Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Gestion distribuée des données
Dans les applications traditionnelles, tous les composants partagent souvent une seule base de données. En revanche, chaque composant d'une application basée sur des microservices conserve ses propres données, ce qui favorise l'indépendance et la décentralisation. Cette approche, connue sous le nom de gestion distribuée des données, pose de nouveaux défis.
L'un de ces défis réside dans le compromis entre cohérence et performance dans les systèmes distribués. Il est souvent plus pratique d'accepter de légers retards dans les mises à jour des données (cohérence éventuelle) que d'exiger des mises à jour instantanées (cohérence immédiate).
Parfois, les opérations commerciales nécessitent plusieurs microservices pour fonctionner ensemble. Si une partie échoue, vous devrez peut-être annuler certaines tâches terminées. Le modèle Saga permet de gérer cela en coordonnant une série d'actions compensatoires.
Pour aider les microservices à rester synchronisés, un magasin de données centralisé peut être utilisé. Ce magasin, géré à l'aide d'outils tels que AWS Lambda AWS Step Functions,, et Amazon EventBridge, peut aider à nettoyer et à dédupliquer les données.
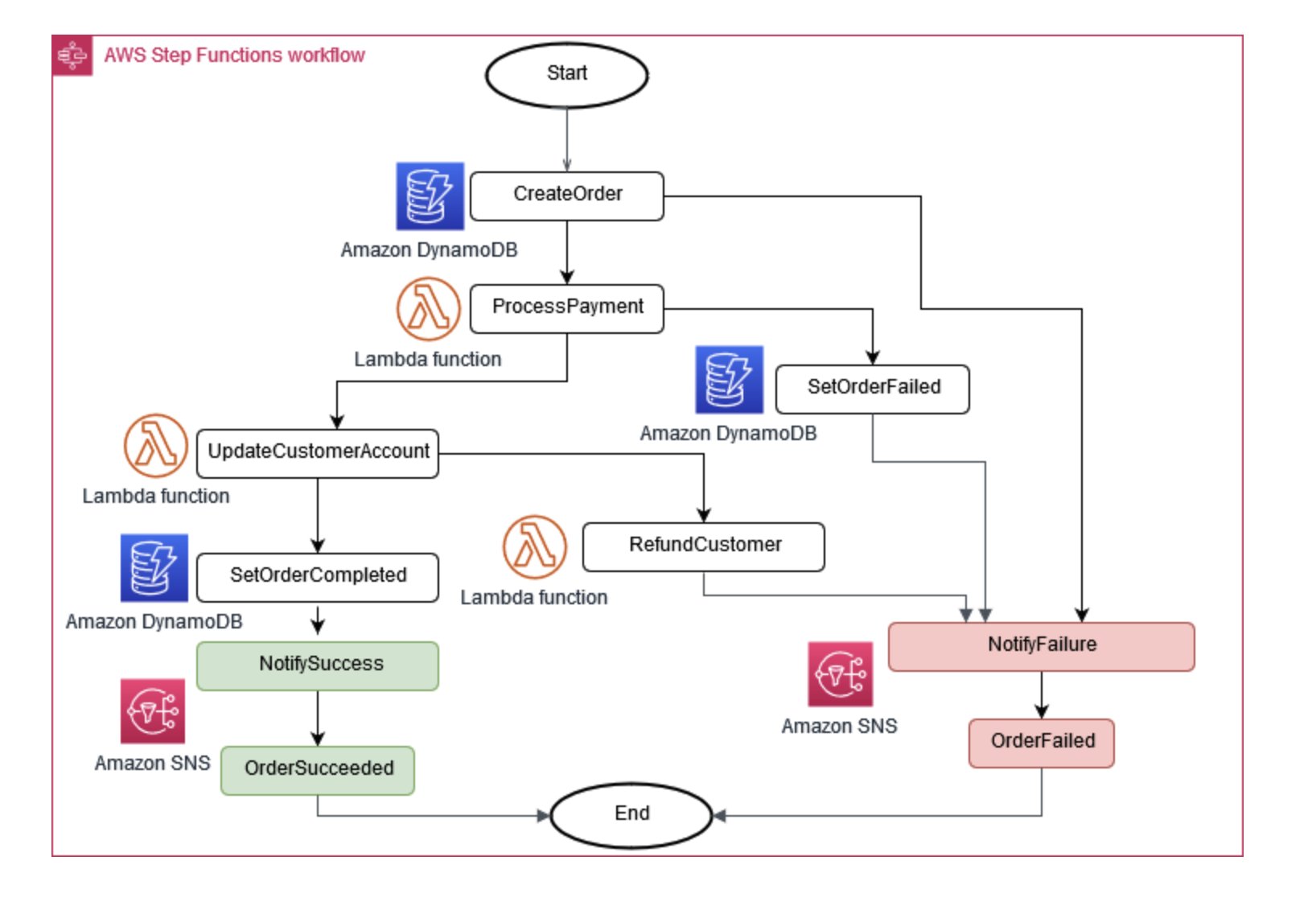
Figure 6 : Coordinateur de l'exécution de Saga
L'approvisionnement en événements est une approche courante pour gérer les changements dans les microservices. Chaque modification apportée à l'application est enregistrée en tant qu'événement, ce qui crée une chronologie de l'état du système. Cette approche permet non seulement le débogage et l'audit, mais permet également aux différentes parties d'une application de réagir aux mêmes événements.
