Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation d’un filtre de glossaire personnalisé
Une fois votre filtre de vocabulaire personnalisé créé, vous pouvez l’inclure dans vos demandes de transcription. Reportez-vous aux sections suivantes pour des exemples.
La langue du filtre de vocabulaire personnalisé que vous incluez dans votre demande doit correspondre au code de langue que vous spécifiez pour votre fichier multimédia. Si vous utilisez l’identification de langue et que vous spécifiez plusieurs options de langue, vous pouvez inclure un filtre de vocabulaire personnalisé par langue spécifiée. Si les langues de vos filtres de vocabulaire personnalisé ne correspondent pas à la langue identifiée dans votre fichier audio, vos filtres ne sont pas appliqués à votre transcription et il n’y a ni avertissement ni erreur.
Utilisation d’un filtre de vocabulaire personnalisé dans une transcription par lots
Pour utiliser un filtre de vocabulaire personnalisé avec une transcription par lots, consultez les exemples suivants :
-
Connectez-vous à la AWS Management Console
. -
Dans le volet de navigation, choisissez Tâches de transcription, puis sélectionnez Créer une tâche (en haut à droite). La page Spécifier les détails de la tâche s’ouvre.
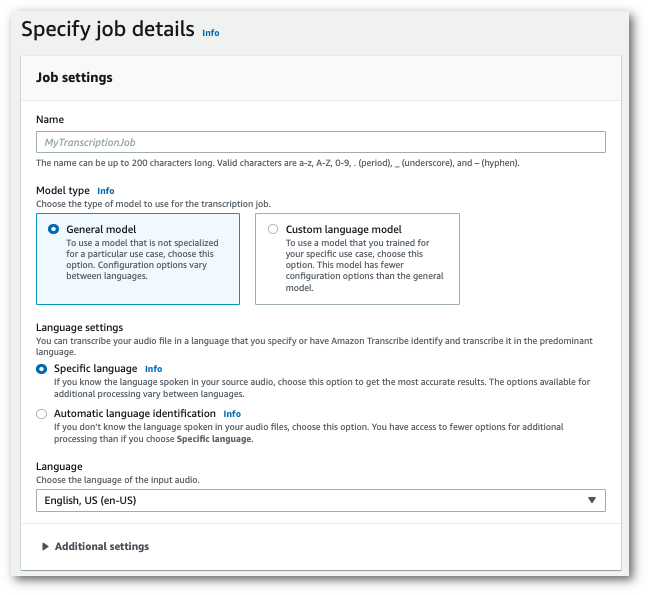
Donnez un nom à votre tâche et spécifiez votre média d’entrée. Incluez éventuellement d’autres champs, puis choisissez Suivant.
-
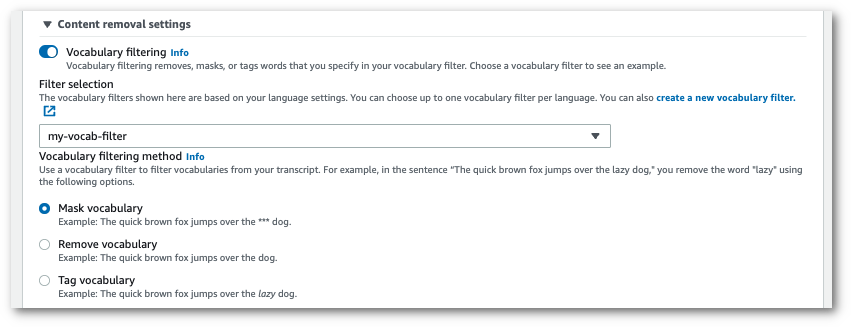
Sur la page Configurer la tâche, dans le volet Suppression de contenu, activez Filtrage du vocabulaire.
