Pour des fonctionnalités similaires à celles d'Amazon Timestream pour, pensez à Amazon Timestream LiveAnalytics pour InfluxDB. Il permet une ingestion simplifiée des données et des temps de réponse aux requêtes à un chiffre en millisecondes pour des analyses en temps réel. Pour en savoir plus, cliquez ici.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Architecture
Amazon Timestream for Live Analytics a été entièrement conçu pour collecter, stocker et traiter des séries chronologiques à grande échelle. Son architecture sans serveur prend en charge des systèmes d'ingestion de données, de stockage et de traitement des requêtes totalement découplés qui peuvent évoluer indépendamment. Cette conception simplifie chaque sous-système, ce qui permet d'atteindre une fiabilité sans faille, d'éliminer les goulots d'étranglement liés à la mise à l'échelle et de réduire les risques de défaillances du système corrélées. Chacun de ces facteurs prend de l'importance à mesure que le système évolue.
Rubriques
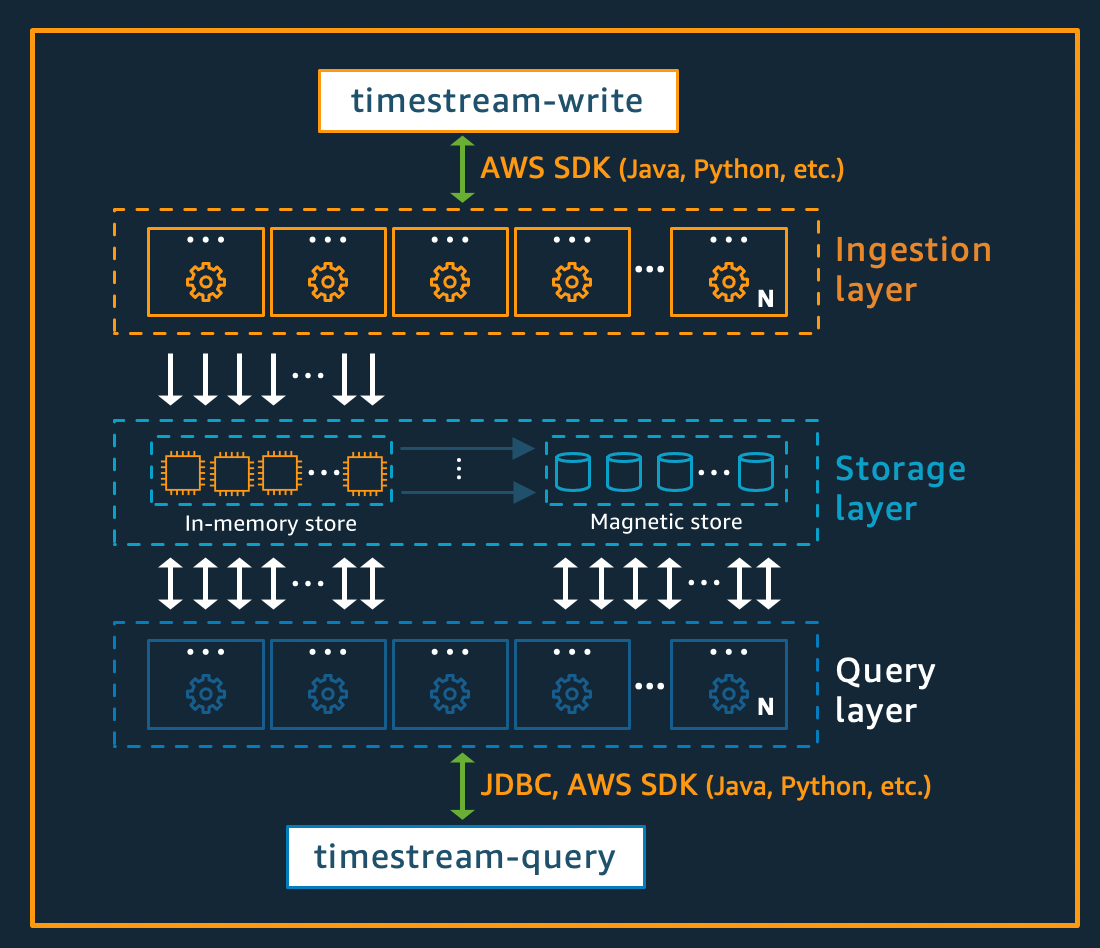
Écrivez de l'architecture
Lors de l'écriture de données chronologiques, Amazon Timestream for Live Analytics achemine les données d'une table ou d'une partition vers une instance de mémoire tolérante aux pannes qui traite les écritures de données à haut débit. La mémoire assure à son tour la durabilité dans un système de stockage distinct qui réplique les données sur trois zones de disponibilité ()AZs. La réplication est basée sur le quorum, de sorte que la perte de nœuds, ou d'une zone de disponibilité complète, ne perturbe pas la disponibilité en écriture. En temps quasi réel, d'autres nœuds de stockage en mémoire se synchronisent avec les données afin de répondre aux requêtes. Les nœuds de réplication du lecteur s'étendent AZs également, afin de garantir une haute disponibilité en lecture.
Timestream for Live Analytics prend en charge l'écriture de données directement dans le magasin magnétique, pour les applications générant des données tardives à faible débit. Les données arrivées tardivement sont des données dont l'horodatage est antérieur à l'heure actuelle. À l'instar des écritures à haut débit dans la mémoire, les données écrites dans la mémoire magnétique sont répliquées sur trois unités AZs et la réplication est basée sur le quorum.
Que les données soient écrites dans la mémoire ou dans le stockage magnétique, Timestream for Live Analytics indexe et partitionne automatiquement les données avant de les enregistrer dans le stockage. Une seule table Timestream for Live Analytics peut comporter des centaines, des milliers, voire des millions de partitions. Les partitions individuelles ne communiquent pas directement entre elles et ne partagent aucune donnée (architecture sans partage). Au lieu de cela, le partitionnement d'une table est suivi via un service de suivi et d'indexation des partitions à haute disponibilité. Cela permet une autre séparation des préoccupations, conçue spécifiquement pour minimiser l'effet des défaillances dans le système et réduire considérablement la probabilité de défaillances corrélées.
Architecture de stockage
Lorsque les données sont stockées dans Timestream for Live Analytics, elles sont organisées par ordre chronologique et dans le temps en fonction des attributs contextuels écrits avec les données. Il est important de disposer d'un schéma de partitionnement qui divise « l'espace » en plus du temps pour dimensionner massivement un système de séries chronologiques. Cela est dû au fait que la plupart des données de séries chronologiques sont écrites à l'heure actuelle ou aux alentours de cette date. Par conséquent, le partitionnement basé uniquement sur le temps ne permet pas de répartir correctement le trafic d'écriture ou de permettre un élagage efficace des données au moment de la requête. C'est important pour le traitement de séries chronologiques à grande échelle, et cela a permis à Timestream for Live Analytics d'augmenter de plusieurs ordres de grandeur par rapport aux autres principaux systèmes actuels en mode sans serveur. Les partitions qui en résultent sont appelées « tuiles » car elles représentent les divisions d'un espace bidimensionnel (conçues pour être de taille similaire). Pour les tables Live Analytics, Timestream commence par une partition unique (tuile), puis se divise dans la dimension spatiale en fonction du débit. Lorsque les tuiles atteignent une certaine taille, elles se divisent dans la dimension temporelle afin d'obtenir un meilleur parallélisme de lecture à mesure que la taille des données augmente.
Timestream for Live Analytics est conçu pour gérer automatiquement le cycle de vie des données de séries chronologiques. Timestream for Live Analytics propose deux magasins de données : un stockage en mémoire et un magasin magnétique rentable. Il prend également en charge la configuration de politiques au niveau des tables pour transférer automatiquement les données entre les boutiques. Les écritures de données à haut débit entrantes arrivent dans la mémoire, où les données sont optimisées pour les écritures, ainsi que pour les lectures effectuées à l'heure actuelle pour alimenter les requêtes de type tableau de bord et alertes. Lorsque le délai principal pour les besoins d'écriture, d'alerte et de tableau de bord est dépassé, les données peuvent circuler automatiquement de la mémoire vers la mémoire magnétique afin d'optimiser les coûts. Timestream for Live Analytics permet de définir une politique de conservation des données sur la mémoire à cette fin. Les écritures de données pour les données arrivées en retard sont directement enregistrées dans le magasin magnétique.
Une fois que les données sont disponibles dans la mémoire magnétique (en raison de l'expiration de la période de conservation de la mémoire ou en raison d'écritures directes dans la mémoire magnétique), elles sont réorganisées dans un format hautement optimisé pour les lectures de gros volumes de données. La mémoire magnétique dispose également d'une politique de conservation des données qui peut être configurée s'il existe un seuil temporel pendant lequel les données ne sont plus utiles. Lorsque les données dépassent la plage de temps définie pour la politique de conservation des mémoires magnétiques, elles sont automatiquement supprimées. Par conséquent, avec Timestream for Live Analytics, outre certaines configurations, la gestion du cycle de vie des données s'effectue de manière fluide en arrière-plan.
Architecture des requêtes
Les requêtes Timestream for Live Analytics sont exprimées dans une grammaire SQL dotée d'extensions pour le support spécifique aux séries chronologiques (types de données et fonctions spécifiques aux séries chronologiques), ce qui facilite l'apprentissage pour les développeurs déjà familiarisés avec le SQL. Les requêtes sont ensuite traitées par un moteur de requêtes adaptatif et distribué qui utilise les métadonnées du service de suivi et d'indexation des tuiles pour accéder et combiner facilement les données entre les magasins de données au moment où la requête est émise. Cela en fait une expérience qui trouve un écho auprès des clients, car elle réduit la plupart des complexités de Rube Goldberg en une abstraction de base de données simple et familière.
Les requêtes sont exécutées par un parc de travailleurs dédiés, le nombre de travailleurs recrutés pour exécuter une requête donnée étant déterminé par la complexité de la requête et la taille des données. Les performances des requêtes complexes sur de grands ensembles de données sont obtenues grâce à un parallélisme massif, à la fois sur le parc d'exécution des requêtes et sur les flottes de stockage du système. La capacité d'analyser rapidement et efficacement d'énormes quantités de données est l'un des principaux atouts de Timestream for Live Analytics. Une seule requête portant sur des téraoctets, voire des pétaoctets de données, peut nécessiter l'exécution simultanée de milliers de machines.
Architecture cellulaire
Pour garantir que Timestream for Live Analytics puisse offrir une évolutivité pratiquement infinie à vos applications, tout en garantissant une disponibilité de 99,99 %, le système est également conçu selon une architecture cellulaire. Plutôt que de dimensionner le système dans son ensemble, Timestream for Live Analytics se segmente en plusieurs petites copies de lui-même, appelées cellules. Cela permet de tester les cellules à grande échelle et d'éviter qu'un problème systémique dans une cellule n'affecte l'activité des autres cellules d'une région donnée. Bien que Timestream for Live Analytics soit conçu pour prendre en charge plusieurs cellules par région, considérez le scénario fictif suivant, dans lequel il y a deux cellules dans une région.
