Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Défaillances grises
Les défaillances grises sont définies par la caractéristique deobservabilité différentielle
Observabilité différentielle
Les charges de travail que vous gérez sont généralement dépendantes. Par exemple, il peut s'agir desAWSles services cloud que vous utilisez pour créer votre charge de travail ou un fournisseur d'identité (IdP) tiers que vous utilisez pour la fédération. Ces dépendances implémentent presque toujours leur propre observabilité, en enregistrant des indicateurs concernant les erreurs, la disponibilité et la latence, entre autres éléments générés par l'utilisation par leurs clients. Lorsqu'un seuil est dépassé pour l'une de ces métriques, la dépendance prend généralement des mesures pour le corriger.
Ces dépendances ont généralement de multiples consommateurs de leurs services. Les consommateurs mettent également en œuvre leur propre observabilité et enregistrent des métriques et des journaux concernant leurs interactions avec leurs dépendances, en enregistrant des éléments tels que le niveau de latence des lectures sur disque, le nombre de demandes d'API ayant échoué ou la durée d'une requête de base de données.
Ces interactions et mesures sont décrites dans un modèle abstrait illustré dans la figure suivante.
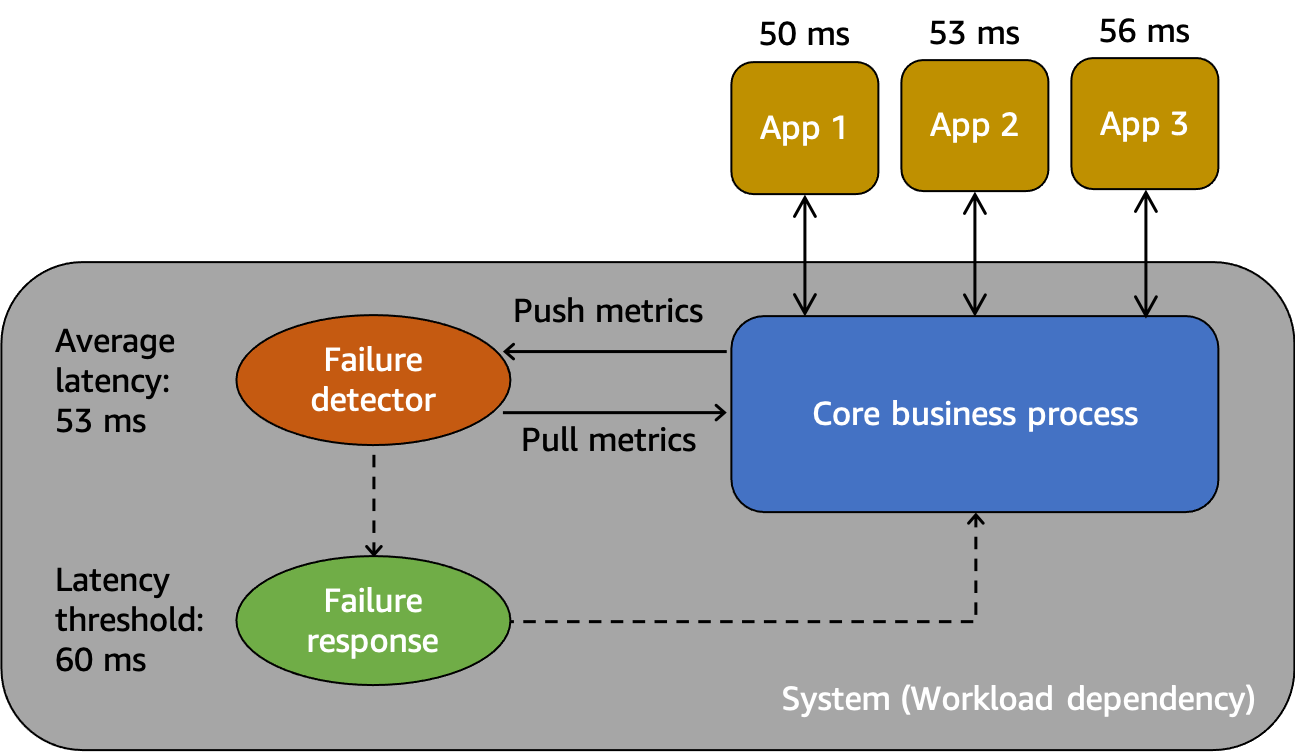
Un modèle abstrait pour comprendre les défaillances grises
Tout d'abord, nous avonssystème, qui dépend de l'App 1, de l'App 2 et de l'App 3 des consommateurs dans ce scénario. Le système dispose d'un détecteur de défaillance qui examine les métriques créées à partir du processus métier de base. Il dispose également d'un mécanisme de réponse aux défaillances pour atténuer ou corriger les problèmes observés par le détecteur de défaillance. Le système constate une