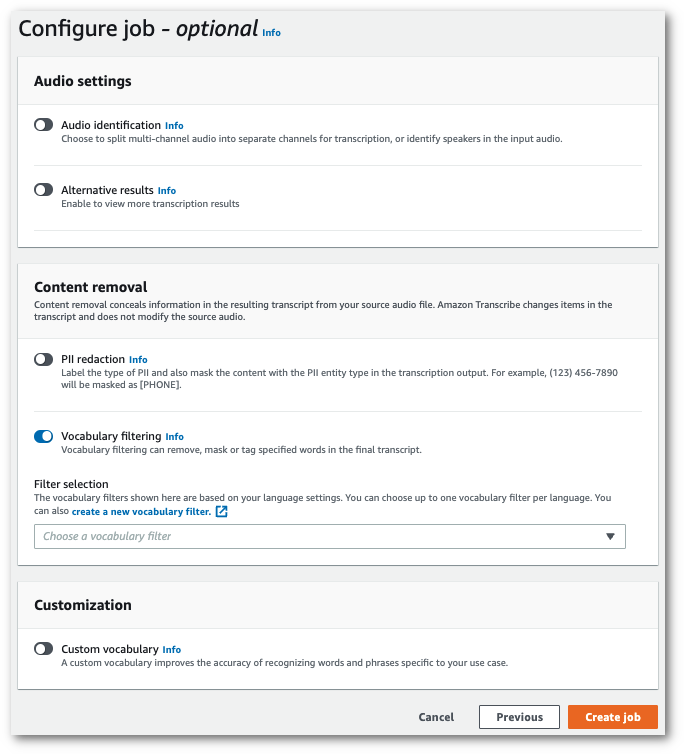
-
Sélectionnez votre filtre de vocabulaire personnalisé dans le menu déroulant et spécifiez la méthode de filtrage.
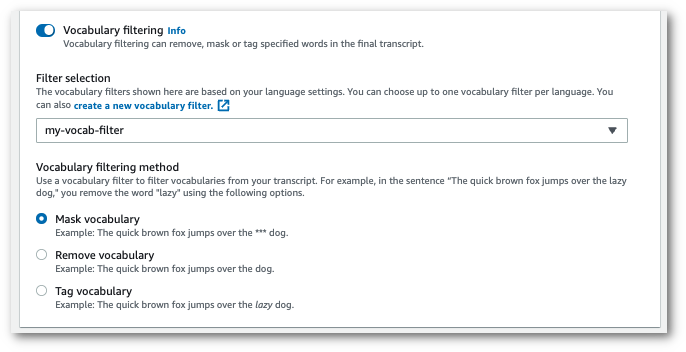
-
Sélectionnez Créer une tâche pour exécuter votre tâche de transcription.
Cet exemple utilise la start-transcription-jobSettings paramètre avec les VocabularyFilterMethod sous-paramètres VocabularyFilterName et. Pour plus d’informations, consultez StartTranscriptionJob et Settings.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --settings VocabularyFilterName=my-first-vocabulary-filter,VocabularyFilterMethod=mask
Voici un autre exemple d'utilisation de la start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-vocabulary-filter-job.json
Le fichier my-first-vocabulary-filter-job.json contient le corps de requête suivant.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "Settings": { "VocabularyFilterName": "my-first-vocabulary-filter", "VocabularyFilterMethod": "mask" } }
Cet exemple utilise le AWS SDK for Python (Boto3) pour inclure un filtre de vocabulaire personnalisé utilisant l'Settingsargument de la méthode start_transcription_jobStartTranscriptionJob et Settings.
Pour des exemples supplémentaires utilisant le AWS SDKs, notamment des exemples spécifiques aux fonctionnalités, des scénarios et des exemples multiservices, reportez-vous au chapitre. Exemples de code pour Amazon Transcribe à l'aide de AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', Settings = { 'VocabularyFilterName': 'my-first-vocabulary-filter', 'VocabularyFilterMethod': 'mask' } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Utilisation d’un filtre de vocabulaire personnalisé dans une transcription en streaming
Pour utiliser un filtre de vocabulaire personnalisé avec une transcription en streaming, consultez les exemples suivants :
-
Connectez-vous au AWS Management Console
. -
Dans le panneau de navigation, choisissez Transcription en temps réel. Faites défiler jusqu’à Paramètres de suppression de contenu et développez ce champ s’il est réduit.
