Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Automatisez l'étiquetage des données
Si vous le souhaitez, Amazon SageMaker Ground Truth peut utiliser l'apprentissage actif pour automatiser l'étiquetage de vos données d'entrée pour certains types de tâches intégrés. L'apprentissage actif est une technique de machine learning qui identifie les données devant être étiquetées par vos applications de travail. Dans Ground Truth, cette fonctionnalité est appelée étiquetage automatisé des données. L'étiquetage automatisé des données permet de réduire le coût et le temps qu'il faut pour étiqueter votre ensemble de données par rapport à l'utilisation d'êtres humains uniquement. Lorsque vous utilisez l'étiquetage automatique, vous encourez des coûts de SageMaker formation et d'inférence.
Nous vous recommandons d'utiliser l'étiquetage automatisé des données sur de grands ensembles de données, car les réseaux neuronaux utilisés avec l'apprentissage actif nécessitent une quantité importante de données pour chaque nouveau jeu de données. En général, à mesure que davantage de données sont fournies, le potentiel de prédictions de haute précision augmente. Les données ne seront étiquetées automatiquement que si le réseau neuronal utilisé dans le modèle d'étiquetage automatique peut atteindre un niveau de précision acceptable. Par conséquent, avec des jeux de données plus volumineux, il y a plus de possibilités pour étiqueter automatiquement les données, car le réseau neuronal peut atteindre une précision suffisante pour l'étiquetage automatique. L'étiquetage automatisé des données est le plus approprié lorsque vous avez des milliers d'objets de données. Le nombre minimum d'objets autorisés pour l'étiquetage automatisé des données est de 1 250, mais nous suggérons fortement de fournir un minimum de 5 000 objets.
L'étiquetage automatisé des données n'est disponible que pour les types de tâche Ground Truth intégrés suivants :
Les Tâches d'étiquetage en streaming ne prennent pas en charge l'étiquetage automatisé des données.
Pour savoir comment créer un flux de travail d'apprentissage actif personnalisé à l'aide de votre propre modèle, veuillez consulter Configurer un flux de travail d'apprentissage actif avec votre propre modèle.
Les quotas de données d'entrée s'appliquent aux tâches d'étiquetage automatique. Veuillez consulter Quotas de données d'entrée pour des informations sur la taille du jeu de données, la taille des données source et les limites de résolution.
Note
Avant d'utiliser un modèle d'étiquetage automatique en production, vous devez affiner ou tester le modèle, ou les deux. Vous pouvez affiner le modèle (ou créer et régler un autre modèle supervisé de votre choix) sur le jeu de données produit par votre travail d'étiquetage afin d'optimiser l'architecture du modèle et les hyperparamètres. Si vous décidez d'utiliser le modèle pour l'inférence sans l'ajuster, nous vous recommandons vivement de vous assurer que sa précision a été évaluée sur un sous-ensemble représentatif (sélectionné de façon aléatoire, par exemple) du jeu de données étiqueté avec Ground Truth et qu'elle correspond à vos attentes.
Comment ça marche
Vous activez l'étiquetage automatisé des données lorsque vous créez une tâche d'étiquetage. Voici comment cela fonctionne :
-
Lorsque Ground Truth démarre une tâche d'étiquetage de données automatisée, il sélectionne un échantillon aléatoire de données d'entrée (objets) et l'envoie aux employés humains. Si plus de 10 % de ces objets de données échouent, la tâche d'étiquetage échoue. Si la tâche d'étiquetage échoue, en plus d'examiner tout message d'erreur renvoyé par Ground Truth, vérifiez que vos données d'entrée s'affichent correctement dans l'interface utilisateur employé, que les instructions sont claires et que vous avez donné suffisamment de temps aux employés pour effectuer des tâches.
-
Lorsque les données étiquetées sont renvoyées, elles sont utilisées pour créer un jeu d'entraînement et un jeu de validation. Ground Truth utilise ces jeux de données pour entraîner et valider le modèle utilisé pour l'étiquetage automatique.
-
Ground Truth exécute une tâche de transformation par lots, en utilisant le modèle validé pour inférence sur les données de validation. L'inférence par lots produit un score de confiance et une mesure de qualité pour chaque objet dans les données de validation.
-
Le composant d'étiquetage automatique utilisera ces métriques de qualité et ces scores de fiabilité pour créer un seuil de score de fiabilité qui garantit des étiquettes de qualité.
-
Ground Truth exécute une tâche de transformation par lots sur les données non étiquetées dans le jeu de données, en utilisant le même modèle validé pour l'inférence. Cela produira un score de fiabilité pour chaque objet.