latence moyenne globale de 53 ms et a défini un seuil pour invoquer le mécanisme de réponse aux pannes lorsque la latence moyenne dépasse 60 ms. Les applications 1, 2 et 3 font également leurs propres observations sur leur interaction avec le système, enregistrant une latence moyenne de 50 ms, 53 ms et 56 ms respectivement.
L'observabilité différentielle est la situation dans laquelle l'un des utilisateurs du système détecte que le système est défectueux, mais que le système de surveillance lui-même ne détecte pas le problème ou que l'impact ne dépasse pas le seuil d'alarme. Imaginons que l'App 1 commence à connaître une latence moyenne de 70 ms au lieu de 50 ms. Les applications 2 et 3 ne constatent aucun changement dans leurs latences moyennes. Cela augmente la latence moyenne du système sous-jacent à 59,66 ms, mais cela ne dépasse pas le seuil de latence nécessaire à l'activation du mécanisme de réponse aux pannes. Cependant, l'App 1 constate une augmentation de 40 % de la latence. Cela peut avoir un impact sur sa disponibilité en dépassant le délai d'expiration du client configuré pour l'App 1, ou cela peut avoir des répercussions en cascade sur une chaîne d'interactions plus longue. Du point de vue de l'application 1, le système sous-jacent dont elle dépend n'est pas sain, mais du point de vue du système lui-même ainsi que des applications 2 et 3, le système est sain. La figure suivante résume ces différentes perspectives.
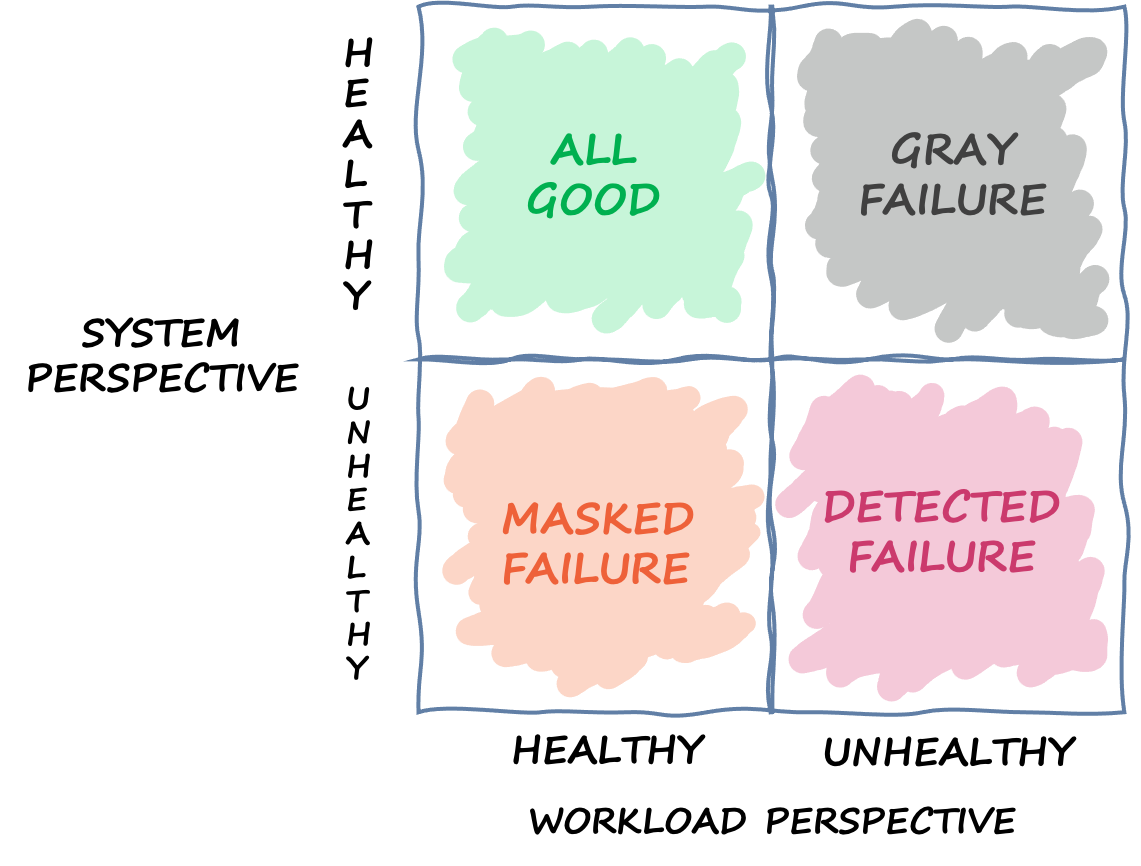
Un quadrant définissant les différents états dans lesquels un système peut se trouver en fonction de différentes perspectives
La défaillance peut également traverser ce quadrant. Un événement peut commencer sous la forme d'un échec gris, puis devenir un échec détecté, puis passer à un échec masqué, puis peut-être revenir à un échec gris. Il n'existe pas de cycle défini et il existe presque toujours un risque de récurrence d'une défaillance jusqu'à ce que sa cause première soit traitée.
