Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utiliser l'API X-Ray
Si le SDK X-Ray ne prend pas en charge votre langage de programmation, vous pouvez utiliser directement les API X-Ray ou le AWS Command Line Interface (AWS CLI) pour appeler les commandes de l'API X-Ray. Suivez les instructions suivantes pour choisir la manière dont vous interagissez avec l'API :
-
Utilisez le AWS CLI pour une syntaxe plus simple à l'aide de commandes préformatées ou d'options dans votre requête.
-
Utilisez directement l'API X-Ray pour une flexibilité et une personnalisation maximales des demandes que vous envoyez à X-Ray.
Si vous utilisez directement l'API X-Ray à la place du AWS CLI, vous devez paramétrer votre demande dans le bon format de données et vous devrez peut-être également configurer l'authentification et la gestion des erreurs.
Le schéma suivant indique comment choisir le mode d'interaction avec l'API X-Ray :
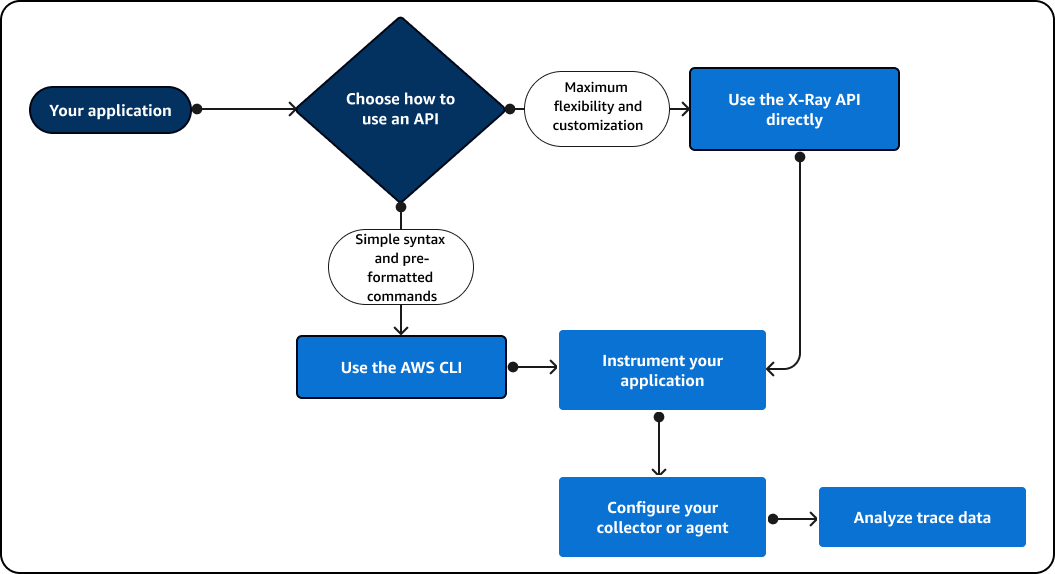
Utilisez l'API X-Ray pour envoyer les données de suivi directement à X-Ray. L'API X-Ray prend en charge toutes les fonctions disponibles dans le SDK X-Ray, y compris les actions courantes suivantes :
-
PutTraceSegments— Télécharge les documents segmentés sur X-Ray.
-
BatchGetTraces— Récupère une liste de traces dans une liste d'identifiants de trace. Chaque trace récupérée est une collection de documents segmentés provenant d'une seule demande.
-
GetTraceSummaries— Récupère les identifiants et les annotations pour les traces. Vous pouvez spécifier a
FilterExpressionpour récupérer un sous-ensemble de résumés de traces. -
GetTraceGraph— Récupère un graphique de service pour un ID de trace spécifique.
-
GetServiceGraph— Récupère un document JSON formaté qui décrit les services qui traitent les demandes entrantes et appellent les demandes en aval.
Vous pouvez également utiliser le AWS Command Line Interface (AWS CLI) dans le code de votre application pour interagir par programmation avec X-Ray. Il AWS CLI prend en charge toutes les fonctions disponibles dans le SDK X-Ray, y compris celles pour les autres Services AWS. Les fonctions suivantes sont des versions des opérations d'API répertoriées précédemment dans un format plus simple :
-
put-trace-segments
— Télécharge les documents segmentés sur X-Ray. -
batch-get-traces
— Récupère une liste de traces dans une liste d'identifiants de trace. Chaque trace récupérée est une collection de documents segmentés provenant d'une seule demande. -
get-trace-summaries
— Récupère les identifiants et les annotations pour les traces. Vous pouvez spécifier a FilterExpressionpour récupérer un sous-ensemble de résumés de traces. -
get-trace-graph
— Récupère un graphique de service pour un ID de trace spécifique. -
get-service-graph
— Récupère un document JSONformaté qui décrit les services qui traitent les demandes entrantes et appellent les demandes en aval.
Pour commencer, vous devez installer le AWS CLIpour votre système d'exploitation. AWS supports Linux macOS et systèmes Windows d'exploitation. Pour plus d'informations sur la liste des commandes X-Ray, consultez le guide AWS CLI Command Reference pour X-Ray
Découvrez l'API X-Ray
L'API X-Ray permet d'accéder à toutes les fonctionnalités de X-Ray via le AWS AWS Command Line Interface SDK ou directement via HTTPS. Le X-Ray API Reference documente les paramètres d'entrée pour chaque action d'API, ainsi que les champs et les types de données qu'ils renvoient.
Vous pouvez utiliser le AWS SDK pour développer des programmes utilisant l'API X-Ray. La console X-Ray et le daemon X-Ray utilisent tous deux le AWS SDK pour communiquer avec X-Ray. Le AWS SDK de chaque langage contient un document de référence pour les classes et les méthodes qui correspondent aux actions et aux types d'API X-Ray.
AWS Références du SDK
-
Java — AWS SDK for Java
-
JavaScript – AWS SDK for JavaScript
-
.NET – AWS SDK for .NET
-
Ruby – AWS SDK for Ruby
-
Go — AWS SDK pour
Go -
PHP – AWS SDK for PHP
-
Python : AWS SDK for Python (Boto)
AWS Command Line Interface Il s'agit d'un outil de ligne de commande qui utilise le SDK pour Python pour appeler des AWS API. Lorsque vous apprenez à utiliser une AWS API pour la première fois, elle AWS CLI permet d'explorer facilement les paramètres disponibles et de visualiser le résultat du service au format JSON ou sous forme de texte.
Consultez la référence des AWS CLI commandes pour plus de détails sur les aws xray sous-commandes.
La AWS CLI vous permet d'accéder directement au service X-Ray et d'utiliser les mêmes API que celles utilisées par la console X-Ray pour récupérer le graphe du service et les données de trace brutes. L'exemple d'application inclut des scripts qui montrent comment utiliser ces API avec la AWS CLI.
Prérequis
Ce didacticiel utilise l'exemple d'application Scorekeep et inclut des scripts pour générer des données de suivi et une cartographie des services. Suivez les instructions du didacticiel d'exemple d'application pour lancer l'application.
Ce didacticiel utilise le AWS CLI pour montrer l'utilisation de base de l'API X-Ray. La AWS CLI, disponible pour Windows, Linux et OS-X, fournit un accès en ligne de commande aux API publiques pour tous. Services AWS
Note
Vous devez vérifier que votre application AWS CLI est configurée dans la même région que celle dans laquelle votre exemple d'application a été créé.
Les scripts inclus pour tester l'exemple d'application utilisent cURL pour envoyer le trafic vers l'API et jq pour analyser la sortie. Vous pouvez télécharger l' exécutable àjq partir de stedolan.github.iocurl à partir de https://curl.haxx.se/download.html
Génération de données de suivi
L'application web continue de générer du trafic vers l'API à intervalles réguliers de quelques secondes pendant que le jeu est en cours, mais elle génère uniquement un type de demande. Utilisez le script test-api.sh pour exécuter des scénarios de bout en bout et générer plusieurs autres données de suivi pendant que vous testez l'API.
Pour utiliser le script test-api.sh
Ouvrez la console Elastic Beanstalk
. Accédez à la console de gestion de votre environnement.
-
Copiez l'URL de l'environnement à partir de l'en-tête de page.
-
Ouvrez
bin/test-api.shet remplacez la valeur pour l'API par l'URL de votre environnement.#!/bin/bash API=scorekeep.9hbtbm23t2.us-west-2.elasticbeanstalk.com/api -
Exécutez le script pour générer du trafic vers l'API.
~/debugger-tutorial$./bin/test-api.shCreating users, session, game, configuring game, playing game, ending game, game complete. {"id":"MTBP8BAS","session":"HUF6IT64","name":"tic-tac-toe-test","users":["QFF3HBGM","KL6JR98D"],"rules":"102","startTime":1476314241,"endTime":1476314245,"states":["JQVLEOM2","D67QLPIC","VF9BM9NC","OEAA6GK9","2A705O73","1U2LFTLJ","HUKIDD70","BAN1C8FI","G3UDJTUF","AB70HVEV"],"moves":["BS8F8LQ","4MTTSPKP","463OETES","SVEBCL3N","N7CQ1GHP","O84ONEPD","EG4BPROQ","V4BLIDJ3","9RL3NPMV"]}
Utiliser l'API X-Ray
La AWS CLI fournit des commandes pour toutes les actions d'API proposées par X-Ray, y compris GetServiceGraphet GetTraceSummaries. Consultez le document Référence d'API AWS X-Ray pour plus d'informations sur toutes les actions prises en charge et les types de données utilisés.
Exemple bin/service-graph.sh
EPOCH=$(date +%s)
aws xray get-service-graph --start-time $(($EPOCH-600)) --end-time $EPOCHLe script récupère un graphique de services pour les 10 dernières minutes.
~/eb-java-scorekeep$ ./bin/service-graph.sh | less
{
"StartTime": 1479068648.0,
"Services": [
{
"StartTime": 1479068648.0,
"ReferenceId": 0,
"State": "unknown",
"EndTime": 1479068651.0,
"Type": "client",
"Edges": [
{
"StartTime": 1479068648.0,
"ReferenceId": 1,
"SummaryStatistics": {
"ErrorStatistics": {
"ThrottleCount": 0,
"TotalCount": 0,
"OtherCount": 0
},
"FaultStatistics": {
"TotalCount": 0,
"OtherCount": 0
},
"TotalCount": 2,
"OkCount": 2,
"TotalResponseTime": 0.054000139236450195
},
"EndTime": 1479068651.0,
"Aliases": []
}
]
},
{
"StartTime": 1479068648.0,
"Names": [
"scorekeep.elasticbeanstalk.com"
],
"ReferenceId": 1,
"State": "active",
"EndTime": 1479068651.0,
"Root": true,
"Name": "scorekeep.elasticbeanstalk.com",
...Exemple bin/trace-urls.sh
EPOCH=$(date +%s)
aws xray get-trace-summaries --start-time $(($EPOCH-120)) --end-time $(($EPOCH-60)) --query 'TraceSummaries[*].Http.HttpURL'Le script récupère les URL des suivis générés il y a une et deux minutes.
