Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Transférez les événements Amazon SNS à Event Fork AWS Pipelines
| Pour l'archivage et l'analyse des événements, Amazon SNS recommande désormais d'utiliser son intégration native avec Amazon Data Firehose. Vous pouvez abonner les flux de diffusion Firehose aux rubriques SNS, ce qui vous permet d'envoyer des notifications aux points de terminaison d'archivage et d'analyse tels que les buckets Amazon Simple Storage Service (Amazon S3), les tables Amazon Redshift, Amazon Service (Service), etc. OpenSearch OpenSearch L'utilisation d'Amazon SNS avec les flux de diffusion Firehose est une solution entièrement gérée et sans code qui ne nécessite pas l'utilisation de fonctions. AWS Lambda Pour de plus amples informations, veuillez consulter Streams de diffusion de Fanout to Firehose. |
Vous pouvez utiliser Amazon SNS pour créer des applications qui reposent sur les événements et utilisent les services d'abonné afin d'exécuter automatiquement des tâches en réponse à des événements déclenchés par ses services d'éditeur. Ce modèle d'architecture peut rendre des services plus réutilisables, interopérables et évolutifs. Toutefois, il peut être fastidieux de traiter les événements via des pipelines qui répondent aux exigences courantes de gestion des événements, par exemple la sauvegarde, le stockage, la recherche, l'analytique et la relecture d'événements.
Pour accélérer le développement de vos applications basées sur les événements, vous pouvez abonner des pipelines de gestion d'événements, alimentés par Event Fork AWS Pipelines, à des rubriques Amazon SNS. AWS Event Fork Pipelines est une suite d'applications imbriquées open source, basée sur le modèle d'application AWS sans serveur
Pour un AWS cas d'utilisation d'Event Fork Pipelines, voirDéploiement et test de l'exemple d'application Amazon SNS Event Fork Pipelines.
Rubriques
Comment fonctionne AWS Event Fork Pipelines
AWS Event Fork Pipelines est un modèle de conception sans serveur. Cependant, il s'agit également d'une suite d'applications sans serveur imbriquées basées sur le AWS SAM (que vous pouvez déployer directement depuis le AWS Serverless Application Repository (AWS SAR) sur votre site Compte AWS afin d'enrichir vos plateformes axées sur les événements). Vous pouvez déployer ces applications imbriquées individuellement, comme requis par votre architecture.
Rubriques
Le schéma suivant montre une application AWS Event Fork Pipelines complétée par trois applications imbriquées. Vous pouvez déployer n'importe lequel des pipelines de la suite AWS Event Fork Pipelines sur le AWS SAR indépendamment, selon les exigences de votre architecture.
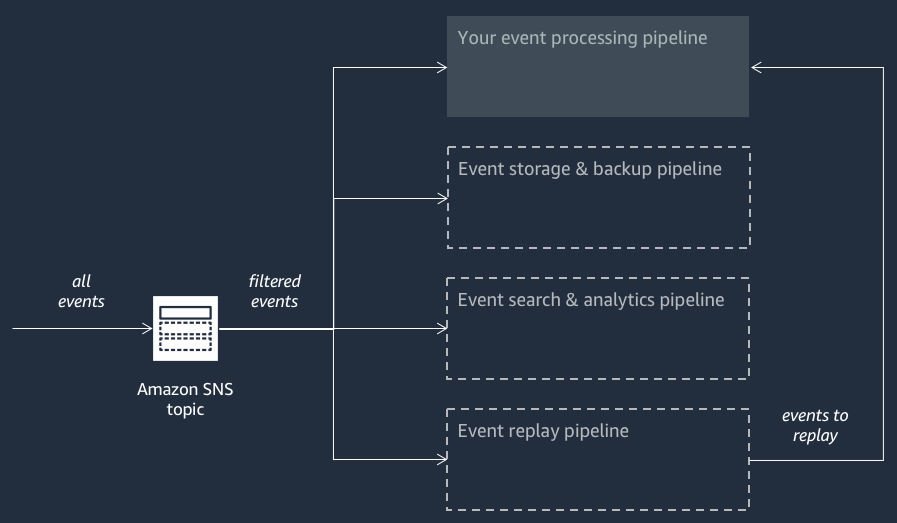
Chaque pipeline est abonné à la même rubrique Amazon SNS, ce qui lui permet de traiter les événements en parallèle au fur et à mesure de leur publication dans la rubrique. Chaque pipeline est indépendant et peut définir sa propre politique de filtre d'abonnement. Cela permet à un pipeline de traiter uniquement un sous-ensemble des événements qui l'intéressent (plutôt que tous les événements publiés dans la rubrique).
Note
Comme vous placez les trois pipelines AWS Event Fork à côté de vos pipelines de traitement d'événements habituels (peut-être déjà abonnés à votre rubrique Amazon SNS), vous n'avez pas besoin de modifier une partie de votre éditeur de messages actuel pour tirer parti des pipelines AWS Event Fork dans vos charges de travail existantes.
