le GitHub référentiel Awsome Distributed Training. Note
HyperPod s'exécute SageMaker HyperPod DLAMI sur chaque instance d'un cluster, et l'AMI dispose de progiciels préinstallés conformes aux compatibilités entre eux et HyperPod aux fonctionnalités. Notez que si vous réinstallez l'un des packages préinstallés, vous êtes responsable de l'installation des packages compatibles et notez que certaines HyperPod fonctionnalités risquent de ne pas fonctionner comme prévu.
Outre les configurations par défaut, d'autres scripts permettant d'installer les logiciels suivants sont disponibles dans le
utilsdossier. Le lifecycle_script.pyfichier est déjà prêt à inclure des lignes de code pour exécuter les scripts d'installation. Consultez les éléments suivants pour rechercher ces lignes et décommenter pour les activer.-
Les lignes de code suivantes concernent l'installation de Docker
, Enroot et Pyxis. Ces packages sont nécessaires pour exécuter des conteneurs Docker sur un cluster Slurm. Pour activer cette étape d'installation, définissez le
enable_docker_enroot_pyxisparamètre surTruedans leconfig.pyfichier. # Install Docker/Enroot/Pyxis if Config.enable_docker_enroot_pyxis: ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_enroot_pyxis.sh").run(node_type) -
Vous pouvez intégrer votre HyperPod cluster à Amazon Managed Service for Prometheus et à Amazon Managed Grafana pour exporter les mesures relatives au cluster et aux nœuds du cluster vers les tableaux de HyperPod bord Amazon Managed Grafana. Pour exporter des métriques et utiliser le tableau de bord Slurm, le tableau de bord
NVIDIA DCGM Exporter et le tableau de bord EFA Metrics sur Amazon Managed Grafana, vous devez installer l'exportateur Slurm pour Prometheus, l'exportateur NVIDIA DCGM et l'exportateur de nœuds EFA. Pour plus d'informations sur l'installation des packages d'exportation et l'utilisation des tableaux de bord Grafana dans un espace de travail Grafana géré par Amazon, consultez. SageMaker HyperPod surveillance des ressources du cluster Pour activer cette étape d'installation, définissez le
enable_observabilityparamètre surTruedans leconfig.pyfichier. # Install metric exporting software and Prometheus for observability if Config.enable_observability: if node_type == SlurmNodeType.COMPUTE_NODE: ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_dcgm_exporter.sh").run() ExecuteBashScript("./utils/install_efa_node_exporter.sh").run() if node_type == SlurmNodeType.HEAD_NODE: wait_for_scontrol() ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_slurm_exporter.sh").run() ExecuteBashScript("./utils/install_prometheus.sh").run()
-
-
-
Assurez-vous de télécharger tous les fichiers de configuration et tous les scripts de configuration de l'étape 2 vers le compartiment S3 que vous avez fourni dans la
CreateClusterdemande de l'étape 1. Supposons, par exemple, que vous disposiezcreate_cluster.jsondes éléments suivants."LifeCycleConfig": { "SourceS3URI": "s3://sagemaker-hyperpod-lifecycle/src", "OnCreate": "on_create.sh" }Ensuite, vous
"s3://sagemaker-hyperpod-lifecycle/src"devez conteniron_create.sh,lifecycle_script.pyprovisioning_parameters.json, et tous les autres scripts de configuration. Supposons que vous ayez préparé les fichiers dans un dossier local comme suit.└── lifecycle_files // your local folder ├── provisioning_parameters.json ├── on_create.sh ├── lifecycle_script.py └── ... // more setup scrips to be fed into lifecycle_script.pyPour télécharger les fichiers, utilisez la commande S3 comme suit.
aws s3 cp --recursive./lifecycle_scriptss3://sagemaker-hyperpod-lifecycle/src