~/eb-java-scorekeep$ ./bin/trace-urls.sh
[
"http://scorekeep.elasticbeanstalk.com/api/game/6Q0UE1DG/5FGLM9U3/endtime/1479069438",
"http://scorekeep.elasticbeanstalk.com/api/session/KH4341QH",
"http://scorekeep.elasticbeanstalk.com/api/game/GLQBJ3K5/153AHDIA",
"http://scorekeep.elasticbeanstalk.com/api/game/VPDL672J/G2V41HM6/endtime/1479069466"
]Exemple bin/full-traces.sh
EPOCH=$(date +%s)
TRACEIDS=$(aws xray get-trace-summaries --start-time $(($EPOCH-120)) --end-time $(($EPOCH-60)) --query 'TraceSummaries[*].Id' --output text)
aws xray batch-get-traces --trace-ids $TRACEIDS --query 'Traces[*]'Le script récupère les suivis entiers générés il y a une et deux minutes.
~/eb-java-scorekeep$ ./bin/full-traces.sh | less
[
{
"Segments": [
{
"Id": "3f212bc237bafd5d",
"Document": "{\"id\":\"3f212bc237bafd5d\",\"name\":\"DynamoDB\",\"trace_id\":\"1-5828d9f2-a90669393f4343211bc1cf75\",\"start_time\":1.479072242459E9,\"end_time\":1.479072242477E9,\"parent_id\":\"72a08dcf87991ca9\",\"http\":{\"response\":{\"content_length\":60,\"status\":200}},\"inferred\":true,\"aws\":{\"consistent_read\":false,\"table_name\":\"scorekeep-session-xray\",\"operation\":\"GetItem\",\"request_id\":\"QAKE0S8DD0LJM245KAOPMA746BVV4KQNSO5AEMVJF66Q9ASUAAJG\",\"resource_names\":[\"scorekeep-session-xray\"]},\"origin\":\"AWS::DynamoDB::Table\"}"
},
{
"Id": "309e355f1148347f",
"Document": "{\"id\":\"309e355f1148347f\",\"name\":\"DynamoDB\",\"trace_id\":\"1-5828d9f2-a90669393f4343211bc1cf75\",\"start_time\":1.479072242477E9,\"end_time\":1.479072242494E9,\"parent_id\":\"37f14ef837f00022\",\"http\":{\"response\":{\"content_length\":606,\"status\":200}},\"inferred\":true,\"aws\":{\"table_name\":\"scorekeep-game-xray\",\"operation\":\"UpdateItem\",\"request_id\":\"388GEROC4PCA6D59ED3CTI5EEJVV4KQNSO5AEMVJF66Q9ASUAAJG\",\"resource_names\":[\"scorekeep-game-xray\"]},\"origin\":\"AWS::DynamoDB::Table\"}"
}
],
"Id": "1-5828d9f2-a90669393f4343211bc1cf75",
"Duration": 0.05099987983703613
}
...
Nettoyage
Mettez fin à votre environnement Elastic Beanstalk pour arrêter les instances Amazon EC2, les tables DynamoDB et les autres ressources.
Pour arrêter votre environnement Elastic Beanstalk
Ouvrez la console Elastic Beanstalk
. Accédez à la console de gestion de votre environnement.
-
Choisissez Actions.
-
Choisissez Terminate Environment (Terminer l'environnement).
-
Sélectionnez Résilier.
Les données de suivi sont automatiquement supprimées de X-Ray au bout de 30 jours.
Vous pouvez envoyer des données de suivi à X-Ray sous forme de documents segmentés. Un document de segment est une chaîne au format JSON contenant des informations sur les tâches effectuées par votre application pour répondre à une demande. Votre application peut enregistrer des données sur les tâches qu'elle effectue elle-même dans les segments, ou sur celles qui font appel à des ressources et services en aval dans les sous-segments.
Les segments enregistrent les informations sur les tâches effectuées par votre application. Un segment enregistre, au minimum, le temps consacré à une tâche, un nom et deux ID. L'ID de suivi permet de suivre la demande lors de son cheminement entre les différents services. L'ID de segment permet de suivre les tâches effectuées par un service en particulier pour répondre à la demande.
Exemple Segment terminé minimal
{
"name" : "Scorekeep",
"id" : "70de5b6f19ff9a0a",
"start_time" : 1.478293361271E9,
"trace_id" : "1-581cf771-a006649127e371903a2de979",
"end_time" : 1.478293361449E9
}Lors de la réception d'une demande, vous pouvez envoyer un segment en cours comme espace réservé en attendant la réponse.
Exemple Segment en cours
{
"name" : "Scorekeep",
"id" : "70de5b6f19ff9a0b",
"start_time" : 1.478293361271E9,
"trace_id" : "1-581cf771-a006649127e371903a2de979",
“in_progress”: true
}Vous pouvez envoyer des segments à X-Ray directement PutTraceSegments, avec ou via le daemon X-Ray.
La plupart des applications appellent d'autres services ou accèdent à des ressources à l'aide du AWS SDK. Enregistrez les informations relatives aux appels en aval dans des sous-segments. X-Ray utilise des sous-segments pour identifier les services en aval qui n'envoient pas de segments et créer des entrées pour eux sur le graphique des services.
Un sous-segment peut être intégré dans un document de segment entier, ou envoyé séparément. Envoyez des sous-segments séparément pour suivre de manière asynchrone les appels en aval pour les demandes de longue durée ou pour éviter de dépasser la taille maximale du document de segment (64 kB).
Exemple Sous-segment
Un sous-segment possède un type de subsegment et un parent_id qui identifie le segment parent.
{
"name" : "www2.example.com",
"id" : "70de5b6f19ff9a0c",
"start_time" : 1.478293361271E9,
"trace_id" : "1-581cf771-a006649127e371903a2de979"
“end_time” : 1.478293361449E9,
“type” : “subsegment”,
“parent_id” : “70de5b6f19ff9a0b”
}Pour plus d'informations sur les champs et les valeurs que vous pouvez inclure dans les segments et les sous-segments, consultez Documents relatifs au segment X-Ray.
Pour envoyer des données à X-Ray, vous devez générer un identifiant de trace unique pour chaque demande.
Format d'identification X-Ray Trace
Un X-Ray trace_id est composé de trois chiffres séparés par des tirets. Par exemple, 1-58406520-a006649127e371903a2de979. Cela consiste notamment à :
-
Le numéro de version, qui est
1. -
L'heure de la demande d'origine sous Unix Epoch Time en utilisant 8 chiffres hexadécimaux.
Par exemple, le 1er décembre 2016 à 10 h 00 PST est exprimé en
1480615200secondes ou58406520en chiffres hexadécimaux. -
Identifiant 96 bits unique au monde pour la trace en 24 chiffres hexadécimaux.
Note
X-Ray prend désormais en charge les identifiants de trace créés à OpenTelemetry l'aide de tout autre framework conforme à la spécification W3C Trace Context4efaaf4d1e8720b39541901950019ee5 doit être formaté comme 1-4efaaf4d-1e8720b39541901950019ee5 lorsqu'il est envoyé à X-Ray. Les identifiants de trace X-Ray incluent l'horodatage de la demande d'origine à l'époque Unix, mais cela n'est pas obligatoire lors de l'envoi des identifiants de trace du W3C au format X-Ray.
Vous pouvez écrire un script pour générer des identifiants de trace X-Ray à des fins de test. Voici deux exemples :
Python
import time
import os
import binascii
START_TIME = time.time()
HEX=hex(int(START_TIME))[2:]
TRACE_ID="1-{}-{}".format(HEX, binascii.hexlify(os.urandom(12)).decode('utf-8'))Bash
START_TIME=$(date +%s)
HEX_TIME=$(printf '%x\n' $START_TIME)
GUID=$(dd if=/dev/random bs=12 count=1 2>/dev/null | od -An -tx1 | tr -d ' \t\n')
TRACE_ID="1-$HEX_TIME-$GUID"Consultez l'exemple d'application Scorekeep pour découvrir les scripts qui créent des identifiants de trace et envoient des segments au daemon X-Ray.
-
Python –
xray_start.py -
Bash —
xray_start.sh
Vous pouvez charger des documents relatifs aux segments avec l'API PutTraceSegments. L'API possède un seul paramètre, TraceSegmentDocuments, qui accepte une liste de documents de segment au format JSON.
Avec l'AWS CLI, utilisez la aws xray put-trace-segments commande pour envoyer les documents de segment directement à X-Ray.
$ DOC='{"trace_id": "1-5960082b-ab52431b496add878434aa25", "id": "6226467e3f845502", "start_time": 1498082657.37518, "end_time": 1498082695.4042, "name": "test.elasticbeanstalk.com"}'
$ aws xray put-trace-segments --trace-segment-documents "$DOC"
{
"UnprocessedTraceSegments": []
}Note
Windows Command Processor et Windows PowerShell ont des exigences différentes en matière de guillemets et d'échappements aux guillemets dans les chaînes JSON. Pour plus d'informations, consultez Indication des chaînes entre guillemets dans le Guide de l'utilisateur de l' AWS CLI .
La sortie répertorie tous les segments dont le traitement a échoué. Par exemple, si la date qui figure dans l'ID de suivi remonte à trop loin, une erreur similaire à la suivante s'affiche :
{
"UnprocessedTraceSegments": [
{
"ErrorCode": "InvalidTraceId",
"Message": "Invalid segment. ErrorCode: InvalidTraceId",
"Id": "6226467e3f845502"
}
]
}Vous pouvez indiquer plusieurs documents de segment à la suite, en les séparant par des espaces.
$ aws xray put-trace-segments --trace-segment-documents "$DOC1" "$DOC2"Au lieu d'envoyer des documents de segment à l'API X-Ray, vous pouvez envoyer des segments et des sous-segments au daemon X-Ray, qui les mettra en mémoire tampon et les téléchargera par lots vers l'API X-Ray. Le SDK X-Ray envoie des documents segmentés au daemon pour éviter de passer AWS des appels directs.
Note
Consultez Exécution du daemon X-Ray en local pour obtenir des instructions sur l'exécution du démon.
Envoyez le segment au format JSON sur le port UDP 2000, en ajoutant en préfixe l'en-tête du démon, {"format": "json", "version": 1}\n
{"format": "json", "version": 1}\n{"trace_id": "1-5759e988-bd862e3fe1be46a994272793", "id": "defdfd9912dc5a56", "start_time": 1461096053.37518, "end_time": 1461096053.4042, "name": "test.elasticbeanstalk.com"}Sous Linux, vous pouvez envoyer des documents de segment au démon depuis un terminal Bash. Enregistrez l'en-tête et le document de segment comme fichier texte et placez-les dans /dev/udp avec cat.
$ cat segment.txt > /dev/udp/127.0.0.1/2000Exemple segment.txt
{"format": "json", "version": 1}
{"trace_id": "1-594aed87-ad72e26896b3f9d3a27054bb", "id": "6226467e3f845502", "start_time": 1498082657.37518, "end_time": 1498082695.4042, "name": "test.elasticbeanstalk.com"}Consultez le journal du démon pour vérifier qu'il a envoyé le segment à X-Ray.
2017-07-07T01:57:24Z [Debug] processor: sending partial batch
2017-07-07T01:57:24Z [Debug] processor: segment batch size: 1. capacity: 50
2017-07-07T01:57:24Z [Info] Successfully sent batch of 1 segments (0.020 seconds)X-Ray traite les données de suivi que vous lui envoyez pour générer des traces complètes, des résumés de traces et des graphiques de service au format JSON. Vous pouvez récupérer les données générées directement depuis l'API à l'aide de la AWS CLI.