Pipeline de stockage et de sauvegarde d'événements
Le diagramme suivant montre le Pipeline de stockage et de sauvegarde d'événements
Ce pipeline est composé d'une file d'attente Amazon SQS qui met en mémoire tampon les événements transmis par la rubrique Amazon SNS, d'une AWS Lambda fonction qui interroge automatiquement ces événements dans la file d'attente et les place dans un flux Amazon Data Firehose, et d'un compartiment Amazon S3 qui sauvegarde de manière durable les événements chargés par le flux.
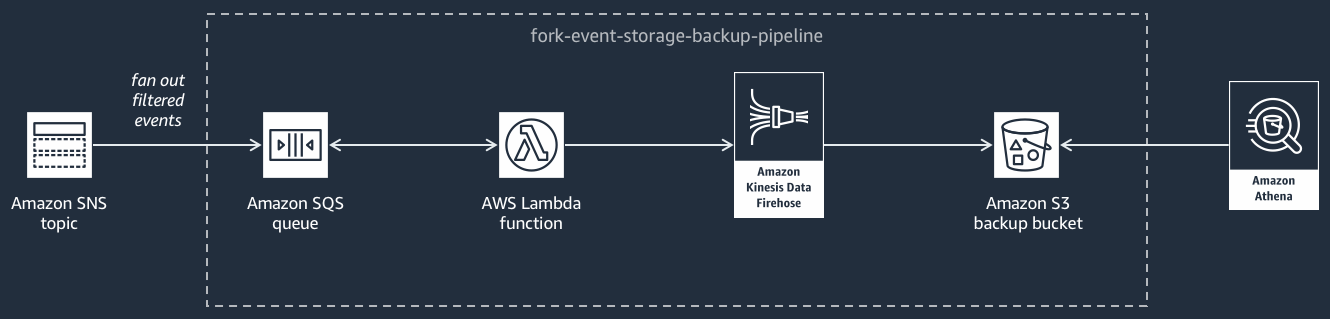
Pour affiner le comportement de votre flux Firehose, vous pouvez le configurer de façon à ce qu'il mette en tampon, transforme et compresse vos événements avant de les charger dans le compartiment. Pendant le chargement des événements , vous pouvez utiliser Amazon Athena pour interroger le compartiment à l'aide de requêtes SQL standard. Vous pouvez également configurer le pipeline de façon à réutiliser un compartiment Amazon S3 existant ou à en créer un nouveau.
Le pipeline de recherche et d'analyse d'événements
Le diagramme suivant montre le Pipeline de recherche et d'analyse d'événements
Ce pipeline est composé d'une file d'attente Amazon SQS qui met en mémoire tampon les événements fournis par la rubrique Amazon SNS, d'une AWS Lambda fonction qui extrait les événements de la file d'attente et les envoie dans un flux Amazon Data Firehose, d'un domaine OpenSearch Amazon Service qui indexe les événements chargés par le flux Firehose et d'un compartiment Amazon S3 qui stocke les événements en lettre morte qui ne peuvent pas être indexés dans le domaine de recherche.
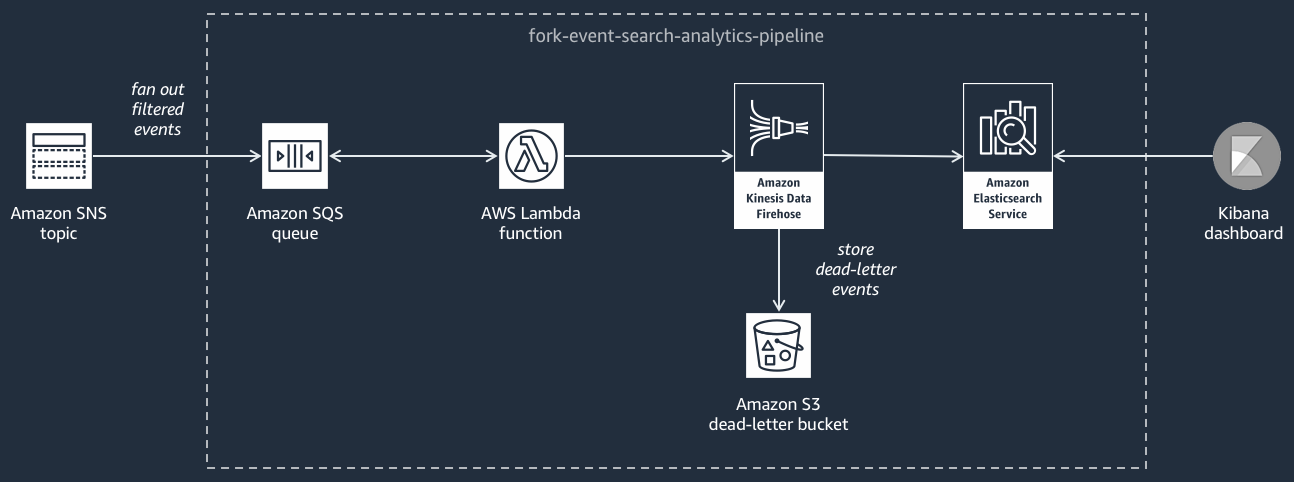
Pour affiner votre flux Firehose en termes de mise en mémoire tampon, de transformation et de compression des événements, vous pouvez configurer ce pipeline.