L'approvisionnement en événements fonctionne souvent hand-in-hand avec le modèle Command Query Responsibility Segrégation (CQRS), qui sépare la modification des données de l'interrogation de données en différents modules pour améliorer les performances et la sécurité.
Oui AWS, vous pouvez implémenter ces modèles à l'aide d'une combinaison de services. Comme le montre la Figure 7, Amazon Kinesis Data Streams peut servir de magasin d'événements central, tandis qu'Amazon S3 fournit un stockage durable pour tous les enregistrements d'événements. AWS Lambda, Amazon DynamoDB et API Amazon Gateway travaillent ensemble pour gérer et traiter ces événements.
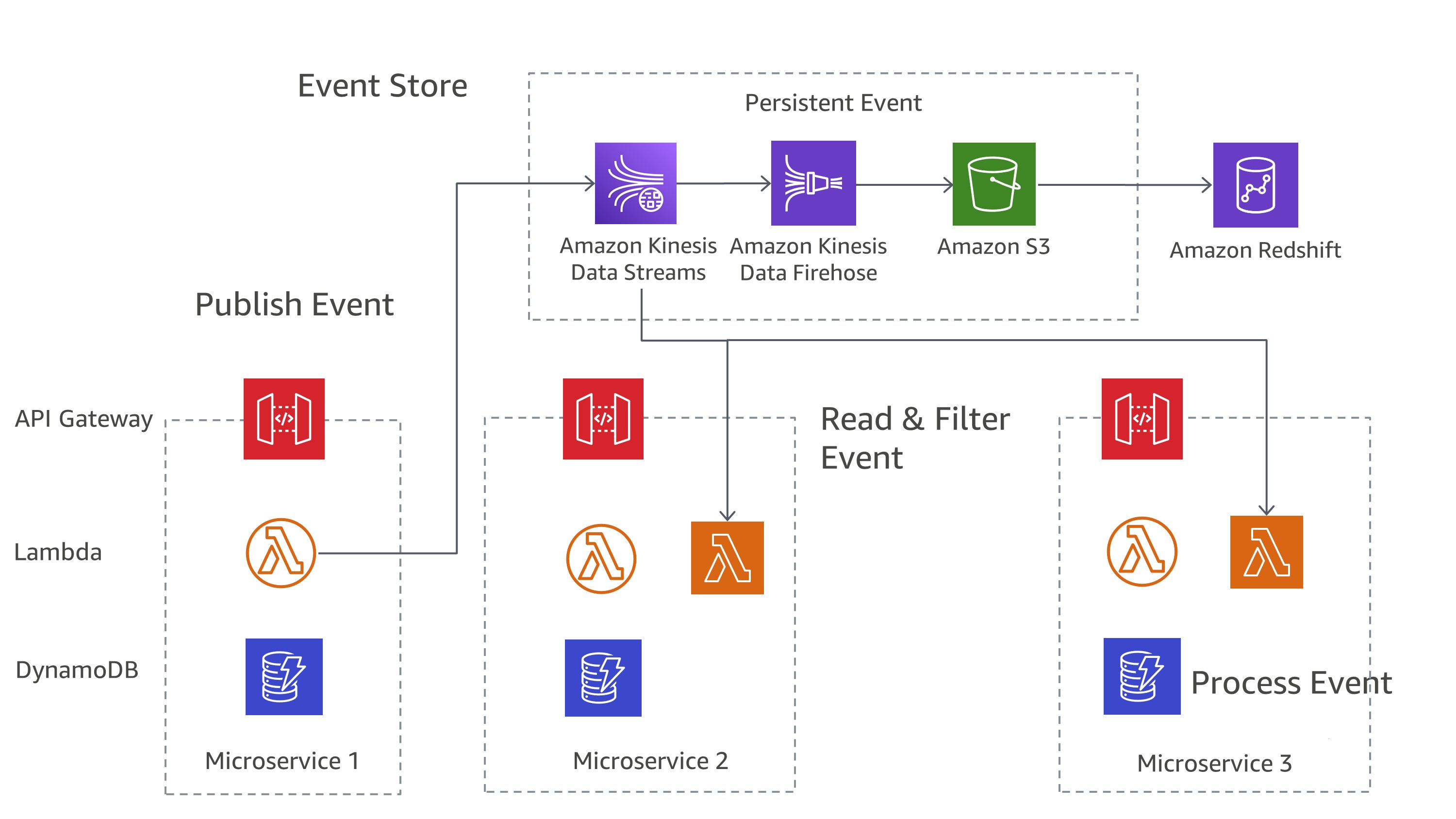
Figure 7 : Modèle d'approvisionnement en événements sur AWS
N'oubliez pas que dans les systèmes distribués, les événements peuvent être transmis plusieurs fois en raison de nouvelles tentatives. Il est donc important de concevoir vos applications de manière à gérer ce problème.