La conclusion que nous en tirons est que les charges de travail ne peuvent pas toujours compter sur le système sous-jacent pour détecter et atténuer les défaillances. Quelle que soit la complexité et la résilience du système sous-jacent, il est toujours possible qu'une défaillance passe inaperçue ou reste en dessous du seuil de réaction. Les utilisateurs de ce système, comme App 1, doivent être équipés pour détecter rapidement et atténuer l'impact d'une panne grise. Cela nécessite de mettre en place des mécanismes d'observabilité et de rétablissement pour ces situations.
Exemple d'échec de Gray
Les pannes grises peuvent avoir un impact sur les systèmes multi-AZ dansAWS. Prenons l'exemple d'une flotte deAmazon EC2
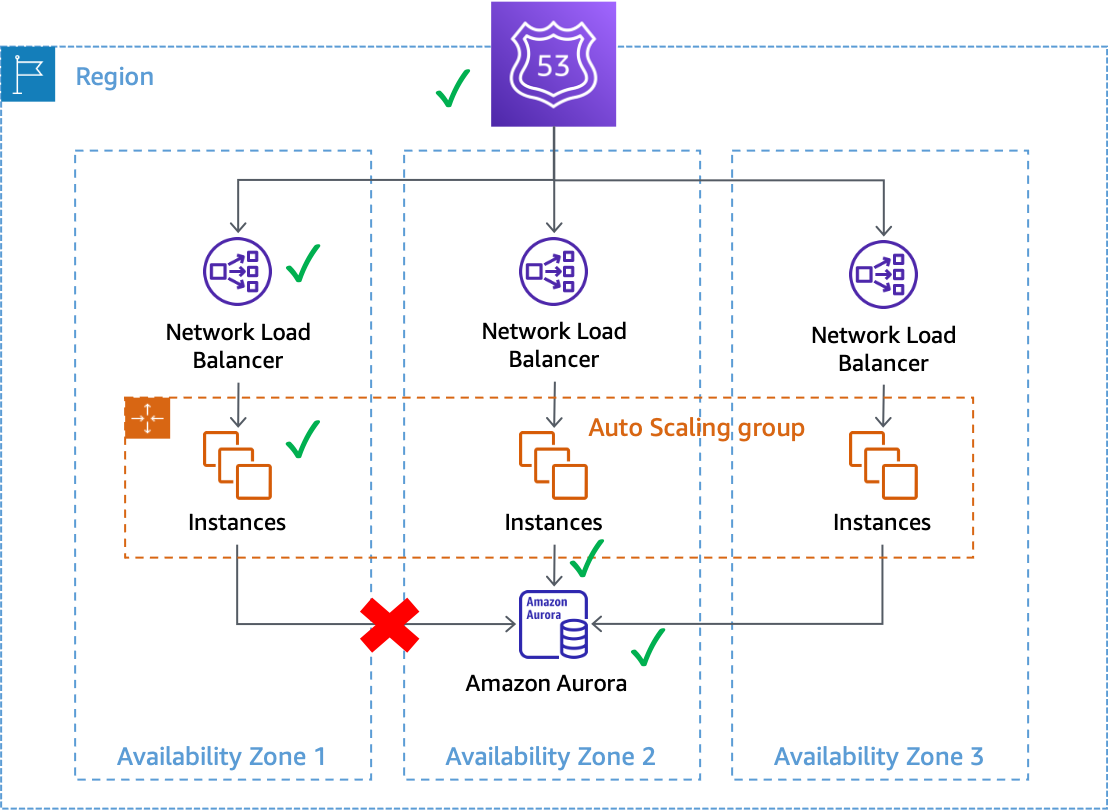
Une panne grise qui a un impact sur les connexions aux bases de données depuis les instances de la zone de disponibilité 1
Dans cet exemple, Amazon EC2 considère que les instances de la zone de disponibilité 1 sont saines car elles continuent à être transmisesvérifications de l'état du système et de l'instance. Amazon EC2 Auto Scaling ne détecte pas non plus d'impact direct sur aucune zone de disponibilité et continue decapacité de lancement dans les zones de disponibilité configurées. Le Network Load Balancer (NLB) considère également que les instances qui le sous-tendent sont saines, tout comme les contrôles de santé de Route 53 effectués sur le point de terminaison NLB. De même, Amazon Relational Database Service (Amazon RDS) considère que le cluster de bases de données est sain et ne le considère pasdéclencher un basculement automatique. Nous avons de nombreux services différents qui considèrent tous que leurs services et leurs ressources sont sains, mais la charge de travail détecte une défaillance qui a une incidence sur leur disponibilité. Il s'agit d'un échec flagrant.
