Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Déployez des modèles avec Amazon SageMaker Serverless Inference
Amazon SageMaker Serverless Inference est une option d'inférence spécialement conçue qui vous permet de déployer et de faire évoluer des modèles de machine learning sans configurer ni gérer aucune infrastructure sous-jacente. On-demand L'inférence sans serveur est idéale pour les charges de travail qui présentent des périodes d'inactivité entre les pics de trafic et qui peuvent tolérer les démarrages à froid. Les points de terminaison sans serveur lancent automatiquement les ressources de calcul et les mettent à l’échelle en fonction du trafic, éliminant ainsi le besoin de choisir des types d’instances ou de gérer des politiques de mise à l’échelle. Cela supprime les tâches les plus complexes et lourdes de la sélection et de la gestion des serveurs. L’inférence sans serveur s’intègre à AWS Lambda pour vous offrir une haute disponibilité, une tolérance aux pannes intégrée et une mise à l’échelle automatique. Avec un modèle de paiement à l’utilisation, l’inférence sans serveur est une option rentable si vous avez un modèle de trafic peu fréquent ou imprévisible. Pendant les périodes où il n’y a pas de demandes, l’inférence sans serveur réduit votre point de terminaison à 0, vous aidant à minimiser vos coûts. Pour plus d'informations sur la tarification de l'inférence sans serveur à la demande, consultez Amazon SageMaker
(Facultatif) Vous pouvez également utiliser la simultanéité provisionnée avec l’inférence sans serveur. L’inférence sans serveur avec la simultanéité provisionnée est une option rentable lorsque vous êtes confronté à des pics de trafic prévisibles. La concurrence provisionnée vous permet de déployer des modèles sur des terminaux sans serveur avec des performances prévisibles et une évolutivité élevée tout en préservant la chaleur de vos terminaux. SageMaker L'IA garantit que, pour le nombre de simultanéité provisionnée que vous allouez, les ressources de calcul sont initialisées et prêtes à réagir en quelques millisecondes. Pour l’inférence sans serveur avec la simultanéité provisionnée, vous payez en fonction de la capacité de calcul utilisée pour traiter les demandes d’inférence, facturée à la milliseconde et de la quantité de données traitées. Vous payez également pour l’utilisation de la simultanéité provisionnée, en fonction de la mémoire configurée, de la durée allouée et du niveau de simultanéité activé. Pour plus d'informations sur la tarification de l'inférence sans serveur avec concurrence provisionnée, consultez Amazon Pricing. SageMaker
Vous pouvez intégrer Serverless Inference à vos pipelines MLOps pour rationaliser votre flux ML, et vous pouvez utiliser un point de terminaison sans serveur pour héberger un modèle enregistré auprès de Model Registry.
L'inférence sans serveur est généralement disponible dans 21 AWS régions : États-Unis Est (Virginie du Nord), États-Unis Est (Ohio), États-Unis Ouest (Californie du Nord), États-Unis Ouest (Oregon), Afrique (Le Cap), Asie-Pacifique (Hong Kong), Asie-Pacifique (Mumbai), Asie-Pacifique (Tokyo), Asie-Pacifique (Séoul), Asie-Pacifique (Osaka), Asie-Pacifique (Singapour), Asie-Pacifique (Sydney), Canada (Centre), Europe (Francfort), Europe (Irlande), Europe (Londres), Europe (Paris), Europe (Stockholm), Europe (Milan), Moyen-Orient (Bahreïn), Amérique du Sud (São Paulo). Pour plus d'informations sur la disponibilité régionale d'Amazon SageMaker AI, consultez la liste des services AWS régionaux
Comment ça marche
Le diagramme suivant montre le flux de travail d’une inférence sans serveur à la demande et les avantages de l’utilisation d’un point de terminaison sans serveur.
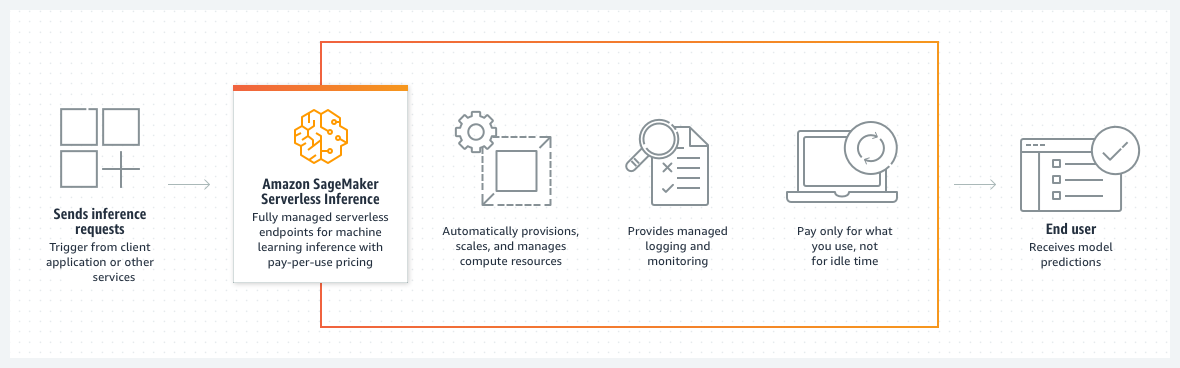
Lorsque vous créez un point de terminaison sans serveur à la demande, l' SageMaker IA approvisionne et gère les ressources de calcul pour vous. Vous pouvez ensuite envoyer des demandes d'inférence au point de terminaison et recevoir les prédictions du modèle en réponse. SageMaker L'IA augmente ou diminue les ressources de calcul selon les besoins pour gérer le trafic de vos demandes, et vous ne payez que pour ce que vous utilisez.