Vous pouvez utiliser l'API GetServiceGraph pour récupérer le graphique de services JSON. L'API nécessite une heure de début et de fin, que vous pouvez calculer à partir d'un terminal Linux avec la commande date.
$ date +%s
1499394617date +%s détermine une date en quelques secondes. Utilisez cette valeur comme une heure de fin et déduisez le temps de traitement pour obtenir une heure de début.
Exemple Script permettant de récupérer un graphique de services pour les 10 dernières minutes
EPOCH=$(date +%s) aws xray get-service-graph --start-time $(($EPOCH-600)) --end-time $EPOCH
L'exemple suivant montre un graphe de service avec 4 nœuds, dont un nœud client, une instance EC2, une table DynamoDB et une rubrique Amazon SNS.
Exemple GetServiceGraph sortie
{ "Services": [ { "ReferenceId": 0, "Name": "xray-sample.elasticbeanstalk.com", "Names": [ "xray-sample.elasticbeanstalk.com" ], "Type": "client", "State": "unknown", "StartTime": 1528317567.0, "EndTime": 1528317589.0, "Edges": [ { "ReferenceId": 2, "StartTime": 1528317567.0, "EndTime": 1528317589.0, "SummaryStatistics": { "OkCount": 3, "ErrorStatistics": { "ThrottleCount": 0, "OtherCount": 1, "TotalCount": 1 }, "FaultStatistics": { "OtherCount": 0, "TotalCount": 0 }, "TotalCount": 4, "TotalResponseTime": 0.273 }, "ResponseTimeHistogram": [ { "Value": 0.005, "Count": 1 }, { "Value": 0.015, "Count": 1 }, { "Value": 0.157, "Count": 1 }, { "Value": 0.096, "Count": 1 } ], "Aliases": [] } ] }, { "ReferenceId": 1, "Name": "awseb-e-dixzws4s9p-stack-StartupSignupsTable-4IMSMHAYX2BA", "Names": [ "awseb-e-dixzws4s9p-stack-StartupSignupsTable-4IMSMHAYX2BA" ], "Type": "AWS::DynamoDB::Table", "State": "unknown", "StartTime": 1528317583.0, "EndTime": 1528317589.0, "Edges": [], "SummaryStatistics": { "OkCount": 2, "ErrorStatistics": { "ThrottleCount": 0, "OtherCount": 0, "TotalCount": 0 }, "FaultStatistics": { "OtherCount": 0, "TotalCount": 0 }, "TotalCount": 2, "TotalResponseTime": 0.12 }, "DurationHistogram": [ { "Value": 0.076, "Count": 1 }, { "Value": 0.044, "Count": 1 } ], "ResponseTimeHistogram": [ { "Value": 0.076, "Count": 1 }, { "Value": 0.044, "Count": 1 } ] }, { "ReferenceId": 2, "Name": "xray-sample.elasticbeanstalk.com", "Names": [ "xray-sample.elasticbeanstalk.com" ], "Root": true, "Type": "AWS::EC2::Instance", "State": "active", "StartTime": 1528317567.0, "EndTime": 1528317589.0, "Edges": [ { "ReferenceId": 1, "StartTime": 1528317567.0, "EndTime": 1528317589.0, "SummaryStatistics": { "OkCount": 2, "ErrorStatistics": { "ThrottleCount": 0, "OtherCount": 0, "TotalCount": 0 }, "FaultStatistics": { "OtherCount": 0, "TotalCount": 0 }, "TotalCount": 2, "TotalResponseTime": 0.12 }, "ResponseTimeHistogram": [ { "Value": 0.076, "Count": 1 }, { "Value": 0.044, "Count": 1 } ], "Aliases": [] }, { "ReferenceId": 3, "StartTime": 1528317567.0, "EndTime": 1528317589.0, "SummaryStatistics": { "OkCount": 2, "ErrorStatistics": { "ThrottleCount": 0, "OtherCount": 0, "TotalCount": 0 }, "FaultStatistics": { "OtherCount": 0, "TotalCount": 0 }, "TotalCount": 2, "TotalResponseTime": 0.125 }, "ResponseTimeHistogram": [ { "Value": 0.049, "Count": 1 }, { "Value": 0.076, "Count": 1 } ], "Aliases": [] } ], "SummaryStatistics": { "OkCount": 3, "ErrorStatistics": { "ThrottleCount": 0, "OtherCount": 1, "TotalCount": 1 }, "FaultStatistics": { "OtherCount": 0, "TotalCount": 0 }, "TotalCount": 4, "TotalResponseTime": 0.273 }, "DurationHistogram": [ { "Value": 0.005, "Count": 1 }, { "Value": 0.015, "Count": 1 }, { "Value": 0.157, "Count": 1 }, { "Value": 0.096, "Count": 1 } ], "ResponseTimeHistogram": [ { "Value": 0.005, "Count": 1 }, { "Value": 0.015, "Count": 1 }, { "Value": 0.157, "Count": 1 }, { "Value": 0.096, "Count": 1 } ] }, { "ReferenceId": 3, "Name": "SNS", "Names": [ "SNS" ], "Type": "AWS::SNS", "State": "unknown", "StartTime": 1528317583.0, "EndTime": 1528317589.0, "Edges": [], "SummaryStatistics": { "OkCount": 2, "ErrorStatistics": { "ThrottleCount": 0, "OtherCount": 0, "TotalCount": 0 }, "FaultStatistics": { "OtherCount": 0, "TotalCount": 0 }, "TotalCount": 2, "TotalResponseTime": 0.125 }, "DurationHistogram": [ { "Value": 0.049, "Count": 1 }, { "Value": 0.076, "Count": 1 } ], "ResponseTimeHistogram": [ { "Value": 0.049, "Count": 1 }, { "Value": 0.076, "Count": 1 } ] } ] }
Pour appeler un graphique des services en fonction du contenu d'un groupe, incluez un élément groupName ou groupARN. L'exemple suivant illustre un appel de graphique des services à un groupe nommé Example1.
Exemple Script permettant de récupérer un graphique des services par nom pour le groupe Example1
aws xray get-service-graph --group-name "Example1"
Vous pouvez utiliser l'API GetTraceSummaries pour obtenir la liste des synthèses de suivi. Les synthèses de suivi incluent des informations que vous pouvez utiliser pour identifier les suivis que vous souhaitez télécharger entièrement, y compris les annotations, informations sur les demandes et les réponses, et identifiants.
Il y a deux indicateurs TimeRangeType disponibles lors de l'appel de aws xray
get-trace-summaries :
-
TraceId— La
GetTraceSummariesrecherche par défaut utilise l'heure de TraceID et renvoie les traces démarrées dans la plage calculée[start_time, end_time). Cette plage d'horodatages est calculée en fonction du codage de l'horodatage dans le TraceId, ou peut être définie manuellement. -
Durée de l'événement : pour rechercher les événements tels qu'ils se produisent au fil du temps, AWS X-Ray permet de rechercher des traces à l'aide des horodatages des événements. L'heure de l'événement renvoie les traces actives au cours de la plage
[start_time, end_time), quel que soit le moment où la trace a commencé.
Utilisez la commande aws xray get-trace-summaries pour obtenir la liste des synthèses de suivi. Les commandes suivantes permettent d'obtenir une liste de résumés de traces réalisés il y a 1 à 2 minutes en utilisant l' TraceId heure par défaut.
Exemple Script permettant d'obtenir des synthèses de suivi
EPOCH=$(date +%s) aws xray get-trace-summaries --start-time $(($EPOCH-120)) --end-time $(($EPOCH-60))
Exemple GetTraceSummaries sortie
{
"TraceSummaries": [
{
"HasError": false,
"Http": {
"HttpStatus": 200,
"ClientIp": "205.255.255.183",
"HttpURL": "http://scorekeep.elasticbeanstalk.com/api/session",
"UserAgent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"HttpMethod": "POST"
},
"Users": [],
"HasFault": false,
"Annotations": {},
"ResponseTime": 0.084,
"Duration": 0.084,
"Id": "1-59602606-a43a1ac52fc7ee0eea12a82c",
"HasThrottle": false
},
{
"HasError": false,
"Http": {
"HttpStatus": 200,
"ClientIp": "205.255.255.183",
"HttpURL": "http://scorekeep.elasticbeanstalk.com/api/user",
"UserAgent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"HttpMethod": "POST"
},
"Users": [
{
"UserName": "5M388M1E"
}
],
"HasFault": false,
"Annotations": {
"UserID": [
{
"AnnotationValue": {
"StringValue": "5M388M1E"
}
}
],
"Name": [
{
"AnnotationValue": {
"StringValue": "Ola"
}
}
]
},
"ResponseTime": 3.232,
"Duration": 3.232,
"Id": "1-59602603-23fc5b688855d396af79b496",
"HasThrottle": false
}
],
"ApproximateTime": 1499473304.0,
"TracesProcessedCount": 2
}Utilisez l'ID de suivi de la sortie pour obtenir un suivi complet avec l'API BatchGetTraces.