Vous pouvez également configurer si le pipeline doit réutiliser un OpenSearch domaine existant dans votre domaine Compte AWS ou en créer un nouveau pour vous. Lorsque les événements sont indexées dans le domaine de recherche, vous pouvez utiliser Kibana pour exécuter des analyses sur vos événements et mettre à jour les tableaux de bord visuels en temps réel.
Le pipeline de relecture d'événements
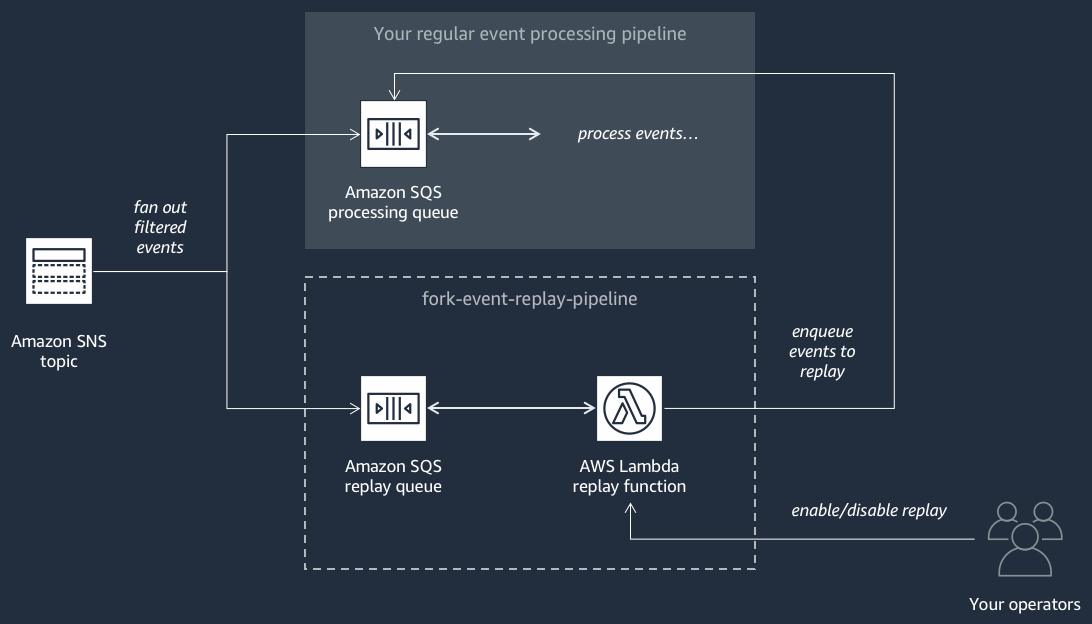
Le diagramme suivant montre le Pipeline de relecture d'événements
Ce pipeline est composé d'une file d'attente Amazon SQS qui met en mémoire tampon les événements transmis par la rubrique Amazon SNS, et d'une AWS Lambda fonction qui interroge les événements de la file d'attente et les réachemine vers votre pipeline de traitement des événements normal, qui est également abonné à votre sujet.
Note
Par défaut, la fonction de relecture est désactivée et ne relance pas vos événements. Si vous avez besoin de retraiter les événements, vous devez activer la file d'attente de relecture Amazon SQS en tant que source d'événement pour la fonction de relecture AWS Lambda .
Déploiement de pipelines AWS Event Fork
La suite AWS Event Fork Pipelines
Dans un scénario de production, nous vous recommandons d'intégrer AWS Event Fork Pipelines dans le modèle AWS SAM global de votre application. La fonctionnalité d'application imbriquée vous permet de le faire en ajoutant la ressource AWS::Serverless::Application à votre modèle AWS SAM, en référençant le AWS SAR ApplicationId et le SemanticVersion de l'application imbriquée.
Par exemple, vous pouvez utiliser l'Event Storage and Backup Pipeline en tant qu'application imbriquée en ajoutant l'extrait YAML suivant à la Resources section de votre modèle SAM. AWS
Backup:
Type: AWS::Serverless::Application
Properties:
Location:
ApplicationId: arn:aws:serverlessrepo:us-east-2:123456789012:applications/fork-event-storage-backup-pipeline
SemanticVersion: 1.0.0
Parameters:
#The ARN of the Amazon SNS topic whose messages should be backed up to the Amazon S3 bucket.
TopicArn: !Ref MySNSTopicLorsque vous spécifiez des valeurs de paramètres, vous pouvez utiliser des fonctions AWS CloudFormation intrinsèques pour référencer d'autres ressources dans votre modèle. Par exemple, dans l'extrait YAML ci-dessus, le TopicArn paramètre fait référence à la AWS::SNS::Topic ressourceMySNSTopic, définie ailleurs dans le modèle. AWS SAM Pour plus d'informations, consultez la section de Référence des fonctions intrinsèques dans le AWS CloudFormation Guide de l'utilisateur.
Note
La page de AWS Lambda console de votre application AWS SAR inclut le bouton Copier en tant que ressource SAM, qui copie le code YAML requis pour imbriquer une application AWS SAR dans le presse-papiers.