-
Le composant d'étiquetage automatique Ground Truth détermine si le score de fiabilité produit à l'étape 5 pour chaque objet atteint le seuil requis déterminé à l'étape 4. Si le score de fiabilité correspond au seuil, la qualité attendue de l'étiquetage automatique dépasse le niveau de précision demandé et l'objet est considéré comme étiqueté automatiquement.
-
L'étape 6 produit un jeu de données de données non étiquetées avec des scores de fiabilité. Ground Truth sélectionne les points de données dont les scores de fiabilité sont faibles à partir de ce jeu de données et les envoie aux employés humains.
-
Ground Truth utilise les données existantes étiquetées par l'homme et ces données étiquetées supplémentaires provenant des employés humains pour entraîner un nouveau modèle.
-
Le processus est répété jusqu'à ce que le jeu de données soit complètement étiqueté ou jusqu'à ce qu'une autre condition d'arrêt soit remplie. Par exemple, l'étiquetage automatique s'arrêtera si votre budget d'annotations humaines est atteint.
Les étapes précédentes se produisent dans en itérations. Sélectionnez chaque onglet dans le tableau suivant pour voir un exemple des processus qui se produisent dans chaque itération pour une tâche d'étiquetage automatisé de détection d'objet. Le nombre d'objets de données utilisés dans une étape donnée dans ces images (par exemple, 200) est spécifique à cet exemple. S'il y a moins de 5 000 objets à étiqueter, la taille du jeu de validation correspond à 20 % de l'ensemble du jeu de données. S'il y a plus de 5 000 objets dans votre jeu de données source, la taille du jeu de validation correspond à 10 % de l'ensemble du jeu de données. Vous pouvez contrôler le nombre d'étiquettes humaines collectées par itération d'apprentissage active en modifiant la valeur associée à l'MaxConcurrentTaskCountutilisation de l'APIopération CreateLabelingJob. Cette valeur est définie sur 1 000 lorsque vous créez une tâche d'étiquetage à l'aide de la console. Dans le flux d'apprentissage actif illustré sous Formation active, cette valeur est définie sur 200.
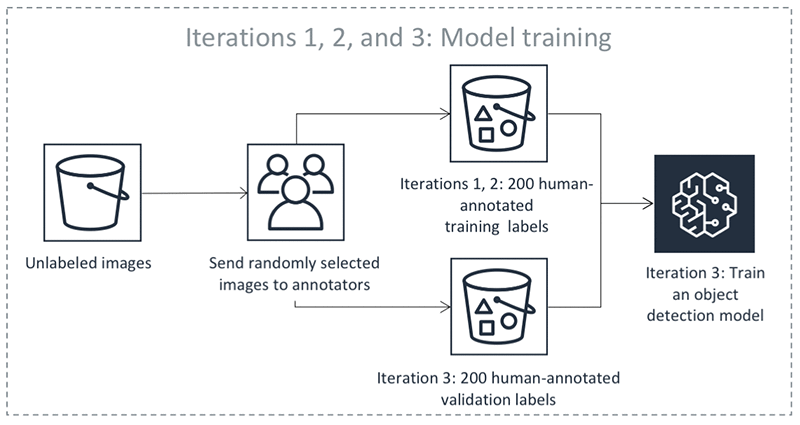
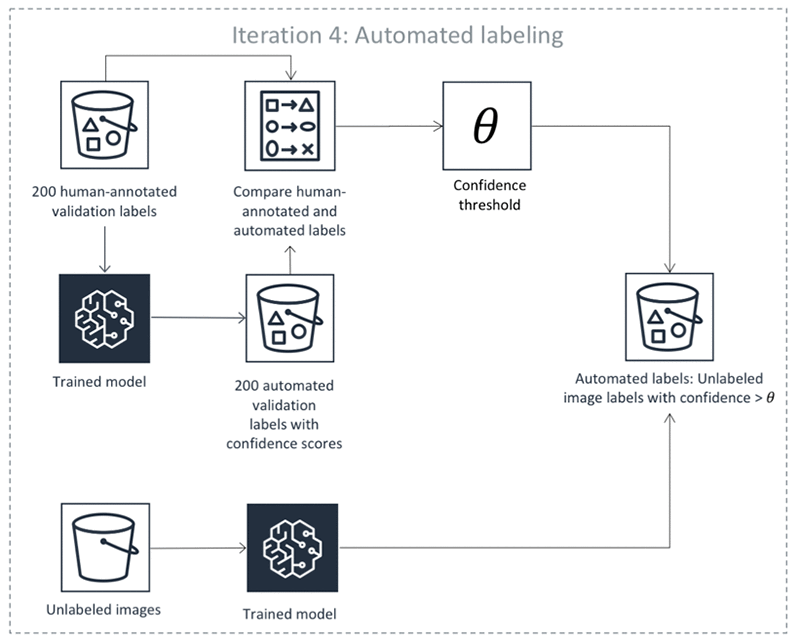
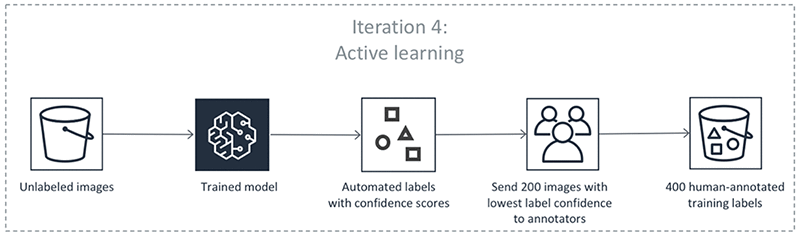
Précision des étiquettes automatisées
La définition de la précision dépend du type de tâche intégré que vous utilisez avec l'étiquetage automatisé. Pour tous les types de tâches, ces exigences de précision sont prédéterminées par Ground Truth et ne peuvent pas être configurées manuellement.