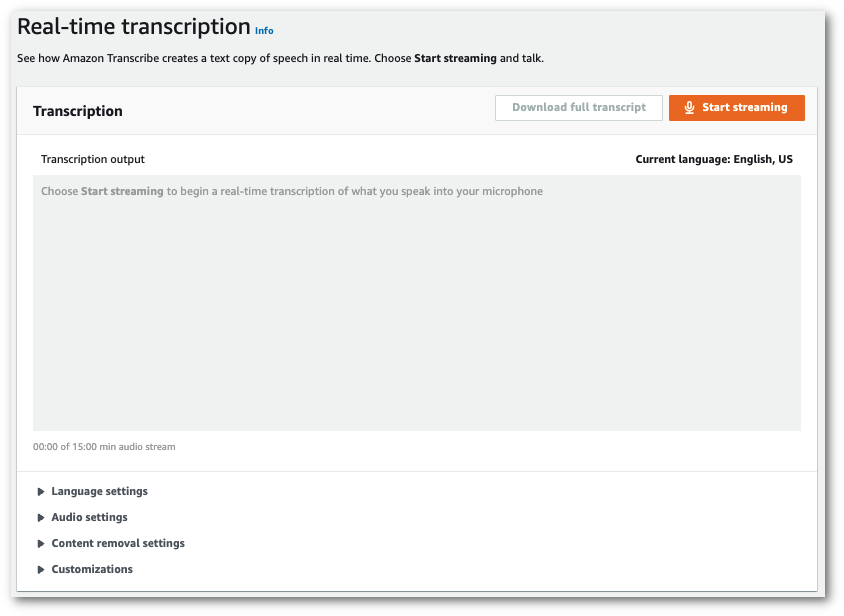
-
Activez Filtrage du vocabulaire. Sélectionnez un filtre de vocabulaire personnalisé dans le menu déroulant et spécifiez la méthode de filtrage.
Incluez les autres paramètres que vous souhaitez appliquer à votre flux.
-
Vous êtes prêt à transcrire votre flux. Sélectionnez Démarrer le streaming et commencez à parler. Pour mettre fin à votre dictée, sélectionnez Arrêter le streaming.
Cet exemple crée une requête HTTP/2 qui inclut votre filtre de vocabulaire personnalisé ainsi qu’une méthode de filtrage. Pour plus d'informations sur l'utilisation du streaming HTTP/2 avec Amazon Transcribe, consultezConfiguration d’un flux HTTP/2. Pour plus de détails sur les paramètres et les en-têtes spécifiques à Amazon Transcribe, voir StartStreamTranscription.
POST /stream-transcription HTTP/2 host: transcribestreaming.us-west-2.amazonaws.com X-Amz-Target: com.amazonaws.transcribe.Transcribe.StartStreamTranscriptionContent-Type: application/vnd.amazon.eventstream X-Amz-Content-Sha256:stringX-Amz-Date:20220208T235959Z Authorization: AWS4-HMAC-SHA256 Credential=access-key/20220208/us-west-2/transcribe/aws4_request, SignedHeaders=content-type;host;x-amz-content-sha256;x-amz-date;x-amz-target;x-amz-security-token, Signature=stringx-amzn-transcribe-language-code:en-USx-amzn-transcribe-media-encoding:flacx-amzn-transcribe-sample-rate:16000x-amzn-transcribe-vocabulary-filter-name:my-first-vocabulary-filterx-amzn-transcribe-vocabulary-filter-method:masktransfer-encoding: chunked
Les définitions des paramètres se trouvent dans la référence d'API ; les paramètres communs à toutes les opérations d' AWS API sont répertoriés dans la section Paramètres communs.
Cet exemple crée une URL présignée qui applique votre filtre de vocabulaire personnalisé à un WebSocket flux. Les sauts de ligne ont été ajoutés pour faciliter la lecture. Pour plus d'informations sur l'utilisation WebSocket des flux avec Amazon Transcribe, consultezConfiguration d'un WebSocket stream. Pour plus de détails sur les paramètres, consultez la section StartStreamTranscription.
GET wss://transcribestreaming.us-west-2.amazonaws.com:8443/stream-transcription-websocket? &X-Amz-Algorithm=AWS4-HMAC-SHA256 &X-Amz-Credential=AKIAIOSFODNN7EXAMPLE%2F20220208%2Fus-west-2%2Ftranscribe%2Faws4_request &X-Amz-Date=20220208T235959Z &X-Amz-Expires=300&X-Amz-Security-Token=security-token&X-Amz-Signature=string&X-Amz-SignedHeaders=content-type%3Bhost%3Bx-amz-date &language-code=en-US&media-encoding=flac&sample-rate=16000&vocabulary-filter-name=my-first-vocabulary-filter&vocabulary-filter-method=mask
Les définitions des paramètres se trouvent dans la référence d'API ; les paramètres communs à toutes les opérations d' AWS API sont répertoriés dans la section Paramètres communs.