Réagir aux pannes grises
Lorsque vous rencontrez une défaillance grise dans votreAWSenvironnement, vous avez généralement trois options disponibles :
-
Ne faites rien et attendez que la déficience prenne fin.
-
Si la déficience est limitée à une seule zone de disponibilité, évacuez cette zone de disponibilité.
-
Basculement vers un autreRégion AWSet profitez des avantages deAWSIsolement régional pour atténuer l'impact.
De nombreuxAWSles clients sont d'accord avec la première option pour la majorité de leurs charges de travail. Ils acceptent d'avoir une extension éventuelleObjectif de temps de restauration (RTO)avec le compromis qu'ils n'ont pas eu à créer de solutions d'observabilité ou de résilience supplémentaires. D'autres clients choisissent de mettre en œuvre la troisième option,Reprise après sinistre multirégionale
Tout d'abord, la création et l'exploitation d'une architecture multirégionale peuvent s'avérer difficiles, complexes et potentiellement coûteuses. Les architectures multirégionales nécessitent un examen attentif des architecturesStratégie DRvous sélectionnez. Il n'est peut-être pas rentable de mettre en œuvre une solution de reprise après sinistre active-active multirégionale uniquement pour gérer les déficiences zonales, tandis qu'une stratégie de sauvegarde et de restauration peut ne pas répondre à vos exigences de résilience. En outre, les basculements multirégionaux doivent être pratiqués en continu en production afin que vous soyez sûr qu'ils fonctionneront en cas de besoin. Tout cela nécessite beaucoup de temps et de ressources dédiés à la création, à l'exploitation et aux tests.
