Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Instrumentation AWS Lambda functions
Note
X-Ray SDK/Daemon Avis de maintenance — Le 25 février 2026, ils AWS X-Ray SDKs/Daemon passeront en mode maintenance, où les versions du X-Ray SDK et de Daemon AWS seront limitées uniquement pour résoudre les problèmes de sécurité. Pour plus d'informations sur le calendrier de support, consultezChronologie du support pour le SDK et Daemon X-Ray. Nous vous recommandons de migrer vers OpenTelemetry. Pour plus d'informations sur la migration vers OpenTelemetry, consultez la section Migration de l' X-Ray instrumentation vers OpenTelemetry l'instrumentation.
Scorekeep utilise deux AWS Lambda fonctions. La première est une Node.js fonction de la lambda branche qui génère des noms aléatoires pour les nouveaux utilisateurs. Lorsqu'un utilisateur crée une session sans indiquer de nom, l'application appelle une fonction nommée random-name avec le kit AWS SDK pour Java. Le X-Ray SDK for Java enregistre les informations relatives à l'appel à Lambda dans un sous-segment comme tout autre appel effectué avec un client du SDK instrumenté. AWS
Note
L'exécution de la fonction random-name Lambda nécessite la création de ressources supplémentaires en dehors de l'environnement Elastic Beanstalk. Consultez le fichier readme pour plus d'informations et d'instructions : Intégration AWS
Lambda
La deuxième fonction, scorekeep-worker, est une fonction Python qui s'exécute indépendamment de l'API du Scorekeep. Lorsqu'un jeu se termine, l'API enregistre l'ID de session et l'ID de jeu dans une file d'attente SQS. La fonction de travail lit les éléments de la file d'attente et appelle l'API Scorekeep pour créer des enregistrements complets de chaque session de jeu à stocker dans Amazon S3.
Scorekeep inclut des CloudFormation modèles et des scripts pour créer les deux fonctions. Comme vous devez associer le X-Ray SDK au code de fonction, les modèles créent les fonctions sans aucun code. Lorsque vous déployez Scorekeep, un fichier de configuration inclus dans le dossier .ebextensions crée un bundle source qui inclut le kit SDK et met à jour le code de fonction et la configuration avec l' AWS Command Line Interface.
Fonctions
Nom aléatoire
Scorekeep appelle la fonction de nom aléatoire lorsqu'un utilisateur lance une session de jeu sans s'être connecté ni avoir spécifié de nom d'utilisateur. Lorsque Lambda traite l'appel àrandom-name, il lit l'en-tête de suivi, qui contient l'ID de trace et la décision d'échantillonnage rédigés par le X-Ray SDK for Java.
Pour chaque requête échantillonnée, Lambda exécute X-Ray le démon et écrit deux segments. Le premier segment enregistre les informations relatives à l'appel à Lambda qui appelle la fonction. Ce segment contient les mêmes informations que le sous-segment enregistré par Scorekeep, mais du point de vue Lambda. Le deuxième segment représente la tâche effectuée par la fonction elle-même.
Lambda transmet le segment de fonction au X-Ray SDK via le contexte de la fonction. