Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Transcriptions alternatives
Lors de la Amazon Transcribe transcription audio, il crée différentes versions de la même transcription et attribue un score de confiance à chaque version. Dans une transcription classique, vous n’obtenez que la version présentant le score de confiance le plus élevé.
Si vous activez les transcriptions alternatives, Amazon Transcribe renvoie les autres versions de votre relevé de notes dont le niveau de confiance est inférieur. Vous pouvez choisir de renvoyer jusqu’à 10 transcriptions alternatives. Si vous spécifiez un nombre d'alternatives supérieur à ce qui est Amazon Transcribe identifié, seul le nombre réel d'alternatives est renvoyé.
Toutes les alternatives se trouvent dans le même fichier de sortie de transcription et sont présentées au niveau du segment. Les segments sont définis par des pauses naturelles dans le discours, notamment un changement de locuteur ou une pause dans l’audio.
Les transcriptions alternatives ne sont disponibles que pour les transcriptions par lots.
Votre sortie de transcription est structurée comme suit : Les ellipses (...) dans les exemples de code indiquent où le contenu a été supprimé pour des raisons de concision.
Une transcription finale complète pour un segment donné.
"results": { "language_code": "en-US", "transcripts": [ { "transcript": "The amazon is the largest rainforest on the planet." } ],Un score de confiance pour chaque mot de la section
transcriptprécédente."items": [ { "start_time": "1.15", "end_time": "1.35", "alternatives": [ { "confidence": "1.0", "content": "The" } ], "type": "pronunciation" }, { "start_time": "1.35", "end_time": "2.05", "alternatives": [ { "confidence": "1.0", "content": "amazon" } ], "type": "pronunciation" },-
Vos transcriptions alternatives se trouvent dans la partie
segmentsde votre sortie de transcription. Les alternatives pour chaque segment sont classées par score de confiance décroissant."segments": [ { "start_time": "1.04", "end_time": "5.065", "alternatives": [ {..."transcript": "The amazon is the largest rain forest on the planet.", "items": [ { "start_time": "1.15", "confidence": "1.0", "end_time": "1.35", "type": "pronunciation", "content": "The" },...{ "start_time": "3.06", "confidence": "0.0037", "end_time": "3.38", "type": "pronunciation", "content": "rain" }, { "start_time": "3.38", "confidence": "0.0037", "end_time": "3.96", "type": "pronunciation", "content": "forest" }, -
Un statut à la fin de votre sortie de transcription.
"status": "COMPLETED" }
Demande de transcriptions alternatives
Vous pouvez demander des transcriptions alternatives en utilisant le AWS Management ConsoleAWS CLI, ou AWS SDKs; voir les exemples suivants :
-
Connectez-vous à la AWS Management Console
. -
Dans le volet de navigation, choisissez Tâches de transcription, puis sélectionnez Créer une tâche (en haut à droite). La page Spécifier les détails de la tâche s’ouvre.
-
Renseignez les champs que vous souhaitez inclure sur la page Spécifier les détails de la tâche, puis sélectionnez Suivant. Vous accédez alors à la page Configure job - optional.
Sélectionnez Alternative results et indiquez le nombre maximal de résultats de transcription alternatifs que vous souhaitez inclure dans votre transcription.
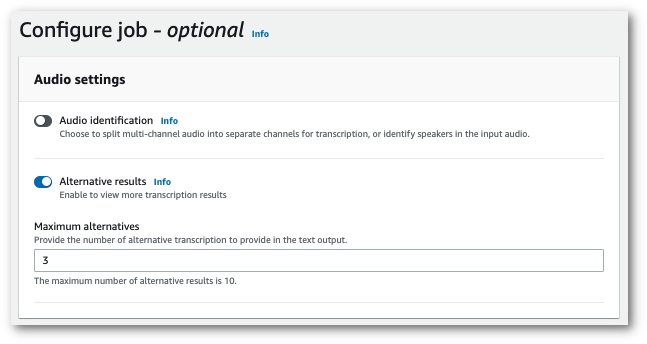
-
Sélectionnez Create job pour exécuter votre tâche de transcription.
Cet exemple utilise la start-transcription-jobShowAlternatives paramètre. Pour plus d’informations, consultez StartTranscriptionJob et ShowAlternatives.
Notez que si vous incluez ShowAlternatives=true dans votre demande, vous devez également inclure MaxAlternatives.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --settings ShowAlternatives=true,MaxAlternatives=4
Voici un autre exemple d'utilisation de la start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://filepath/my-first-alt-transcription-job.json
Le fichier my-first-alt-transcription-job.json contient le corps de requête suivant.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "Settings": { "ShowAlternatives": true, "MaxAlternatives":4} }
L'exemple suivant utilise le AWS SDK for Python (Boto3) pour demander des transcriptions alternatives en utilisant l'ShowAlternativesargument de la méthode start_transcription_jobStartTranscriptionJob et ShowAlternatives.
Pour des exemples supplémentaires utilisant le AWS SDKs, notamment des exemples spécifiques aux fonctionnalités, des scénarios et des exemples multiservices, reportez-vous au chapitre. Exemples de code pour Amazon Transcribe à l'aide de AWS SDKs
Notez que si vous incluez 'ShowAlternatives':True dans votre demande, vous devez également inclure MaxAlternatives.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', Settings = { 'ShowAlternatives':True, 'MaxAlternatives':4} ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