Exemple BatchGetTraces commande
$ aws xray batch-get-traces --trace-ids 1-596025b4-7170afe49f7aa708b1dd4a6bExemple BatchGetTraces sortie
{
"Traces": [
{
"Duration": 3.232,
"Segments": [
{
"Document": "{\"id\":\"1fb07842d944e714\",\"name\":\"random-name\",\"start_time\":1.499473411677E9,\"end_time\":1.499473414572E9,\"parent_id\":\"0c544c1b1bbff948\",\"http\":{\"response\":{\"status\":200}},\"aws\":{\"request_id\":\"ac086670-6373-11e7-a174-f31b3397f190\"},\"trace_id\":\"1-59602603-23fc5b688855d396af79b496\",\"origin\":\"AWS::Lambda\",\"resource_arn\":\"arn:aws:lambda:us-west-2:123456789012:function:random-name\"}",
"Id": "1fb07842d944e714"
},
{
"Document": "{\"id\":\"194fcc8747581230\",\"name\":\"Scorekeep\",\"start_time\":1.499473411562E9,\"end_time\":1.499473414794E9,\"http\":{\"request\":{\"url\":\"http://scorekeep.elasticbeanstalk.com/api/user\",\"method\":\"POST\",\"user_agent\":\"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36\",\"client_ip\":\"205.251.233.183\"},\"response\":{\"status\":200}},\"aws\":{\"elastic_beanstalk\":{\"version_label\":\"app-abb9-170708_002045\",\"deployment_id\":406,\"environment_name\":\"scorekeep-dev\"},\"ec2\":{\"availability_zone\":\"us-west-2c\",\"instance_id\":\"i-0cd9e448944061b4a\"},\"xray\":{\"sdk_version\":\"1.1.2\",\"sdk\":\"X-Ray for Java\"}},\"service\":{},\"trace_id\":\"1-59602603-23fc5b688855d396af79b496\",\"user\":\"5M388M1E\",\"origin\":\"AWS::ElasticBeanstalk::Environment\",\"subsegments\":[{\"id\":\"0c544c1b1bbff948\",\"name\":\"Lambda\",\"start_time\":1.499473411629E9,\"end_time\":1.499473414572E9,\"http\":{\"response\":{\"status\":200,\"content_length\":14}},\"aws\":{\"log_type\":\"None\",\"status_code\":200,\"function_name\":\"random-name\",\"invocation_type\":\"RequestResponse\",\"operation\":\"Invoke\",\"request_id\":\"ac086670-6373-11e7-a174-f31b3397f190\",\"resource_names\":[\"random-name\"]},\"namespace\":\"aws\"},{\"id\":\"071684f2e555e571\",\"name\":\"## UserModel.saveUser\",\"start_time\":1.499473414581E9,\"end_time\":1.499473414769E9,\"metadata\":{\"debug\":{\"test\":\"Metadata string from UserModel.saveUser\"}},\"subsegments\":[{\"id\":\"4cd3f10b76c624b4\",\"name\":\"DynamoDB\",\"start_time\":1.49947341469E9,\"end_time\":1.499473414769E9,\"http\":{\"response\":{\"status\":200,\"content_length\":57}},\"aws\":{\"table_name\":\"scorekeep-user\",\"operation\":\"UpdateItem\",\"request_id\":\"MFQ8CGJ3JTDDVVVASUAAJGQ6NJ82F738BOB4KQNSO5AEMVJF66Q9\",\"resource_names\":[\"scorekeep-user\"]},\"namespace\":\"aws\"}]}]}",
"Id": "194fcc8747581230"
},
{
"Document": "{\"id\":\"00f91aa01f4984fd\",\"name\":\"random-name\",\"start_time\":1.49947341283E9,\"end_time\":1.49947341457E9,\"parent_id\":\"1fb07842d944e714\",\"aws\":{\"function_arn\":\"arn:aws:lambda:us-west-2:123456789012:function:random-name\",\"resource_names\":[\"random-name\"],\"account_id\":\"123456789012\"},\"trace_id\":\"1-59602603-23fc5b688855d396af79b496\",\"origin\":\"AWS::Lambda::Function\",\"subsegments\":[{\"id\":\"e6d2fe619f827804\",\"name\":\"annotations\",\"start_time\":1.499473413012E9,\"end_time\":1.499473413069E9,\"annotations\":{\"UserID\":\"5M388M1E\",\"Name\":\"Ola\"}},{\"id\":\"b29b548af4d54a0f\",\"name\":\"SNS\",\"start_time\":1.499473413112E9,\"end_time\":1.499473414071E9,\"http\":{\"response\":{\"status\":200}},\"aws\":{\"operation\":\"Publish\",\"region\":\"us-west-2\",\"request_id\":\"a2137970-f6fc-5029-83e8-28aadeb99198\",\"retries\":0,\"topic_arn\":\"arn:aws:sns:us-west-2:123456789012:awseb-e-ruag3jyweb-stack-NotificationTopic-6B829NT9V5O9\"},\"namespace\":\"aws\"},{\"id\":\"2279c0030c955e52\",\"name\":\"Initialization\",\"start_time\":1.499473412064E9,\"end_time\":1.499473412819E9,\"aws\":{\"function_arn\":\"arn:aws:lambda:us-west-2:123456789012:function:random-name\"}}]}",
"Id": "00f91aa01f4984fd"
},
{
"Document": "{\"id\":\"17ba309b32c7fbaf\",\"name\":\"DynamoDB\",\"start_time\":1.49947341469E9,\"end_time\":1.499473414769E9,\"parent_id\":\"4cd3f10b76c624b4\",\"inferred\":true,\"http\":{\"response\":{\"status\":200,\"content_length\":57}},\"aws\":{\"table_name\":\"scorekeep-user\",\"operation\":\"UpdateItem\",\"request_id\":\"MFQ8CGJ3JTDDVVVASUAAJGQ6NJ82F738BOB4KQNSO5AEMVJF66Q9\",\"resource_names\":[\"scorekeep-user\"]},\"trace_id\":\"1-59602603-23fc5b688855d396af79b496\",\"origin\":\"AWS::DynamoDB::Table\"}",
"Id": "17ba309b32c7fbaf"
},
{
"Document": "{\"id\":\"1ee3c4a523f89ca5\",\"name\":\"SNS\",\"start_time\":1.499473413112E9,\"end_time\":1.499473414071E9,\"parent_id\":\"b29b548af4d54a0f\",\"inferred\":true,\"http\":{\"response\":{\"status\":200}},\"aws\":{\"operation\":\"Publish\",\"region\":\"us-west-2\",\"request_id\":\"a2137970-f6fc-5029-83e8-28aadeb99198\",\"retries\":0,\"topic_arn\":\"arn:aws:sns:us-west-2:123456789012:awseb-e-ruag3jyweb-stack-NotificationTopic-6B829NT9V5O9\"},\"trace_id\":\"1-59602603-23fc5b688855d396af79b496\",\"origin\":\"AWS::SNS\"}",
"Id": "1ee3c4a523f89ca5"
}
],
"Id": "1-59602603-23fc5b688855d396af79b496"
}
],
"UnprocessedTraceIds": []
}Le suivi complet inclut un document pour chaque segment, compilé à partir de l'ensemble des documents de segments reçus pour le même ID de suivi. Ces documents ne représentent pas les données telles qu'elles ont été envoyées à X-Ray par votre application. Ils représentent plutôt les documents traités générés par le service X-Ray. X-Ray crée le document de trace complet en compilant les documents de segment envoyés par votre application et en supprimant les données non conformes au schéma du document de segment. Pour plus d’informations, consultez Documents relatifs au segment X-Ray.
X-Ray crée également des segments déduits pour les appels en aval vers des services qui n'envoient pas de segments eux-mêmes. Par exemple, lorsque vous appelez DynamoDB avec un client instrumenté, le SDK X-Ray enregistre un sous-segment contenant des détails sur l'appel du point de vue de celui-ci. Cependant, DynamoDB n'envoie pas de segment correspondant. X-Ray utilise les informations du sous-segment pour créer un segment inféré représentant la ressource DynamoDB dans la carte de trace, et l'ajoute au document de trace.
Pour obtenir plusieurs suivis à partir de l'API, vous avez besoin d'une liste d'ID de suivi, que vous pouvez extraire de la sortie de get-trace-summaries avec une requête de l'AWS CLI. Redirigez la liste vers l'entrée de batch-get-traces pour obtenir des traces complètes pour une période spécifique.
Exemple Script permettant d'obtenir les suivis complets pour une période d'une minute
EPOCH=$(date +%s) TRACEIDS=$(aws xray get-trace-summaries --start-time $(($EPOCH-120)) --end-time $(($EPOCH-60)) --query 'TraceSummaries[*].Id' --output text) aws xray batch-get-traces --trace-ids $TRACEIDS --query 'Traces[*]'
Lors de la génération d'un résumé de trace avec l'GetTraceSummaries API, les résumés de suivi partiels peuvent être réutilisés dans leur format JSON pour créer une expression de filtre affinée basée sur les causes premières. Consultez les exemples ci-dessous pour connaître les étapes d’affinage.
Exemple GetTraceSummaries de sortie : section sur les causes premières du temps de réponse
{ "Services": [ { "Name": "GetWeatherData", "Names": ["GetWeatherData"], "AccountId": 123456789012, "Type": null, "Inferred": false, "EntityPath": [ { "Name": "GetWeatherData", "Coverage": 1.0, 'Remote": false }, { "Name": "get_temperature", "Coverage": 0.8, "Remote": false } ] }, { "Name": "GetTemperature", "Names": ["GetTemperature"], "AccountId": 123456789012, "Type": null, "Inferred": false, "EntityPath": [ { "Name": "GetTemperature", "Coverage": 0.7, "Remote": false } ] } ] }
En modifiant la sortie ci-dessus ou en lui appliquant des omissions, ce fichier JSON peut devenir un filtre pour les entités de cause racine correspondantes. Pour chaque champ de cette sortie JSON, les correspondances de candidat doivent être exactes pour que le suivi soit renvoyé. Les champs supprimés deviennent des valeurs de caractères génériques, ce qui correspond à un format compatible avec la structure de requête de l’expression de filtre.
Exemple Cause racine des temps de réponse reformatée
{ "Services": [ { "Name": "GetWeatherData", "EntityPath": [ { "Name": "GetWeatherData" }, { "Name": "get_temperature" } ] }, { "Name": "GetTemperature", "EntityPath": [ { "Name": "GetTemperature" } ] } ] }
Ce format JSON est ensuite utilisé en tant que partie d’une expression de filtre via un appel à rootcause.json = #[{}]. Reportez-vous à la section Utiliser des expressions de filtre dans Explore the X-Ray console pour plus de détails sur les requêtes à l'aide d'expressions de filtre.
Exemple de filtre JSON
rootcause.json = #[{ "Services": [ { "Name": "GetWeatherData", "EntityPath": [{ "Name": "GetWeatherData" }, { "Name": "get_temperature" } ] }, { "Name": "GetTemperature", "EntityPath": [ { "Name": "GetTemperature" } ] } ] }]
X-Ray fournit des API pour configurer les règles d'échantillonnage, les règles de groupe et les paramètres de chiffrement.
Paramètres de chiffrement
Permet PutEncryptionConfigde spécifier une clé AWS Key Management Service (AWS KMS) à utiliser pour le chiffrement.
Note
X-Ray ne prend pas en charge les clés KMS asymétriques.
$ aws xray put-encryption-config --type KMS --key-id alias/aws/xray
{
"EncryptionConfig": {
"KeyId": "arn:aws:kms:us-east-2:123456789012:key/c234g4e8-39e9-4gb0-84e2-b0ea215cbba5",
"Status": "UPDATING",
"Type": "KMS"
}
}Pour l'ID de clé, vous pouvez utiliser un alias (comme illustré dans l'exemple), un ID de clé ou un ARN.
Utilisez GetEncryptionConfig pour obtenir la configuration actuelle. Lorsque X-Ray a fini d'appliquer vos paramètres, le statut passe de UPDATING àACTIVE.
$ aws xray get-encryption-config
{
"EncryptionConfig": {
"KeyId": "arn:aws:kms:us-east-2:123456789012:key/c234g4e8-39e9-4gb0-84e2-b0ea215cbba5",
"Status": "ACTIVE",
"Type": "KMS"
}
}Pour arrêter d'utiliser une clé KMS et utiliser le chiffrement par défaut, définissez le type de chiffrement surNONE.
$ aws xray put-encryption-config --type NONE
{
"EncryptionConfig": {
"Status": "UPDATING",
"Type": "NONE"
}
}Vous pouvez gérer les règles d'échantillonnage de votre compte à l'aide de l'API X-Ray. Pour plus d'informations sur l'échantillonnage, consultezConfiguration des règles d'échantillonnage. Pour plus d'informations sur l'ajout et la gestion de balises, consultezÉtiquetage des règles et des groupes d'échantillonnage aux rayons X.
Obtenez toutes les règles d'échantillonnage avec GetSamplingRules.
$ aws xray get-sampling-rules
{
"SamplingRuleRecords": [
{
"SamplingRule": {
"RuleName": "Default",
"RuleARN": "arn:aws:xray:us-east-2:123456789012:sampling-rule/Default",
"ResourceARN": "*",
"Priority": 10000,
"FixedRate": 0.05,
"ReservoirSize": 1,
"ServiceName": "*",
"ServiceType": "*",
"Host": "*",
"HTTPMethod": "*",
"URLPath": "*",
"Version": 1,
"Attributes": {}
},
"CreatedAt": 0.0,
"ModifiedAt": 1529959993.0
}
]
}Par défaut, la règle s'applique à toutes les demandes qui ne correspond à aucune autre règle. Elle est la règle avec la plus faible priorité et ne peut pas être supprimée. Toutefois, vous pouvez modifier la fréquence et la taille du réservoir avec UpdateSamplingRule.