Pour la simultanéité provisionnée, l’inférence sans serveur s’intègre également à Application Auto Scaling, afin que vous puissiez gérer la simultanéité provisionnée en fonction d’une métrique cible ou d’un calendrier. Pour de plus amples informations, veuillez consulter Mise à l’échelle automatique de la simultanéité provisionnée pour un point de terminaison sans serveur.
Les sections suivantes fournissent des détails supplémentaires sur Serverless Inference et son fonctionnement.
Rubriques
Prise en charge du conteneur
Pour le conteneur de votre terminal, vous pouvez choisir un SageMaker AI-provided conteneur ou apporter le vôtre. SageMaker L'IA fournit des conteneurs pour ses algorithmes intégrés et des images Docker prédéfinies pour certains des frameworks d'apprentissage automatique les plus courants, tels qu'Apache MXnet, TensorFlow, PyTorch et Chainer. Pour obtenir la liste des SageMaker images disponibles, consultez Available Deep Learning Containers Images
La taille maximale de l’image de conteneur que vous pouvez utiliser est de 10 Go. Pour les points de terminaison sans serveur, nous vous recommandons de créer un seul employé dans le conteneur et de ne charger qu’une seule copie du modèle. Notez que cela ne ressemble pas aux points de terminaison en temps réel, où certains conteneurs d' SageMaker IA peuvent créer un worker pour chaque vCPU afin de traiter les demandes d'inférence et de charger le modèle dans chaque vCPU.
Si vous disposez déjà d’un conteneur pour un point de terminaison en temps réel, vous pouvez utiliser le même conteneur pour votre point de terminaison sans serveur, bien que certaines fonctionnalités soient exclues. Pour en savoir plus sur les fonctionnalités de conteneur qui ne sont pas prises en charge dans l’inférence sans serveur, consultez Exclusions de fonctions. Si vous choisissez d'utiliser le même conteneur, SageMaker AI séquestre (conserve) une copie de l'image de votre conteneur jusqu'à ce que vous supprimiez tous les points de terminaison qui utilisent l'image. SageMaker L'IA chiffre l'image copiée au repos à l'aide d'une SageMaker AI-owned AWS KMS clé.
Taille de la mémoire
Votre point de terminaison sans serveur a une taille de mémoire RAM minimale de 1 024 Mo (1 Go), et la taille maximale que vous pouvez choisir est de 6 144 Mo (6 Go). Voici les tailles de mémoire parmi lesquelles vous pouvez choisir : 1 024 Mo, 2 048 Mo, 3 072 Mo, 4 096 Mo, 5 120 Mo ou 6 144 Mo. Serverless Inference attribue automatiquement des ressources de calcul proportionnelles à la mémoire que vous sélectionnez. Si vous choisissez une taille de mémoire plus importante, votre conteneur a accès à plus de vCPU. Choisissez la taille de la mémoire de votre point de terminaison en fonction de la taille de votre modèle. En règle générale, la taille de la mémoire doit être au moins aussi grande que celle de votre modèle. Vous devrez peut-être effectuer une analyse comparative afin de choisir la bonne sélection de mémoire pour votre modèle en fonction de vos accords de niveau de service de latence. Pour un guide étape par étape sur le benchmarking, consultez Présentation du kit d'analyse comparative d'Amazon SageMaker Serverless Inference
Quelle que soit la taille de mémoire que vous choisissez, votre point de terminaison sans serveur dispose de 5 Go de stockage de disque éphémère disponible. Pour obtenir de l’aide sur les problèmes d’autorisations de conteneur lors de l’utilisation du stockage, consultez Résolution des problèmes.
Appels simultanés
On-demand Serverless Inference gère des politiques de dimensionnement et des quotas prédéfinis en fonction de la capacité de votre terminal. Les points de terminaison sans serveur ont un quota pour le nombre d'appels simultanés pouvant être traités en même temps. Si le point de terminaison est appelé avant la fin du traitement de la première demande, il traite la deuxième demande simultanément.
