Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Modèle de responsabilité partagée pour la résilience
La résilience est une responsabilité partagée entre AWS et vous. Il est important que vous compreniez comment la reprise après sinistre (DR) et la disponibilité, qui font partie de la résilience, fonctionnent dans le cadre de ce modèle partagé.
Responsabilité AWS : résilience du cloud
AWS est responsable de la résilience de l’infrastructure qui fait fonctionner tous les services proposés dans le AWS Cloud. Cette infrastructure est composée du matériel, des logiciels, du réseau et des installations exécutant les services AWS Cloud. AWS déploie des efforts commercialement raisonnables pour rendre ces services AWS Cloud disponibles, en veillant à ce que la disponibilité des services respecte ou dépasse les contrats de niveau de service (SLA) AWS
L’infrastructure cloud mondiale AWS
Responsabilité des clients : résilience dans le cloud
Votre responsabilité est déterminée par les services AWS Cloud que vous choisissez. Cela détermine la quantité de travail de configuration que vous devez effectuer dans le cadre de vos responsabilités en matière de résilience. Par exemple, un service tel que Amazon Elastic Compute Cloud (Amazon EC2) exige du client qu’il effectue toutes les tâches de configuration et de gestion de la résilience nécessaires. Les clients qui déploient des instances Amazon EC2 sont chargés de déployer des instances Amazon EC2 sur plusieurs sites (tels que les zones de disponibilité AWS), de mettre en œuvre l’autoréparation à l’aide de services tels que Auto Scaling et d’appliquer les bonnes pratiques en matière d’architecture de charge de travail résiliente pour les applications installées sur les instances. Dans le cas des services gérés, comme Amazon S3 et Amazon DynamoDB, AWS exploite la couche infrastructure, le système d’exploitation et les plateformes, et les clients accèdent aux points de terminaison pour stocker et récupérer les données. Vous êtes responsable de la gestion de la résilience de vos données, y compris des stratégies de sauvegarde, de gestion des versions et de réplication.
Le déploiement de votre charge de travail dans plusieurs zones de disponibilité d’une Région AWS fait partie d’une stratégie de haute disponibilité conçue pour protéger les charges de travail en isolant les problèmes dans une zone de disponibilité donnée. Cette stratégie utilise la redondance des autres zones de disponibilité pour continuer à répondre aux requêtes. Une architecture Multi-AZ s’inscrit également dans une stratégie DR conçue pour mieux isoler et protéger les charges de travail contre des problèmes tels que les pannes de courant, la foudre, les tornades, les tremblements de terre, etc. Les stratégies de DR peuvent également faire appel à de multiples Régions AWS. Par exemple, dans une configuration active/passive, le service de la charge de travail passe de sa région active à sa région DR si la région active ne peut plus répondre aux requêtes.
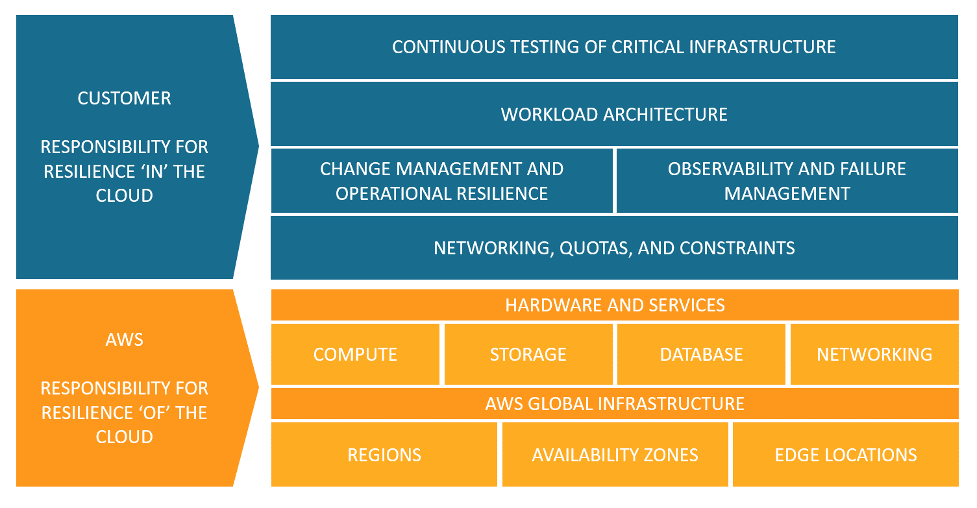
Responsabilité en matière de résilience dans et hors du cloud pour les clients et AWS.