Exemple Entrée d'API pour UpdateSamplingRule— 10000-default.json
{ "SamplingRuleUpdate": { "RuleName": "Default", "FixedRate": 0.01, "ReservoirSize": 0 } }
L'exemple suivant utilise le fichier précédente en tant qu'entrée pour modifier la règle par défaut sur un pour cent (1 %) sans réservoir. Les balises sont facultatives. Si vous choisissez d'ajouter des balises, une clé de balise est requise et les valeurs des balises sont facultatives. Pour supprimer des balises existantes d'une règle d'échantillonnage, utilisez UntagResource.
$ aws xray update-sampling-rule --cli-input-json file://1000-default.json --tags [{"Key": "key_name","Value": "value"},{"Key": "key_name","Value": "value"}]
{
"SamplingRuleRecords": [
{
"SamplingRule": {
"RuleName": "Default",
"RuleARN": "arn:aws:xray:us-east-2:123456789012:sampling-rule/Default",
"ResourceARN": "*",
"Priority": 10000,
"FixedRate": 0.01,
"ReservoirSize": 0,
"ServiceName": "*",
"ServiceType": "*",
"Host": "*",
"HTTPMethod": "*",
"URLPath": "*",
"Version": 1,
"Attributes": {}
},
"CreatedAt": 0.0,
"ModifiedAt": 1529959993.0
},
Créez les règles d'échantillonnage supplémentaires avec CreateSamplingRule. Lorsque vous créez une règle, la plupart des champs de la règle sont obligatoires. L'exemple suivant crée deux règles. Cette première règle définit un taux de base pour l'exemple d'application Scorekeep. Elle correspond à toutes les demandes servies par l'API qui ne correspond pas à la priorité de la règle.
Exemple Entrée d'API pour UpdateSamplingRule— 9000-base-scorekeep.json
{ "SamplingRule": { "RuleName": "base-scorekeep", "ResourceARN": "*", "Priority": 9000, "FixedRate": 0.1, "ReservoirSize": 5, "ServiceName": "Scorekeep", "ServiceType": "*", "Host": "*", "HTTPMethod": "*", "URLPath": "*", "Version": 1 } }
La deuxième règle s'applique également à Scorekeep, mais elle a une priorité plus élevée et est plus spécifique. Cette règle définit un très faible taux d'échantillonnage pour les demandes d'interrogation. Il s'agit de demandes GET effectuées par le client toutes les deux ou trois secondes pour rechercher les modifications apportées à l'état du jeu.
Exemple Entrée d'API pour UpdateSamplingRule— 5000-polling-scorekeep.json
{ "SamplingRule": { "RuleName": "polling-scorekeep", "ResourceARN": "*", "Priority": 5000, "FixedRate": 0.003, "ReservoirSize": 0, "ServiceName": "Scorekeep", "ServiceType": "*", "Host": "*", "HTTPMethod": "GET", "URLPath": "/api/state/*", "Version": 1 } }
Les balises sont facultatives. Si vous choisissez d'ajouter des balises, une clé de balise est requise et les valeurs des balises sont facultatives.
$ aws xray create-sampling-rule --cli-input-json file://5000-polling-scorekeep.json --tags [{"Key": "key_name","Value": "value"},{"Key": "key_name","Value": "value"}]
{
"SamplingRuleRecord": {
"SamplingRule": {
"RuleName": "polling-scorekeep",
"RuleARN": "arn:aws:xray:us-east-1:123456789012:sampling-rule/polling-scorekeep",
"ResourceARN": "*",
"Priority": 5000,
"FixedRate": 0.003,
"ReservoirSize": 0,
"ServiceName": "Scorekeep",
"ServiceType": "*",
"Host": "*",
"HTTPMethod": "GET",
"URLPath": "/api/state/*",
"Version": 1,
"Attributes": {}
},
"CreatedAt": 1530574399.0,
"ModifiedAt": 1530574399.0
}
}
$ aws xray create-sampling-rule --cli-input-json file://9000-base-scorekeep.json
{
"SamplingRuleRecord": {
"SamplingRule": {
"RuleName": "base-scorekeep",
"RuleARN": "arn:aws:xray:us-east-1:123456789012:sampling-rule/base-scorekeep",
"ResourceARN": "*",
"Priority": 9000,
"FixedRate": 0.1,
"ReservoirSize": 5,
"ServiceName": "Scorekeep",
"ServiceType": "*",
"Host": "*",
"HTTPMethod": "*",
"URLPath": "*",
"Version": 1,
"Attributes": {}
},
"CreatedAt": 1530574410.0,
"ModifiedAt": 1530574410.0
}
}Pour supprimer une règle d'échantillonnage, utilisez DeleteSamplingRule.
$ aws xray delete-sampling-rule --rule-name polling-scorekeep
{
"SamplingRuleRecord": {
"SamplingRule": {
"RuleName": "polling-scorekeep",
"RuleARN": "arn:aws:xray:us-east-1:123456789012:sampling-rule/polling-scorekeep",
"ResourceARN": "*",
"Priority": 5000,
"FixedRate": 0.003,
"ReservoirSize": 0,
"ServiceName": "Scorekeep",
"ServiceType": "*",
"Host": "*",
"HTTPMethod": "GET",
"URLPath": "/api/state/*",
"Version": 1,
"Attributes": {}
},
"CreatedAt": 1530574399.0,
"ModifiedAt": 1530574399.0
}
}Vous pouvez utiliser l'API X-Ray pour gérer les groupes de votre compte. Les groupes constituent un ensemble de suivis qui sont définis par une expression de filtre. Vous pouvez utiliser des groupes pour générer des graphiques de service supplémentaires et fournir CloudWatch des statistiques Amazon. Consultez Obtenir des données depuis X-Ray pour plus de détails sur l'utilisation des graphiques et des métriques de service via l'API X-Ray. Pour plus d'informations sur les groupes, consultezConfiguration des groupes. Pour plus d'informations sur l'ajout et la gestion de balises, consultezÉtiquetage des règles et des groupes d'échantillonnage aux rayons X.
Création d'un groupe avec CreateGroup Les balises sont facultatives. Si vous choisissez d'ajouter des balises, une clé de balise est requise et les valeurs des balises sont facultatives.
$ aws xray create-group --group-name "TestGroup" --filter-expression "service(\"example.com\") {fault}" --tags [{"Key": "key_name","Value": "value"},{"Key": "key_name","Value": "value"}]
{
"GroupName": "TestGroup",
"GroupARN": "arn:aws:xray:us-east-2:123456789012:group/TestGroup/UniqueID",
"FilterExpression": "service(\"example.com\") {fault OR error}"
}
Obtenez tous les groupes existants à l'aide de GetGroups.
$ aws xray get-groups
{
"Groups": [
{
"GroupName": "TestGroup",
"GroupARN": "arn:aws:xray:us-east-2:123456789012:group/TestGroup/UniqueID",
"FilterExpression": "service(\"example.com\") {fault OR error}"
},
{
"GroupName": "TestGroup2",
"GroupARN": "arn:aws:xray:us-east-2:123456789012:group/TestGroup2/UniqueID",
"FilterExpression": "responsetime > 2"
}
],
"NextToken": "tokenstring"
}Mettez à jour un groupe à l'aide de UpdateGroup. Les balises sont facultatives. Si vous choisissez d'ajouter des balises, une clé de balise est requise et les valeurs des balises sont facultatives. Pour supprimer des balises existantes d'un groupe, utilisez UntagResource.
$ aws xray update-group --group-name "TestGroup" --group-arn "arn:aws:xray:us-east-2:123456789012:group/TestGroup/UniqueID" --filter-expression "service(\"example.com\") {fault OR error}" --tags [{"Key": "Stage","Value": "Prod"},{"Key": "Department","Value": "QA"}]
{
"GroupName": "TestGroup",
"GroupARN": "arn:aws:xray:us-east-2:123456789012:group/TestGroup/UniqueID",
"FilterExpression": "service(\"example.com\") {fault OR error}"
}
Supprimez un groupe à l'aide de DeleteGroup.
$ aws xray delete-group --group-name "TestGroup" --group-arn "arn:aws:xray:us-east-2:123456789012:group/TestGroup/UniqueID"
{
}
Le SDK X-Ray utilise l'API X-Ray pour obtenir des règles d'échantillonnage, communiquer les résultats d'échantillonnage et obtenir des quotas. Vous pouvez utiliser ces API pour mieux comprendre le fonctionnement des règles d'échantillonnage ou pour implémenter l'échantillonnage dans un langage non pris en charge par le kit de développement X-Ray.
Commencez par obtenir toutes les règles d'échantillonnage avec GetSamplingRules.
$ aws xray get-sampling-rules
{
"SamplingRuleRecords": [
{
"SamplingRule": {
"RuleName": "Default",
"RuleARN": "arn:aws:xray:us-east-1::sampling-rule/Default",
"ResourceARN": "*",
"Priority": 10000,
"FixedRate": 0.01,
"ReservoirSize": 0,
"ServiceName": "*",
"ServiceType": "*",
"Host": "*",
"HTTPMethod": "*",
"URLPath": "*",
"Version": 1,
"Attributes": {}
},
"CreatedAt": 0.0,
"ModifiedAt": 1530558121.0
},
{
"SamplingRule": {
"RuleName": "base-scorekeep",
"RuleARN": "arn:aws:xray:us-east-1::sampling-rule/base-scorekeep",
"ResourceARN": "*",
"Priority": 9000,
"FixedRate": 0.1,
"ReservoirSize": 2,
"ServiceName": "Scorekeep",
"ServiceType": "*",
"Host": "*",
"HTTPMethod": "*",
"URLPath": "*",
"Version": 1,
"Attributes": {}
},
"CreatedAt": 1530573954.0,
"ModifiedAt": 1530920505.0
},
{
"SamplingRule": {
"RuleName": "polling-scorekeep",
"RuleARN": "arn:aws:xray:us-east-1::sampling-rule/polling-scorekeep",
"ResourceARN": "*",
"Priority": 5000,
"FixedRate": 0.003,
"ReservoirSize": 0,
"ServiceName": "Scorekeep",
"ServiceType": "*",
"Host": "*",
"HTTPMethod": "GET",
"URLPath": "/api/state/*",
"Version": 1,
"Attributes": {}
},
"CreatedAt": 1530918163.0,
"ModifiedAt": 1530918163.0
}
]
}
La sortie inclut la règle par défaut et les règles personnalisées. Consultez Configuration des paramètres d'échantillonnage, de groupes et de chiffrement avec l'API X-Ray si vous n'avez pas encore créé de règles d'échantillonnage.
Evaluez les règles par rapport aux demandes entrantes par ordre croissant de priorité. Lorsqu'une règle correspond, utilisez la fréquence et la taille de réservoir fixées pour prendre une décision d'échantillonnage. Enregistrez les demandes échantillonnées et ignorez (à des fins de suivi) les demandes non échantillonnées. Arrêtez l'évaluation des règles lorsqu'une décision d'échantillonnage est prise.