La simultanéité totale que vous pouvez partager entre tous les points de terminaison sans serveur dans votre compte dépend de votre région :
-
Pour les régions USA Est (Ohio), USA Est (Virginie du Nord), USA Ouest (Oregon), Asie-Pacifique (Singapour), Asie-Pacifique (Sydney), Asie-Pacifique (Tokyo), Europe (Francfort) et Europe (Irlande), la simultanéité totale que vous pouvez partager entre tous les points de terminaison sans serveur par région dans votre compte est de 1 000.
-
Pour les régions USA Ouest (Californie du Nord), Afrique (Le Cap), Asie-Pacifique (Hong Kong), Asie-Pacifique (Mumbai), Asie-Pacifique (Osaka), Asie-Pacifique (Séoul), Canada (Centre), Europe (Londres), Europe (Milan), Europe (Paris), Europe (Stockholm), Moyen-Orient (Bahreïn) et Amérique du Sud (São Paulo), la simultanéité totale par région dans votre compte est de 500.
Vous pouvez définir la simultanéité maximale à 200 pour un seul point de terminaison, et le nombre total de points de terminaison sans serveur que vous pouvez héberger dans une région est de 50. La simultanéité maximale pour un point de terminaison individuel empêche celui-ci de prendre tous les appels autorisés pour votre compte, et tous les appels de point de terminaison au-delà du maximum sont limités.
Note
La simultanéité provisionnée que vous attribuez à un point de terminaison sans serveur doit toujours être inférieure ou égale à la simultanéité maximale que vous avez attribuée à ce point de terminaison.
Pour savoir comment définir la simultanéité maximale pour votre point de terminaison, consultez Créer une configuration de point de terminaison. Pour plus d'informations sur les quotas et les limites, consultez la section Points de terminaison et quotas Amazon SageMaker AI dans le Références générales AWS. Pour demander une augmentation de la limite de service, contactez le support AWS
Réduction des démarrages à froid
Si votre point de terminaison d’inférence sans serveur à la demande ne reçoit pas de trafic pendant un certain temps, puis reçoit soudainement de nouvelles demandes, il pourrait lui falloir un certain temps pour lancer les ressources de calcul afin de traiter les demandes. C’est ce qu’on appelle un démarrage à froid. Étant donné que les points de terminaison sans serveur fournissent des ressources de calcul à la demande, votre point de terminaison peut connaître des démarrages à froid. Un démarrage à froid peut également avoir lieu si vos demandes simultanées dépassent le taux d’utilisation actuel des demandes simultanées. La durée de démarrage à froid dépend de la taille de votre modèle, du temps qu’il faut pour télécharger votre modèle et de l’heure de démarrage de votre conteneur.
Pour surveiller la durée de votre temps de démarrage à froid, vous pouvez utiliser la CloudWatch métrique Amazon OverheadLatency pour surveiller votre point de terminaison sans serveur. Cette métrique suit le temps nécessaire pour lancer de nouvelles ressources de calcul pour votre point de terminaison. Pour en savoir plus sur l'utilisation CloudWatch des métriques avec des points de terminaison sans serveur, consultez. Alarmes et journaux pour le suivi des métriques provenant des points de terminaison sans serveur
Vous pouvez minimiser les démarrages à froid en utilisant la simultanéité provisionnée. SageMaker L'IA garde le terminal au chaud et le rend prêt à réagir en quelques millisecondes, pour le nombre de simultanéité provisionnée que vous avez alloué.
Exclusions de fonctions
Certaines fonctionnalités actuellement disponibles pour SageMaker AI Real-time Inference ne sont pas prises en charge pour l'inférence sans serveur, notamment les GPU, les packages de modèles AWS Marketplace, les registres Docker privés, les Multi-Model points de terminaison, la configuration VPC, l'isolation du réseau, la capture de données, les variantes de production multiples, Model Monitor et les pipelines d'inférence.
Vous ne pouvez pas convertir votre point de terminaison en temps réel basé sur une instance en un point de terminaison sans serveur. Si vous essayez de mettre à jour votre point de terminaison en temps réel sans serveur, vous recevez un message ValidationError. Vous pouvez convertir un point de terminaison sans serveur en temps réel, mais une fois la mise à jour effectuée, vous ne pouvez pas le restaurer en mode sans serveur.
Prise en main
Vous pouvez créer, mettre à jour, décrire et supprimer un point de terminaison sans serveur à l'aide de la console SageMaker AI, AWS des SDK, du SDK Amazon SageMaker Python
Note
Application Auto Scaling pour l’inférence sans serveur avec la simultanéité provisionnée n’est actuellement pas prise en charge sur AWS CloudFormation.
Exemples de blocs-notes et de blogs
Pour obtenir des exemples de bloc-notes Jupyter qui montrent des flux de point de terminaison sans serveur de bout en bout, consultez l'exemple de bloc-notes Serverless Inference