-
Pour la classification d'image et la classification de texte, Ground Truth utilise la logique pour trouver un niveau de fiabilité de prédiction d'étiquette qui correspond à au moins 95 % de précision d'étiquette. Cela signifie que Ground Truth s'attend à ce que l'exactitude des étiquettes automatisées soit d'au moins 95 % par rapport aux étiquettes que les étiqueteurs humains fourniraient pour ces exemples.
-
Pour les cadres de délimitation, la moyenne attendue Intersection sur Union (IoU)
des images auto-étiquetées est de 0,6. Pour trouver l'IoU moyenne, Ground Truth calcule l'IoU moyenne de toutes les cases prévues et manquées sur l'image pour chaque classe, puis fait la moyenne de ces valeurs entre les classes. -
Pour la segmentation sémantique, l'IoU moyenne attendue des images étiquetées automatiquement est de 0,7. Pour trouver l'IoU moyenne, Ground Truth prend la moyenne des valeurs IoU de toutes les classes de l'image (à l'exclusion de l'arrière-plan).
À chaque itération de l'apprentissage actif (étapes 3 à 6 de la liste ci-dessus), le seuil de fiabilité est trouvé à l'aide du jeu de validation annoté par l'homme afin que la précision attendue des objets étiquetés automatiquement satisfasse à certaines exigences de précision prédéfinies.
Création d'une tâche d'étiquetage automatique des données (console)
Pour créer une tâche d'étiquetage utilisant l'étiquetage automatique dans la SageMaker console, suivez la procédure suivante.
Pour créer un travail d'étiquetage automatisé des données (console)
-
Ouvrez la section des jobs de Ground Truth Labeling de la SageMaker console :https://console.aws.amazon.com/sagemaker/groundtruth
. -
En utilisant Création d'une tâche d'étiquetage (Console) comme guide, remplissez les sections Job overview (Présentation de la tâche) et Task type (Type de tâche). Notez que l'étiquetage automatique n'est pas pris en charge pour les types de tâches personnalisés.
-
Sous Workers (Collaborateurs), choisissez votre type de main-d'œuvre.
-
Dans la même section, choisissez Activer l'étiquetage automatisé des données.
-
En vous Configuration de l'outil Bounding Box servant de guide, créez des instructions pour les utilisateurs dans la section
Task Typeoutil d'étiquetage. Par exemple, si vous avez sélectionné Semantic segmentation (Segmentation sémantique) comme type de tâche d'étiquetage, cette section sera intitulée Semantic segmentation labeling tool (Outil d'étiquetage de segmentation sémantique). -
Pour afficher un aperçu des instructions et du tableau de bord de votre collaborateur, choisissez Aperçu.
-
Sélectionnez Create (Créer). Cela va créer et démarrer votre tâche d'étiquetage et le processus d'étiquetage automatique.
Vous pouvez voir votre tâche d'étiquetage apparaître dans la section Tâches d'étiquetage de la SageMaker console. Vos données de sortie apparaîtront dans le compartiment Amazon S3 que vous avez spécifié lors de la création de la tâche d'étiquetage. Pour plus d'informations sur le format et la structure de fichiers de vos données de sortie de tâche d'étiquetage, reportez-vous à la section Étiquetage des données de sortie des tâches.