Ensuite, la réplication des données entreRégions AWSen utilisantAWSles services actuels sont tous effectués de manière asynchrone. La réplication asynchrone peut entraîner une perte de données. Cela signifie que lors d'un basculement régional, il existe un risque de perte de données et d'incohérence. Votre tolérance à la quantité de perte de données est définie comme votreObjectif de point de restauration (RPO). Les clients, pour lesquels une forte cohérence des données est requise, doivent créer des systèmes de réconciliation pour résoudre ces problèmes de cohérence lorsque la région principale est à nouveau disponible. Ils doivent également créer leurs propres systèmes de réplication synchrone ou à double écriture, ce qui peut avoir un impact significatif sur la latence des réponses, les coûts et la complexité. Ils font également de la région secondaire une dépendance absolue pour chaque transaction, ce qui peut potentiellement réduire la disponibilité de l'ensemble du système.
Enfin, pour de nombreuses charges de travail utilisant une approche active/en veille, le temps nécessaire pour effectuer le basculement vers une autre région est non nul. Il se peut que votre portefeuille de charges de travail doive être transféré dans la région principale dans un ordre spécifique, qu'il soit nécessaire de vider les connexions ou d'arrêter des processus spécifiques. Ensuite, il peut être nécessaire de rétablir les services dans un ordre spécifique. Les nouvelles ressources peuvent également devoir être provisionnées ou nécessiter du temps pour passer les contrôles de santé requis avant d'être mises en service. Ce processus de basculement peut être vécu comme une période d'indisponibilité totale. C'est ce qui préoccupe les RTO.
Au sein d'une région, de nombreuxAWSles services offrent une persistance des données très cohérente. Les déploiements multi-AZ d'Amazon RDS utilisentréplication synchrone. Service de stockage simple Amazon
L'évacuation d'une zone de disponibilité peut avoir un RTO inférieur à celui d'une stratégie multirégionale, car votre infrastructure et vos ressources sont déjà provisionnées entre les zones de disponibilité. Au lieu de devoir ordonner avec soin la mise hors service et la restauration des services, ou de vider les connexions, les architectures multi-AZ peuvent continuer à fonctionner de manière statique lorsqu'une zone de disponibilité est altérée. Au lieu d'une période d'indisponibilité complète qui peut survenir lors d'un basculement régional, lors d'une évacuation d'une zone de disponibilité, de nombreux systèmes peuvent ne subir qu'une légère dégradation, car le travail est transféré vers les zones de disponibilité restantes. Si le système a été conçu pour êtrestatiquement stable
Il est possible que la dégradation d'une seule zone de disponibilité ait un impact sur une ou plusieursAWS Services régionauxen plus de votre charge de travail. Si vous constatez un impact régional, vous devez traiter l'événement comme une perturbation du service régional, bien que la source de cet impact provienne d'une seule zone de disponibilité. L'évacuation d'une zone de disponibilité ne résoudra pas ce type de problème. Utilisez les plans d'intervention que vous avez mis en place pour répondre à une panne du service régional lorsque cela se produit.
Le reste de ce document se concentre sur la deuxième option, à savoir l'évacuation de la zone de disponibilité, afin de réduire les RTO et RPO en cas de pannes grises d'une seule AZ. Ces modèles peuvent contribuer à améliorer la valeur et l'efficacité des architectures multi-AZ et, pour la plupart des classes de charges de travail, peuvent réduire la nécessité de créer des architectures multirégions pour gérer ce type d'événements.
