Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Note
Dans cette section, nous partons du principe que le langage et les modèles d'intégration que vous prévoyez d'utiliser sont déjà déployés. Pour les modèles fournis par AWS, vous devez déjà disposer de l'ARN de votre point de terminaison SageMaker AI ou avoir accès à Amazon Bedrock. Pour les autres fournisseurs de modèles, vous devez disposer de la clé API utilisée pour authentifier et autoriser les demandes adressées à votre modèle.
Jupyter AI prend en charge un large éventail de fournisseurs de modèles et de modèles linguistiques. Consultez la liste des modèles pris en charge
La configuration de Jupyter AI varie selon que vous utilisez l'interface utilisateur du chat ou des commandes magiques.
Configurez votre fournisseur de modèles dans l'interface utilisateur du chat
Note
Vous pouvez configurer plusieurs modèles LLMs et les intégrer en suivant les mêmes instructions. Cependant, vous devez configurer au moins un modèle de langage.
Pour configurer votre interface utilisateur de chat
-
Dans JupyterLab, accédez à l'interface de discussion en choisissant l'icône de discussion (
 ) dans le panneau de navigation de gauche.
) dans le panneau de navigation de gauche. -
Choisissez l'icône de configuration (
 ) dans le coin supérieur droit du volet gauche. Cela ouvre le panneau de configuration de Jupyter AI.
) dans le coin supérieur droit du volet gauche. Cela ouvre le panneau de configuration de Jupyter AI. -
Remplissez les champs relatifs à votre fournisseur de services.
-
Pour les modèles fournis par JumpStart ou Amazon Bedrock
-
Dans la liste déroulante des modèles de langue, sélectionnez
sagemaker-endpointles modèles déployés avec JumpStart oubedrockpour les modèles gérés par Amazon Bedrock. -
Les paramètres varient selon que votre modèle est déployé sur SageMaker AI ou Amazon Bedrock.
-
Pour les modèles déployés avec JumpStart :
-
Entrez le nom de votre point de terminaison dans Nom du point de terminaison, puis le nom Région AWS dans lequel votre modèle est déployé dans Nom de la région. Pour récupérer l'ARN des points de terminaison de l' SageMaker IA, accédez à Inference https://console.aws.amazon.com/sagemaker/
and Endpoints, puis sélectionnez Inference and Endpoints dans le menu de gauche. -
Collez le JSON du schéma de demande adapté à votre modèle, ainsi que le chemin de réponse correspondant pour analyser la sortie du modèle.
Note
Vous trouverez le format de demande et de réponse de différents modèles de JumpStart base dans les exemples de blocs-notes
suivants. Chaque bloc-notes porte le nom du modèle qu'il présente.
-
-
Pour les modèles gérés par Amazon Bedrock : ajoutez le AWS profil contenant vos AWS informations d'identification sur votre système (facultatif), puis le profil Région AWS dans lequel votre modèle est déployé dans le nom de la région.
-
-
(Facultatif) Sélectionnez un modèle d'intégration auquel vous avez accès. Les modèles d'intégration sont utilisés pour capturer des informations supplémentaires à partir de documents locaux, ce qui permet au modèle de génération de texte de répondre aux questions dans le contexte de ces documents.
-
Choisissez Enregistrer les modifications et naviguez jusqu'à l'icône de flèche gauche (
 ) située dans le coin supérieur gauche du volet gauche. Cela ouvre l'interface utilisateur de discussion Jupyter AI. Vous pouvez commencer à interagir avec votre modèle.
) située dans le coin supérieur gauche du volet gauche. Cela ouvre l'interface utilisateur de discussion Jupyter AI. Vous pouvez commencer à interagir avec votre modèle.
-
-
Pour les modèles hébergés par des fournisseurs tiers
-
Dans la liste déroulante des modèles de langue, sélectionnez votre identifiant de fournisseur. Vous pouvez trouver les détails de chaque fournisseur, y compris son identifiant, dans la liste des fournisseurs de modèles de
Jupyter AI. -
(Facultatif) Sélectionnez un modèle d'intégration auquel vous avez accès. Les modèles d'intégration sont utilisés pour capturer des informations supplémentaires à partir de documents locaux, ce qui permet au modèle de génération de texte de répondre aux questions dans le contexte de ces documents.
-
Insérez les clés d'API de vos modèles.
-
Choisissez Enregistrer les modifications et naviguez jusqu'à l'icône de flèche gauche (
) située dans le coin supérieur gauche du volet gauche. Cela ouvre l'interface utilisateur de discussion Jupyter AI. Vous pouvez commencer à interagir avec votre modèle.
