Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Environnements RL dans Amazon SageMaker AI
Amazon SageMaker AI RL utilise des environnements pour imiter des scénarios réels. Compte tenu de l’état actuel de l’environnement et de l’action effectuée par le ou les agent, le simulateur traite l’impact de l’action et renvoie l’état suivant ainsi qu’une récompense. Les simulateurs sont utiles lorsqu’il n’est pas prudent d’entraîner un agent dans le monde réel (par exemple, faire voler un drone) ou si l’algorithme d’apprentissage à renforcement met trop de temps à converger (par exemple, lors d’une partie d’échecs).
Le schéma suivant illustre un exemple des interactions avec un simulateur pour un jeu de course.
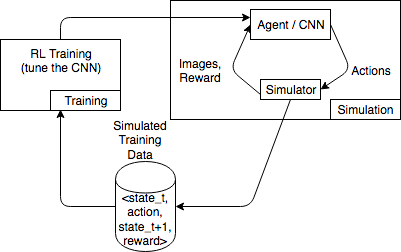
L’environnement de simulation se compose d’un agent et d’un simulateur. Ici, un réseau neuronal convolutif consomme des images depuis le simulateur et génère des actions pour contrôler la manette de jeu. Avec plusieurs simulations, cet environnement génère des données d’entraînement du formulaire state_t, action, state_t+1 et reward_t+1. La définition de la récompense n’est pas futile et impacte la qualité du modèle d’apprentissage à renforcement. Nous souhaitons fournir quelques exemples de fonctionnalités de récompense, mais qui soient configurables par l’utilisateur.
Rubriques
Utiliser l'interface OpenAI Gym pour les environnements dans SageMaker AI RL
Pour utiliser les environnements OpenAI Gym dans SageMaker AI RL, utilisez les éléments d'API suivants. Pour plus d’informations sur OpenAI Gym, consultez Documentation Gym
-
env.action_space—Définit les actions effectuées par l’agent, spécifie si chaque action est continue ou discrète, et si l’action est continue, spécifie le minimum et le maximum. -
env.observation_space—Définit les observations reçues par l’agent depuis l’environnement, ainsi que le minimum et le maximum d’observations continues. -
env.reset()—Initialise un épisode d’entraînement. La fonctionreset()renvoie l’état initial de l’environnement, et l’agent utilise l’état initial pour effectuer sa première action. L’action est alors envoyée àstep()de manière répétée jusqu’à ce que l’épisode atteigne un état terminal. Lorsquestep()renvoiedone = True, l’épisode se termine. La boîte à outils d’apprentissage à renforcement réinitialise l’environnement en appelantreset(). -
step()—Prend l’action de l’agent comme entrée et sort l’état suivant de l’environnement, la récompense, si l’épisode est terminé, et un dictionnaireinfopour communiquer des informations de débogage. Il est de la responsabilité de l’environnement de valider les entrées. -
env.render()—Utilisé pour des environnements à visualisation. La boîte à outils d’apprentissage à renforcement appelle cette fonction pour capturer des visualisations de l’environnement après chaque appel à la fonctionstep().
Open-Source Environnements d'utilisation
Vous pouvez utiliser des environnements open source, tels que EnergyPlus et RoboSchool, dans SageMaker AI RL en créant votre propre conteneur. Pour plus d'informations sur EnergyPlus, voir https://energyplus.net/
Utiliser des environnements commerciaux
Vous pouvez utiliser des environnements commerciaux, tels que MATLAB et Simulink, dans SageMaker AI RL en créant votre propre conteneur. Vous devez gérer vos propres licences.