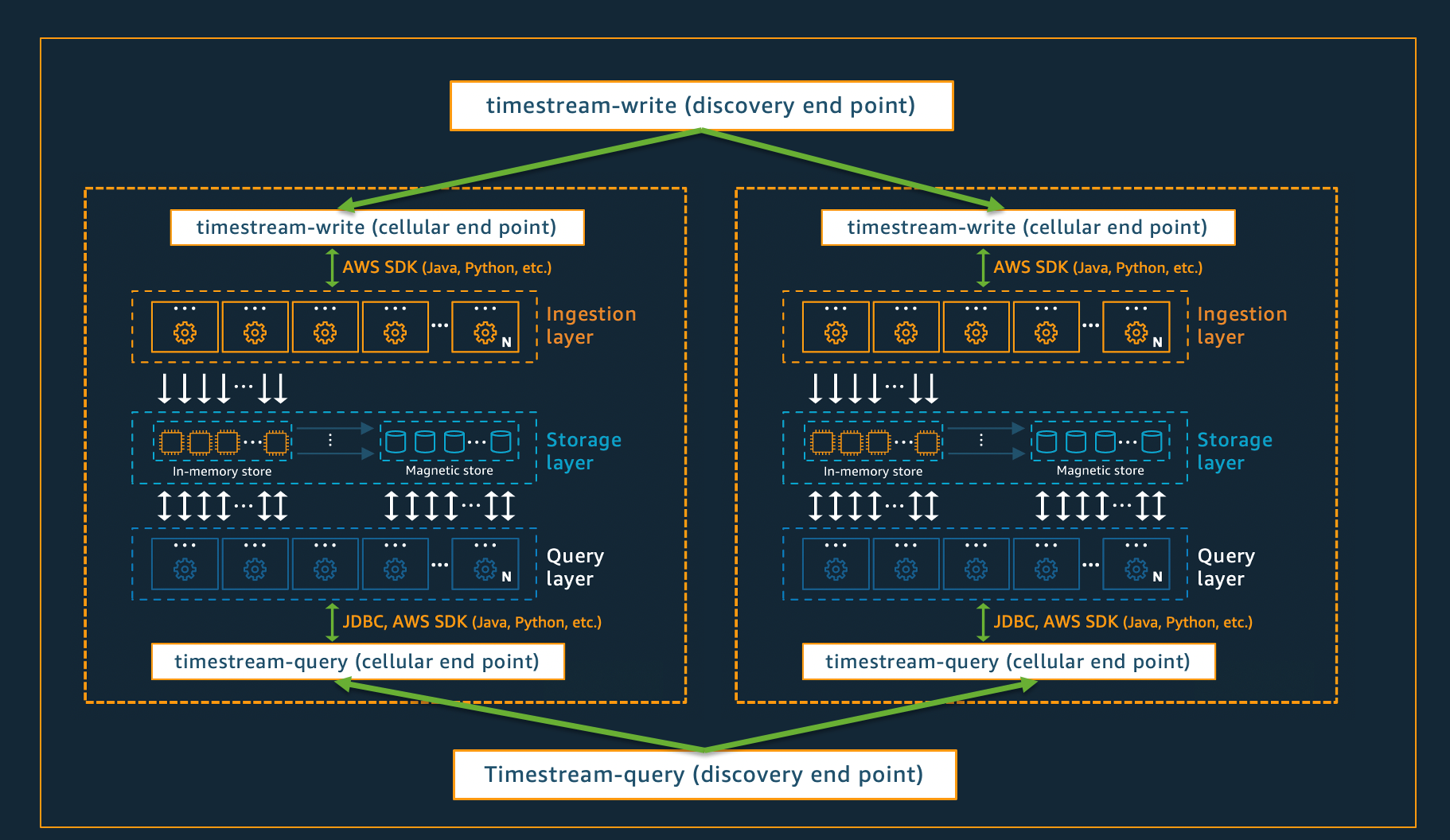
Dans le scénario décrit ci-dessus, les demandes d'ingestion de données et de requête sont d'abord traitées par le point de terminaison de découverte pour l'ingestion de données et les requêtes, respectivement. Le point de terminaison de découverte identifie ensuite la cellule contenant les données du client et dirige la demande vers le point de terminaison d'ingestion ou de requête approprié pour cette cellule. Lorsque vous utilisez le SDKs, ces tâches de gestion des terminaux sont gérées de manière transparente pour vous.
Note
Lorsque vous utilisez des points de terminaison VPC avec Timestream for Live Analytics ou que vous accédez directement aux opérations de l'API REST pour Timestream for Live Analytics, vous devez interagir directement avec les points de terminaison cellulaires. Pour savoir comment procéder, consultez les sections VPC Endpoints pour savoir comment configurer les points de terminaison VPC, et Endpoint Discovery Pattern pour les instructions sur l'invocation directe des opérations de l'API REST.