-
-
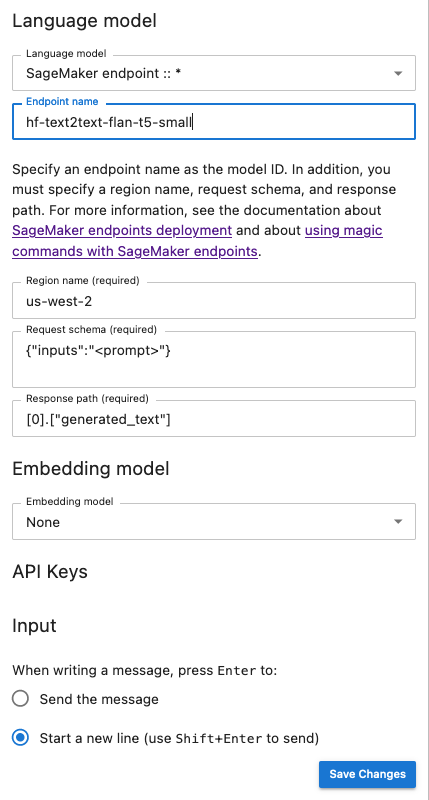
L'instantané suivant est une illustration du panneau de configuration de l'interface utilisateur de chat configuré pour invoquer un modèle FLAN-T5-small fourni JumpStart et déployé dans AI. SageMaker
Transmettez des paramètres de modèle supplémentaires et des paramètres personnalisés à votre demande
Votre modèle peut avoir besoin de paramètres supplémentaires, tels qu'un attribut personnalisé pour l'approbation du contrat utilisateur ou des ajustements d'autres paramètres du modèle tels que la température ou la longueur de réponse. Nous vous recommandons de configurer ces paramètres comme option de démarrage de votre JupyterLab application à l'aide d'une configuration du cycle de vie. Pour plus d'informations sur la façon de créer une configuration de cycle de vie et de l'associer à votre domaine ou à un profil utilisateur depuis la console SageMaker AI
Utilisez le schéma JSON suivant pour configurer vos paramètres supplémentaires :
{
"AiExtension": {
"model_parameters": {
"<provider_id>:<model_id>": { Dictionary of model parameters which is unpacked and passed as-is to the provider.}
}
}
}
}Le script suivant est un exemple de fichier de configuration JSON que vous pouvez utiliser lors de la création d'une JupyterLab application LCC pour définir la longueur maximale d'un modèle AI21Labs Jurassic-2 déployé sur Amazon Bedrock. L'augmentation de la longueur de la réponse générée par le modèle peut empêcher la troncature systématique de la réponse de votre modèle.
#!/bin/bash
set -eux
mkdir -p /home/sagemaker-user/.jupyter
json='{"AiExtension": {"model_parameters": {"bedrock:ai21.j2-mid-v1": {"model_kwargs": {"maxTokens": 200}}}}}'
# equivalent to %%ai bedrock:ai21.j2-mid-v1 -m {"model_kwargs":{"maxTokens":200}}
# File path
file_path="/home/sagemaker-user/.jupyter/jupyter_jupyter_ai_config.json"
#jupyter --paths
# Write JSON to file
echo "$json" > "$file_path"
# Confirmation message
echo "JSON written to $file_path"
restart-jupyter-server
# Waiting for 30 seconds to make sure the Jupyter Server is up and running
sleep 30
Le script suivant est un exemple de fichier de configuration JSON permettant de créer une JupyterLab application LCC utilisée pour définir des paramètres de modèle supplémentaires pour un modèle Anthropic Claude déployé sur Amazon Bedrock.
#!/bin/bash
set -eux
mkdir -p /home/sagemaker-user/.jupyter
json='{"AiExtension": {"model_parameters": {"bedrock:anthropic.claude-v2":{"model_kwargs":{"temperature":0.1,"top_p":0.5,"top_k":25
0,"max_tokens_to_sample":2}}}}}'
# equivalent to %%ai bedrock:anthropic.claude-v2 -m {"model_kwargs":{"temperature":0.1,"top_p":0.5,"top_k":250,"max_tokens_to_sample":2000}}
# File path
file_path="/home/sagemaker-user/.jupyter/jupyter_jupyter_ai_config.json"
#jupyter --paths
# Write JSON to file
echo "$json" > "$file_path"
# Confirmation message
echo "JSON written to $file_path"
restart-jupyter-server
# Waiting for 30 seconds to make sure the Jupyter Server is up and running
sleep 30
Une fois que vous avez rattaché votre LCC à votre domaine, ou profil utilisateur, ajoutez-le à votre espace lors du lancement de votre JupyterLab application. Pour vous assurer que votre fichier de configuration est mis à jour par le LCC, exécutez-le more ~/.jupyter/jupyter_jupyter_ai_config.json dans un terminal. Le contenu du fichier doit correspondre au contenu du fichier JSON transmis au LCC.
Configurez votre fournisseur de modèles dans un bloc-notes
Pour invoquer un modèle via Jupyter AI dans un ordinateur portable JupyterLab ou Studio Classic à l'aide des commandes magiques et %%ai%ai
-
Installez les bibliothèques clientes spécifiques à votre fournisseur de modèles dans l'environnement de votre bloc-notes. Par exemple, lorsque vous utilisez des modèles OpenAI, vous devez installer la bibliothèque
openaicliente. Vous trouverez la liste des bibliothèques clientes requises par fournisseur dans la colonne Package (s) Python de la liste des fournisseurs de Jupyter AI Model. Note
Pour les modèles hébergés par AWS,
boto3est déjà installé dans l'image SageMaker AI Distribution utilisée par JupyterLab ou dans toute image Data Science utilisée avec Studio Classic. -
-
Pour les modèles hébergés par AWS
Assurez-vous que votre rôle d'exécution est autorisé à invoquer votre point de terminaison d' SageMaker IA pour les modèles fournis par Amazon Bedrock JumpStart ou que vous avez accès à celui-ci.
-
Pour les modèles hébergés par des fournisseurs tiers
Exportez la clé API de votre fournisseur dans l'environnement de votre bloc-notes à l'aide de variables d'environnement. Vous pouvez utiliser la commande magique suivante. Remplacez la commande
provider_API_keyin par la variable d'environnement trouvée dans la colonne Variable d'environnement de la liste des fournisseurs de modèlesJupyter AI pour votre fournisseur. %env provider_API_key=your_API_key
-