Vous pouvez utiliser les services AWS pour atteindre vos objectifs de résilience. En tant que client, vous êtes responsable de la gestion des aspects suivants de votre système pour atteindre la résilience dans le cloud. Pour plus de détails sur chaque service en particulier, consultez la documentation AWS.
Réseaux, quotas et contraintes
-
Les bonnes pratiques pour ce domaine du modèle de responsabilité partagée sont décrites en détail dans la section Fondations.
-
Planifiez votre architecture avec une marge de manœuvre suffisante et comprenez les quotas de service et les contraintes des services que vous incluez, en fonction des augmentations de charge attendues, le cas échéant.
-
Concevez la topologie de votre réseau pour qu’elle soit hautement disponible, redondante et évolutive.
Gestion des modifications et résilience opérationnelle
-
La gestion des modifications inclut la manière d’introduire et de gérer les modifications dans votre environnement. La mise en œuvre du changement nécessite de créer et de maintenir à jour des runbooks ainsi que des stratégies de déploiement pour votre application et votre infrastructure.
-
Une stratégie résiliente de surveillance des ressources de charge de travail prend en compte tous les composants, y compris les indicateurs techniques et commerciaux, les notifications, l’automatisation et l’analyse.
-
Les charges de travail dans le cloud doivent s’adapter à l’évolution de la demande en réaction à des déficiences ou à des fluctuations d’utilisation.
Observabilité et gestion des pannes
-
L’observation des défaillances par le biais de la surveillance est nécessaire pour automatiser la réparation afin que vos charges de travail puissent résister aux défaillances des composants.
-
La gestion des défaillances nécessite de sauvegarder les données, d’appliquer les bonnes pratiques pour permettre à votre charge de travail de résister aux défaillances des composants et de planifier la reprise après sinistre.
Architecture de charge de travail
-
L’architecture de votre charge de travail inclut la manière dont vous concevez des services autour de domaines commerciaux, appliquez la SOA et concevez des systèmes distribués pour éviter les défaillances, et intégrez des fonctionnalités telles que la limitation, les nouvelles tentatives, la gestion des files d’attente, les délais d’attente et les leviers d’urgence.
-
Appuyez-vous sur des solutions AWS
éprouvées, Amazon Builders’ Library et des modèles sans serveur pour vous aligner sur les bonnes pratiques et accélérer les mises en œuvre. -
Utilisez l’amélioration continue pour décomposer votre système en services distribués afin d’évoluer et d’innover plus rapidement. Utilisez les conseils relatifs aux microservices AWS
et les options de services gérés pour simplifier et accélérer votre capacité à introduire le changement et à innover.
Test continu des infrastructures critiques
-
Pour tester la fiabilité, il faut effectuer des tests au niveau des fonctionnalités, des performances et du chaos, ainsi qu’adopter l’analyse des incidents et les pratiques des jours de jeu afin de développer une expertise en matière de résolution de problèmes mal compris.
-
Pour les applications tout cloud et hybrides, le fait de savoir comment votre application se comporte lorsque des problèmes surviennent ou que des composants tombent en panne permet une reprise rapide et fiable après une panne.
-
Créez et documentez des expériences reproductibles pour comprendre comment votre système se comporte lorsque les objets ne fonctionnent pas comme prévu. Ces tests prouveront l’efficacité de votre résilience globale et fourniront une boucle de rétroaction pour vos procédures opérationnelles avant de vous confronter à des scénarios de panne réels.