Une taille de réservoir de règles est le nombre cible de suivis à enregistrer par seconde avant d'appliquer la fréquence fixe. Le réservoir s'applique à tous les services cumulativement. Vous ne pouvez donc pas l'utiliser directement. Toutefois, s'il est différent de zéro, vous pouvez emprunter une trace par seconde au réservoir jusqu'à ce que X-Ray vous assigne un quota. Avant de recevoir un quota, enregistrez la première demande chaque seconde et appliquez le taux fixe aux demandes additionnelles. La fréquence fixe est un nombre décimal compris entre 0 et 1,00 (100 %).
L'exemple suivant illustre un appel à GetSamplingTargets avec les détails sur les décisions d'échantillonnage effectuées au cours des 10 dernières secondes.
$ aws xray get-sampling-targets --sampling-statistics-documents '[
{
"RuleName": "base-scorekeep",
"ClientID": "ABCDEF1234567890ABCDEF10",
"Timestamp": "2018-07-07T00:20:06",
"RequestCount": 110,
"SampledCount": 20,
"BorrowCount": 10
},
{
"RuleName": "polling-scorekeep",
"ClientID": "ABCDEF1234567890ABCDEF10",
"Timestamp": "2018-07-07T00:20:06",
"RequestCount": 10500,
"SampledCount": 31,
"BorrowCount": 0
}
]'
{
"SamplingTargetDocuments": [
{
"RuleName": "base-scorekeep",
"FixedRate": 0.1,
"ReservoirQuota": 2,
"ReservoirQuotaTTL": 1530923107.0,
"Interval": 10
},
{
"RuleName": "polling-scorekeep",
"FixedRate": 0.003,
"ReservoirQuota": 0,
"ReservoirQuotaTTL": 1530923107.0,
"Interval": 10
}
],
"LastRuleModification": 1530920505.0,
"UnprocessedStatistics": []
}
La réponse de X-Ray inclut un quota à utiliser au lieu d'emprunter au réservoir. Dans cet exemple, le service a emprunté 10 suivis au réservoir sur 10 secondes et appliqué la fréquence fixe de 10 % aux 100 autres demandes, ce qui se traduit par un total de 20 demandes échantillonnées. Le quota est valable pendant cinq minutes (indiqué par l'heure à vivre) ou jusqu'à ce qu'un nouveau quota soit attribué. X-Ray peut également attribuer un intervalle de rapport plus long que celui par défaut, bien que ce ne soit pas le cas ici.
Note
La réponse de X-Ray n'inclut peut-être pas de quota la première fois que vous l'appelez. Continuez à emprunter au réservoir jusqu'à ce qu'un quota vous sot attribué.
Les deux autres champs de la réponse peuvent indiquer des problèmes avec l'entrée. Vérifiez LastRuleModification par rapport à votre dernier appel de GetSamplingRules. S'il est plus récent, obtenez une nouvelle copie des règles. UnprocessedStatistics peut inclure des erreurs qui indiquent qu'une règle a été supprimée, que les statistiques de document dans l'entrée étaient trop anciennes ou qu'elle comportait des erreurs d'autorisation.
Un segment de suivi est une représentation JSON d'une demande que sert votre application. Un segment de trace enregistre des informations sur la demande d'origine, des informations sur le travail effectué localement par votre application et des sous-segments contenant des informations sur les appels en aval que votre application effectue vers AWS des ressources, des API HTTP et des bases de données SQL.
Un document de segment transmet des informations sur un segment à X-Ray. Un document de segment peut peser jusqu'à 64 kB et contenir un segment entier avec des sous-segments, un fragment de segment indiquant qu'une demande est en cours ou un sous-segment unique envoyé séparément. Vous pouvez envoyer des documents de segment directement à X-Ray à l'aide de l'PutTraceSegmentsAPI.
X-Ray compile et traite les documents segmentés pour générer des résumés de traces interrogeables et des traces complètes auxquels vous pouvez accéder à l'aide des API GetTraceSummarieset BatchGetTraces, respectivement. Outre les segments et sous-segments que vous envoyez à X-Ray, le service utilise les informations contenues dans les sous-segments pour générer des segments déduits et les ajouter à la trace complète. Les segments déduits représentent les services et les ressources en aval sur la carte de suivi.
X-Ray fournit un schéma JSON pour les documents segmentés. Vous pouvez télécharger le schéma ici : xray-segmentdocument-schema-v1.0.0. Les champs et les objets figurant dans le schéma sont décrits plus en détail dans les sections suivantes.
Un sous-ensemble de champs de segment est indexé par X-Ray pour être utilisé avec des expressions de filtre. Par exemple, si vous attribuez un identifiant unique au user champ d'un segment, vous pouvez rechercher des segments associés à des utilisateurs spécifiques dans la console X-Ray ou à l'aide de l'GetTraceSummariesAPI. Pour plus d’informations, consultez Utiliser des expressions de filtre.
Lorsque vous instrumentez votre application avec le SDK X-Ray, celui-ci génère des documents segmentés pour vous. Au lieu d'envoyer les documents segmentés directement à X-Ray, le SDK les transmet via un port UDP local au daemon X-Ray. Pour plus d’informations, consultez Envoi de documents segmentés au daemon X-Ray.
Un segment enregistre les informations de suivi d'une demande que votre application sert. Au minimum, un segment enregistre le nom, l'ID, l'heure de début, l'ID de suivi et l'heure de fin de la demande.
Exemple Segment terminé minimal
{
"name" : "example.com",
"id" : "70de5b6f19ff9a0a",
"start_time" : 1.478293361271E9,
"trace_id" : "1-581cf771-a006649127e371903a2de979",
"end_time" : 1.478293361449E9
}Les champs suivants sont obligatoires, ou soumis à condition, pour les segments.
Note
Les valeurs doivent être des chaînes (jusqu'à 250 caractères), sauf mention contraire.
Champs de segment obligatoires
-
name— Nom logique du service qui a traité la demande, 200 caractères maximum. Par exemple, le nom de votre application ou le nom de domaine. Les noms peuvent contenir des lettres en Unicode, des nombres et des espaces, ainsi que les symboles suivants :_,.,:,/,%,&,#,=,+,\,-,@ -
id— Un identifiant 64 bits pour le segment, unique parmi les segments d'une même trace, en 16 chiffres hexadécimaux. -
trace_id— Un identifiant unique qui connecte tous les segments et sous-segments issus d'une seule demande client.Format d'identification X-Ray Trace
Un X-Ray
trace_idest composé de trois chiffres séparés par des tirets. Par exemple,1-58406520-a006649127e371903a2de979. Cela consiste notamment à :-
Le numéro de version, qui est
1. -
L'heure de la demande d'origine sous Unix Epoch Time en utilisant 8 chiffres hexadécimaux.
Par exemple, le 1er décembre 2016 à 10 h 00 PST est exprimé en
1480615200secondes ou58406520en chiffres hexadécimaux. -
Identifiant 96 bits unique au monde pour la trace en 24 chiffres hexadécimaux.
Note
X-Ray prend désormais en charge les identifiants de trace créés à OpenTelemetry l'aide de tout autre framework conforme à la spécification W3C Trace Context
. Un ID de trace W3C doit être formaté au format X-Ray Trace ID lors de son envoi à X-Ray. Par exemple, l'ID de trace du W3C 4efaaf4d1e8720b39541901950019ee5doit être formaté comme1-4efaaf4d-1e8720b39541901950019ee5lorsqu'il est envoyé à X-Ray. Les identifiants de trace X-Ray incluent l'horodatage de la demande d'origine à l'époque Unix, mais cela n'est pas obligatoire lors de l'envoi des identifiants de trace du W3C au format X-Ray.Sécurité de l'ID de suivi
Les ID de suivi sont visibles dans les en-têtes de réponse. Générez des ID de suivi avec un algorithme aléatoire sécurisé pour garantir que les attaquants ne puissent pas calculer vos futurs ID de suivi et envoyer des demandes à votre application avec ces ID.
-
-
start_time— nombre correspondant à l'heure à laquelle le segment a été créé, en secondes à virgule flottante par rapport à l'époque. Par exemple,1480615200.010ou1.480615200010E9. Utilisez autant de décimales que nécessaire. La résolution en microsecondes est recommandée si elle est disponible. -
end_time— numéro correspondant à l'heure à laquelle le segment a été fermé. Par exemple,1480615200.090ou1.480615200090E9. Spécifiez uneend_timeouin_progress. -
in_progress— booléen, défini sur autruelieu de spécifier unend_timepour enregistrer qu'un segment est démarré mais qu'il n'est pas terminé. Envoyez un segment en cours lorsque votre application reçoit une demande longue à servir, pour suivre la réception de la demande. Lorsque la réponse est envoyée, envoyez le segment terminé pour remplacer le segment en cours. N'envoyez qu'un segment complet, et un ou zéro segment en cours, par demande.
Noms des services
Un segment name doit correspondre au nom de domaine ou au nom logique du service qui génère le segment. Toutefois, cela n'est pas appliqué. Toute application autorisée PutTraceSegmentspeut envoyer des segments sous n'importe quel nom.
Les champs suivants sont facultatifs pour les segments.
Champs de segment facultatifs
-
service— Un objet contenant des informations sur votre application.-
version— Chaîne identifiant la version de votre application qui a répondu à la demande.
-
-
user— Chaîne identifiant l'utilisateur qui a envoyé la demande. -
origin— Type de AWS ressource exécutant votre application.Valeurs prises en charge
-
AWS::EC2::Instance— Une instance Amazon EC2. -
AWS::ECS::Container— Un conteneur Amazon ECS. -
AWS::ElasticBeanstalk::Environment— Un environnement Elastic Beanstalk.
Lorsque plusieurs valeurs sont applicables à votre application, utilisez celle qui est la plus spécifique. Par exemple, un environnement Docker Elastic Beanstalk multicontainer exécute votre application sur un conteneur Amazon ECS, qui s'exécute à son tour sur une instance Amazon EC2. Dans ce cas, vous devez définir l'origine sur
AWS::ElasticBeanstalk::Environmentcar l'environnement est le parent des deux autres ressources. -
-
parent_id— Un ID de sous-segment que vous spécifiez si la demande provient d'une application instrumentée. Le SDK X-Ray ajoute l'ID du sous-segment parent à l'en-tête de suivi pour les appels HTTP en aval. Dans le cas de sous-segments imbriqués, un sous-segment peut avoir un segment ou un sous-segment comme parent. -
http— httpobjets contenant des informations sur la requête HTTP d'origine. -
aws— awsobjet contenant des informations sur la AWS ressource sur laquelle votre application a envoyé la demande. -
error,throttle,fault, etcause— champs d'erreur qui indiquent qu'une erreur s'est produite et qui incluent des informations sur l'exception à l'origine de l'erreur. -
annotations— annotationsobjet avec des paires clé-valeur que vous souhaitez que X-Ray indexe pour la recherche. -
metadata: metadataobjet contenant toutes les données supplémentaires que vous souhaitez stocker dans le segment. -
subsegments— ensemble d'subsegmentobjets.