Création d'une tâche d'étiquetage automatique des données (API)
Pour créer une tâche d'étiquetage automatique des données à l'aide de SageMaker API, utilisez le LabelingJobAlgorithmsConfigparamètre de l'CreateLabelingJobopération. Pour savoir comment démarrer une tâche d'étiquetage à l'aide de l'opération CreateLabelingJob, veuillez consulter Création d'une tâche d'étiquetage (API).
Spécifiez le nom de ressource Amazon (ARN) de l'algorithme que vous utilisez pour l'étiquetage automatique des données dans le LabelingJobAlgorithmSpecificationArnparamètre. Choisissez parmi l'un des quatre algorithmes intégrés Ground Truth pris en charge par l'étiquetage automatisé :
Lorsqu'une tâche d'étiquetage automatique des données est terminée, Ground Truth renvoie le ARN modèle utilisé pour la tâche d'étiquetage automatique des données. Utilisez ce modèle comme modèle de départ pour des types de tâches d'étiquetage automatique similaires en fournissant leARN, sous forme de chaîne, dans le InitialActiveLearningModelArnparamètre. Pour récupérer le modèleARN, utilisez une commande AWS Command Line Interface (AWS CLI) similaire à la suivante.
# Fetch the mARN of the model trained in the final iteration of the previous labeling job.Ground Truth pretrained_model_arn = sagemaker_client.describe_labeling_job(LabelingJobName=job_name)['LabelingJobOutput']['FinalActiveLearningModelArn']
Pour chiffrer les données du volume de stockage attaché aux instances de calcul ML utilisées pour l'étiquetage automatique, incluez une clé AWS Key Management Service (AWS KMS) dans le VolumeKmsKeyId paramètre. Pour plus d'informations sur AWS KMS les clés, voir Qu'est-ce que le service de gestion des AWS clés ? dans le Guide du développeur du service de gestion des AWS clés.
Pour un exemple qui utilise l'CreateLabelingJobopération pour créer une tâche d'étiquetage automatique des données, consultez l'exemple object_detection_tutorial dans la section Examples, SageMaker Ground Truth Labeling Jobs d'une instance de bloc-notes. SageMaker Pour découvrir comment créer et ouvrir une instance de bloc-notes, consultez Création d'une instance de SageMaker bloc-notes Amazon. Pour savoir comment accéder à des SageMaker exemples de blocs-notes, voirAccédez à des exemples de blocs-notes.
EC2Instances Amazon requises pour l'étiquetage automatique des données
Le tableau suivant répertorie les instances Amazon Elastic Compute Cloud (AmazonEC2) dont vous avez besoin pour exécuter l'étiquetage automatique des données pour les tâches de formation et d'inférence par lots.
| Type de tâche d'étiquetage automatisé des données | Type d'instance d'entraînement | Type d'instance d'inférence |
|---|---|---|
|
Classification d'image |
ml.p3.2xlarge* |
ml.c5.xlarge |
|
Détection d'objet (cadre de délimitation) |
ml.p3.2xlarge* |
ml.c5.4xlarge |
|
Classification de texte |
ml.c5.2xlarge |
ml.m4.xlarge |
|
Segmentation sémantique |
ml.p3.2xlarge* |
ml.p3.2xlarge* |
* Dans la région Asie-Pacifique (Mumbai) (ap-south-1), utilisez ml.p2.8xlarge à la place.
Ground Truth gère les instances que vous utilisez pour les tâches d'étiquetage automatisé des données. Il crée, configure et met fin aux instances selon les besoins pour effectuer votre travail. Ces instances n'apparaissent pas dans le tableau de bord de votre EC2 instance Amazon.
Configurer un flux de travail d'apprentissage actif avec votre propre modèle
Vous pouvez créer un flux de travail d'apprentissage actif avec votre propre algorithme pour exécuter des entraînements et des inférences dans ce flux de travail afin d'étiqueter automatiquement vos données. Le bloc-notes bring_your_own_model_for_sagemaker_labeling_workflows_with_active_learning.ipynb le montre à l'aide de l'algorithme intégré,. SageMaker BlazingText Ce bloc-notes fournit une AWS CloudFormation pile que vous pouvez utiliser pour exécuter ce flux de travail à l'aide de AWS Step Functions. Vous trouverez le bloc-notes et les fichiers de support dans ce GitHub référentiel
Vous pouvez également trouver ce bloc-notes dans le référentiel SageMaker d'exemples. Consultez Utiliser des exemples de blocs-notes pour savoir comment trouver un SageMaker exemple de bloc-notes Amazon.