Vous pouvez créer des sous-segments pour enregistrer les appels Services AWS et les ressources que vous effectuez avec le AWS SDK, les appels vers des API Web HTTP internes ou externes ou les requêtes de base de données SQL. Vous pouvez également créer des sous-segments pour déboguer ou annoter les blocs de code de votre application. Comme les sous-segments peuvent contenir d'autres sous-segments, un sous-segment personnalisé qui enregistre les métadonnées relatives à un appel de fonction interne peut contenir d'autres sous-segments personnalisés et les sous-segments d'appels en aval.
Un sous-segment enregistre un appel en aval du point de vue du service qui l'appelle. X-Ray utilise des sous-segments pour identifier les services en aval qui n'envoient pas de segments et créer des entrées pour eux sur le graphique des services.
Un sous-segment peut être intégré dans un document de segment entier, ou envoyé séparément. Envoyez des sous-segments séparément aux appels en aval de suivi de manière asynchrone pour les demandes de longue durée, ou pour éviter de dépasser la taille du document de segment maximum.
Exemple Segment avec sous-segment intégré
Un sous-segment indépendant possède type comme subsegment et un parent_id qui identifie le segment parent.
{
"trace_id" : "1-5759e988-bd862e3fe1be46a994272793",
"id" : "defdfd9912dc5a56",
"start_time" : 1461096053.37518,
"end_time" : 1461096053.4042,
"name" : "www.example.com",
"http" : {
"request" : {
"url" : "https://www.example.com/health",
"method" : "GET",
"user_agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/601.7.7",
"client_ip" : "11.0.3.111"
},
"response" : {
"status" : 200,
"content_length" : 86
}
},
"subsegments" : [
{
"id" : "53995c3f42cd8ad8",
"name" : "api.example.com",
"start_time" : 1461096053.37769,
"end_time" : 1461096053.40379,
"namespace" : "remote",
"http" : {
"request" : {
"url" : "https://api.example.com/health",
"method" : "POST",
"traced" : true
},
"response" : {
"status" : 200,
"content_length" : 861
}
}
}
]
}Pour les demandes de longue durée, vous pouvez envoyer un segment en cours pour informer X-Ray de la réception de la demande, puis envoyer des sous-segments séparément pour les suivre avant de terminer la demande initiale.
Exemple Segment en cours
{
"name" : "example.com",
"id" : "70de5b6f19ff9a0b",
"start_time" : 1.478293361271E9,
"trace_id" : "1-581cf771-a006649127e371903a2de979",
"in_progress": true
}Exemple Sous-segment indépendant
Un sous-segment indépendant possède type comme subsegment, un trace_id et un parent_id qui identifie le segment parent.
{
"name" : "api.example.com",
"id" : "53995c3f42cd8ad8",
"start_time" : 1.478293361271E9,
"end_time" : 1.478293361449E9,
"type" : "subsegment",
"trace_id" : "1-581cf771-a006649127e371903a2de979"
"parent_id" : "defdfd9912dc5a56",
"namespace" : "remote",
"http" : {
"request" : {
"url" : "https://api.example.com/health",
"method" : "POST",
"traced" : true
},
"response" : {
"status" : 200,
"content_length" : 861
}
}
}Lorsque la demande est terminée, fermez le segment en le renvoyant avec un end_time. Le segment complet remplace le segment en cours.
Vous pouvez également envoyer des sous-segments séparément pour les demandes complètes qui ont déclenché des workflows asynchrones. Par exemple, une API Web peut renvoyer une réponse OK 200 juste avant de démarrer le travail que l'utilisateur demandé. Vous pouvez envoyer un segment complet à X-Ray dès que la réponse est envoyée, suivi de sous-segments pour le travail terminé ultérieurement. Comme pour les segments, vous pouvez aussi envoyer un fragment de sous-segment pour enregistrer le démarrage du sous-segment, puis le remplacer par un sous-segment complet une fois que l'appel en aval est terminé.
Les champs suivants sont obligatoires, ou soumis à condition, pour les sous-segments.
Note
Les valeurs doivent être des chaînes (jusqu'à 250 caractères), sauf mention contraire.
Champs de sous-segment obligatoires
-
id— Un identifiant de 64 bits pour le sous-segment, unique parmi les segments d'une même trace, en 16 chiffres hexadécimaux. -
name— Nom logique du sous-segment. Pour les appels en aval, nommez le sous-segment après l'appel de la ressource ou du service. Pour les sous-segments personnalisés, nommez le sous-segment après le code qu'il instrumente (par exemple, un nom de fonction). -
start_time— nombre correspondant à l'heure à laquelle le sous-segment a été créé, en secondes à virgule flottante par rapport à l'époque, avec une précision de quelques millisecondes. Par exemple,1480615200.010ou1.480615200010E9. -
end_time— numéro correspondant à l'heure à laquelle le sous-segment a été fermé. Par exemple,1480615200.090ou1.480615200090E9. Spécifiez uneend_timeouin_progress. -
in_progress— booléen défini surtrueau lieu de spécifier unend_timepour enregistrer qu'un sous-segment est démarré, mais qu'il n'est pas terminé. Envoyez uniquement un sous-segment complet, et un ou zéro sous-segment en cours, par demande en aval. -
trace_id— ID de trace du segment parent du sous-segment. Obligatoire uniquement en cas d'envoi séparé d'un sous-segment.Format d'identification X-Ray Trace
Un X-Ray
trace_idest composé de trois chiffres séparés par des tirets. Par exemple,1-58406520-a006649127e371903a2de979. Cela consiste notamment à :-
Le numéro de version, qui est
1. -
L'heure de la demande d'origine sous Unix Epoch Time en utilisant 8 chiffres hexadécimaux.
Par exemple, le 1er décembre 2016 à 10 h 00 PST est exprimé en
1480615200secondes ou58406520en chiffres hexadécimaux. -
Identifiant 96 bits unique au monde pour la trace en 24 chiffres hexadécimaux.
Note
X-Ray prend désormais en charge les identifiants de trace créés à OpenTelemetry l'aide de tout autre framework conforme à la spécification W3C Trace Context
. Un ID de trace W3C doit être formaté au format X-Ray Trace ID lors de son envoi à X-Ray. Par exemple, l'ID de trace du W3C 4efaaf4d1e8720b39541901950019ee5doit être formaté comme1-4efaaf4d-1e8720b39541901950019ee5lorsqu'il est envoyé à X-Ray. Les identifiants de trace X-Ray incluent l'horodatage de la demande d'origine à l'époque Unix, mais cela n'est pas obligatoire lors de l'envoi des identifiants de trace du W3C au format X-Ray. -
-
parent_id— ID de segment du segment parent du sous-segment. Obligatoire uniquement en cas d'envoi séparé d'un sous-segment. Dans le cas de sous-segments imbriqués, un sous-segment peut avoir un segment ou un sous-segment comme parent. -
type—subsegment. Obligatoire uniquement si vous envoyez un sous-segment séparément.
Les champs suivants sont facultatifs pour les sous-segments.
Champs de sous-segment facultatifs
-
namespace—awspour les appels du SDK AWS ;remotepour les autres appels en aval. -
http— httpobjet contenant des informations relatives à un appel HTTP sortant. -
aws: awsobjet contenant des informations sur la AWS ressource en aval appelée par votre application. -
error,throttle,fault, etcause— champs d'erreur qui indiquent qu'une erreur s'est produite et qui incluent des informations sur l'exception à l'origine de l'erreur. -
annotations— annotationsobjet avec des paires clé-valeur que vous souhaitez que X-Ray indexe pour la recherche. -
metadata: metadataobjet contenant toutes les données supplémentaires que vous souhaitez stocker dans le segment. -
subsegments— ensemble d'subsegmentobjets. -
precursor_ids— tableau d'identifiants de sous-segments identifiant les sous-segments ayant le même parent que ceux terminés avant ce sous-segment.
Utilisez un bloc HTTP pour enregistrer les détails relatifs à une demande HTTP que votre application a servie (dans un segment) ou que votre application a effectuée auprès d'une API HTTP en aval (dans un sous-segment). La plupart des champs de cet objet correspondent aux informations disponibles dans une demande et une réponse HTTP.
http
Tous les champs sont facultatifs.
-
request— Informations relatives à une demande.-
method— La méthode de demande. Par exemple,GET. -
url— L'URL complète de la demande, compilée à partir du protocole, du nom d'hôte et du chemin de la demande. -
user_agent— La chaîne d'agent utilisateur du client du demandeur. -
client_ip— L'adresse IP du demandeur. Peut être récupérée depuis laSource Addressdu paquet IP ou, pour les demandes acheminées, à partir d'un en-têteX-Forwarded-For. -
x_forwarded_for— (segments uniquement) booléen indiquant que leclient_ipa été lu à partir d'unX-Forwarded-Foren-tête et qu'il n'est pas fiable car il aurait pu être falsifié. -
traced— (sous-segments uniquement) booléen indiquant que l'appel en aval est destiné à un autre service suivi. Si ce champ est défini surtrue, X-Ray considère que la trace est interrompue jusqu'à ce que le service en aval télécharge un segment dont leparent_idnom correspond à celuiiddu sous-segment contenant ce bloc.
-
-
response— Informations relatives à une réponse.-
status— entier indiquant le statut HTTP de la réponse. -
content_length— entier indiquant la longueur du corps de la réponse en octets.
-
Lorsque vous instrumentez un appel à une API Web en aval, enregistrez un sous-segment contenant des informations sur la requête et la réponse HTTP. X-Ray utilise le sous-segment pour générer un segment inféré pour l'API distante.
Exemple Segmentation pour un appel HTTP servi par une application s'exécutant sur Amazon EC2
{
"id": "6b55dcc497934f1a",
"start_time": 1484789387.126,
"end_time": 1484789387.535,
"trace_id": "1-5880168b-fd5158284b67678a3bb5a78c",
"name": "www.example.com",
"origin": "AWS::EC2::Instance",
"aws": {
"ec2": {
"availability_zone": "us-west-2c",
"instance_id": "i-0b5a4678fc325bg98"
},
"xray": {
"sdk_version": "2.11.0 for Java"
},
},
"http": {
"request": {
"method": "POST",
"client_ip": "78.255.233.48",
"url": "http://www.example.com/api/user",
"user_agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0",
"x_forwarded_for": true
},
"response": {
"status": 200
}
}Exemple Sous-segment pour un appel HTTP en aval
{
"id": "004f72be19cddc2a",
"start_time": 1484786387.131,
"end_time": 1484786387.501,
"name": "names.example.com",
"namespace": "remote",
"http": {
"request": {
"method": "GET",
"url": "https://names.example.com/"
},
"response": {
"content_length": -1,
"status": 200
}
}
}Exemple Segment déduit pour un appel HTTP en aval
{
"id": "168416dc2ea97781",
"name": "names.example.com",
"trace_id": "1-62be1272-1b71c4274f39f122afa64eab",
"start_time": 1484786387.131,
"end_time": 1484786387.501,
"parent_id": "004f72be19cddc2a",
"http": {
"request": {
"method": "GET",
"url": "https://names.example.com/"
},
"response": {
"content_length": -1,
"status": 200
}
},
"inferred": true
}Les segments et sous-segments peuvent inclure un annotations objet contenant un ou plusieurs champs indexés par X-Ray pour une utilisation avec des expressions de filtre. Les champs peuvent avoir des valeurs de type chaîne, numérique ou booléen (ni objet ni tableau). X-Ray indexe jusqu'à 50 annotations par trace.
Exemple Segment pour appel HTTP avec annotations
{
"id": "6b55dcc497932f1a",
"start_time": 1484789187.126,
"end_time": 1484789187.535,
"trace_id": "1-5880168b-fd515828bs07678a3bb5a78c",
"name": "www.example.com",
"origin": "AWS::EC2::Instance",
"aws": {
"ec2": {
"availability_zone": "us-west-2c",
"instance_id": "i-0b5a4678fc325bg98"
},
"xray": {
"sdk_version": "2.11.0 for Java"
},
},
"annotations": {
"customer_category" : 124,
"zip_code" : 98101,
"country" : "United States",
"internal" : false
},
"http": {
"request": {
"method": "POST",
"client_ip": "78.255.233.48",
"url": "http://www.example.com/api/user",
"user_agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0",
"x_forwarded_for": true
},
"response": {
"status": 200
}
}Les clés doivent être au format alphanumérique pour fonctionner avec les filtres. Les traits de soulignement sont autorisés. Les autres symboles et les espaces ne sont pas autorisés.
Les segments et sous-segments peuvent inclure un metadata objet contenant un ou plusieurs champs avec des valeurs de n'importe quel type, y compris des objets et des tableaux. X-Ray n'indexe pas les métadonnées et les valeurs peuvent être de n'importe quelle taille, tant que le document segmenté ne dépasse pas la taille maximale (64 kB). Vous pouvez consulter les métadonnées dans le document de segment complet retourné par l'API BatchGetTraces. Les clés de champ (debugdans l'exemple suivant) commençant par AWS. sont réservées aux SDK et aux clients AWS fournis.
Exemple Sous-segment personnalisé avec métadonnées
{
"id": "0e58d2918e9038e8",
"start_time": 1484789387.502,
"end_time": 1484789387.534,
"name": "## UserModel.saveUser",
"metadata": {
"debug": {
"test": "Metadata string from UserModel.saveUser"
}
},
"subsegments": [
{
"id": "0f910026178b71eb",
"start_time": 1484789387.502,
"end_time": 1484789387.534,
"name": "DynamoDB",
"namespace": "aws",
"http": {
"response": {
"content_length": 58,
"status": 200
}
},
"aws": {
"table_name": "scorekeep-user",
"operation": "UpdateItem",
"request_id": "3AIENM5J4ELQ3SPODHKBIRVIC3VV4KQNSO5AEMVJF66Q9ASUAAJG",
"resource_names": [
"scorekeep-user"
]
}
}
]
}Pour les segments, l'objet aws contient les informations relatives à la ressource sur laquelle votre application est en cours d'exécution. Plusieurs champs peuvent s'appliquer à une même ressource. Par exemple, une application exécutée dans un environnement Docker multiconteneur sur Elastic Beanstalk peut contenir des informations sur l'instance Amazon EC2, le conteneur Amazon ECS exécuté sur l'instance et l'environnement Elastic Beanstalk lui-même.
aws (Segments)
Tous les champs sont facultatifs.
-
account_id— Si votre application envoie des segments à un autre Compte AWS, enregistrez l'identifiant du compte qui exécute votre application. -
cloudwatch_logs— Tableau d'objets décrivant un seul groupe de CloudWatch logs.-
log_group— Le nom du groupe de CloudWatch journaux. -
arn— L'ARN du groupe de CloudWatch logs.
-
-
ec2— Informations sur une instance Amazon EC2.-
instance_id— L'ID d'instance de l'instance EC2. -
instance_size— Type d'instance EC2. -
ami_id— L'identifiant Amazon Machine Image. -
availability_zone— La zone de disponibilité dans laquelle l'instance est exécutée.
-
-
ecs— Informations sur un conteneur Amazon ECS.-
container— Le nom d'hôte de votre conteneur. -
container_id— L'identifiant complet de votre conteneur. -
container_arn— L'ARN de votre instance de conteneur.
-
-
eks— Informations sur un cluster Amazon EKS.-
pod— Le nom d'hôte de votre pod EKS. -
cluster_name— Le nom du cluster EKS. -
container_id— L'identifiant complet de votre conteneur.
-
-
elastic_beanstalk— Informations sur un environnement Elastic Beanstalk. Vous trouverez ces informations dans un fichier nommé/var/elasticbeanstalk/xray/environment.confsur les dernières plateformes Elastic Beanstalk.-
environment_name: Nom de l'environnement. -
version_label— Nom de la version de l'application actuellement déployée sur l'instance qui a répondu à la demande. -
deployment_id— numéro indiquant l'ID du dernier déploiement réussi sur l'instance qui a répondu à la demande.
-
-
xray— Des métadonnées sur le type et la version de l'instrumentation utilisée.-
auto_instrumentation— Booléen indiquant si l'instrumentation automatique a été utilisée (par exemple, l'agent Java). -
sdk_version— Version du SDK ou de l'agent utilisé. -
sdk— Le type de SDK.
-
Exemple AWS bloc avec plugins
"aws":{
"elastic_beanstalk":{
"version_label":"app-5a56-170119_190650-stage-170119_190650",
"deployment_id":32,
"environment_name":"scorekeep"
},
"ec2":{
"availability_zone":"us-west-2c",
"instance_id":"i-075ad396f12bc325a",
"ami_id":
},
"cloudwatch_logs":[
{
"log_group":"my-cw-log-group",
"arn":"arn:aws:logs:us-west-2:012345678912:log-group:my-cw-log-group"
}
],
"xray":{
"auto_instrumentation":false,
"sdk":"X-Ray for Java",
"sdk_version":"2.8.0"
}
}
Pour les sous-segments, enregistrez les informations relatives aux ressources Services AWS et aux ressources auxquelles votre application accède. X-Ray utilise ces informations pour créer des segments déduits qui représentent les services en aval dans votre carte des services.
aws (Sous-segments)
Tous les champs sont facultatifs.
-
operation— Le nom de l'action d'API invoquée contre une ressource Service AWS or. -
account_id— Si votre application accède aux ressources d'un autre compte ou envoie des segments vers un autre compte, enregistrez l'ID du compte propriétaire de la AWS ressource à laquelle votre application a accédé. -
region— Si la ressource se trouve dans une région différente de celle de votre application, enregistrez la région. Par exemple,us-west-2. -
request_id— Identifiant unique de la demande. -
queue_url— Pour les opérations sur une file d'attente Amazon SQS, l'URL de la file d'attente. -
table_name— Pour les opérations sur une table DynamoDB, nom de la table.
Exemple Sous-segment pour un appel à DynamoDB pour enregistrer un élément
{
"id": "24756640c0d0978a",
"start_time": 1.480305974194E9,
"end_time": 1.4803059742E9,
"name": "DynamoDB",
"namespace": "aws",
"http": {
"response": {
"content_length": 60,
"status": 200
}
},
"aws": {
"table_name": "scorekeep-user",
"operation": "UpdateItem",
"request_id": "UBQNSO5AEM8T4FDA4RQDEB94OVTDRVV4K4HIRGVJF66Q9ASUAAJG",
}
}Lorsqu'une erreur se produit, vous pouvez enregistrer les détails de l'erreur et les exceptions qui ont été générées. Enregistrez les erreurs dans les segments lorsque votre application renvoie une erreur à l'utilisateur et dans les sous-segments lorsqu'un appel en aval renvoie une erreur.
types d'erreur
Définissez un ou plusieurs des champs suivants sur true pour indiquer qu'une erreur s'est produite. Plusieurs types peuvent s'appliquer en cas d'erreurs composites. Par exemple, une erreur 429 Too Many
Requests d'un appel en aval peut contraindre votre application à renvoyer 500 Internal Server Error, auquel cas les trois types s'appliquent.
-
error— booléen indiquant qu'une erreur client s'est produite (le code d'état de la réponse était 4XX Client Error). -
throttle— booléen indiquant qu'une demande a été limitée (le code d'état de la réponse était 429 demandes trop nombreuses). -
fault— booléen indiquant qu'une erreur de serveur s'est produite (le code d'état de réponse était 5XX Server Error).
Indiquez la cause de l'erreur en incluant un objet cause dans le segment ou le sous-segment.
cause
Une cause peut être un ID d'exception sur 16 caractères ou un objet avec les champs suivants :
-
working_directory— Le chemin complet du répertoire de travail lorsque l'exception s'est produite. -
paths— Le tableau des chemins d'accès aux bibliothèques ou aux modules utilisés lorsque l'exception s'est produite. -
exceptions— Le tableau des objets d'exception.
Incluez les informations détaillées sur l'erreur dans un ou plusieurs objets exception.
exception
Tous les champs sont facultatifs.
-
id— Un identifiant de 64 bits pour l'exception, unique parmi les segments d'une même trace, en 16 chiffres hexadécimaux. -
message— Le message d'exception. -
type— Type d'exception. -
remote— booléen indiquant que l'exception a été provoquée par une erreur renvoyée par un service en aval. -
truncated— entier indiquant le nombre de cadres de pile omis dans lestack. -
skipped— entier indiquant le nombre d'exceptions ignorées entre cette exception et son enfant, c'est-à-dire l'exception qu'elle a provoquée. -
cause— ID d'exception du parent de l'exception, c'est-à-dire de l'exception à l'origine de cette exception. -
stack— tableau d'objets StackFrame.
Le cas échéant, enregistrez les informations relatives à la pile des appels dans les objets stackFrame.
stackFrame
Tous les champs sont facultatifs.
-
path— Le chemin relatif vers le fichier. -
line— La ligne du fichier. -
label— Le nom de la fonction ou de la méthode.
Vous pouvez créer des sous-segments pour les requêtes que votre application effectue auprès d'une base de données SQL.
sql
Tous les champs sont facultatifs.
-
connection_string— Pour les connexions à SQL Server ou à d'autres bases de données qui n'utilisent pas de chaînes de connexion URL, enregistrez la chaîne de connexion, à l'exception des mots de passe. -
url— Pour une connexion à une base de données utilisant une chaîne de connexion URL, enregistrez l'URL, à l'exception des mots de passe. -
sanitized_query— La requête de base de données, avec toutes les valeurs fournies par l'utilisateur supprimées ou remplacées par un espace réservé. -
database_type— Nom du moteur de base de données. -
database_version— Numéro de version du moteur de base de données. -
driver_version— Le nom et le numéro de version du pilote du moteur de base de données utilisé par votre application. -
user— Nom d'utilisateur de la base de données. -
preparation—callsi la requête a utilisé unPreparedCall;statementsi la requête a utiliséPreparedStatementa.
Exemple Sous-segment avec une requête SQL
{
"id": "3fd8634e78ca9560",
"start_time": 1484872218.696,
"end_time": 1484872218.697,
"name": "ebdb@aawijb5u25wdoy.cpamxznpdoq8.us-west-2.rds.amazonaws.com",
"namespace": "remote",
"sql" : {
"url": "jdbc:postgresql://aawijb5u25wdoy.cpamxznpdoq8.us-west-2.rds.amazonaws.com:5432/ebdb",
"preparation": "statement",
"database_type": "PostgreSQL",
"database_version": "9.5.4",
"driver_version": "PostgreSQL 9.4.1211.jre7",
"user" : "dbuser",
"sanitized_query" : "SELECT * FROM customers WHERE customer_id=?;"
}
}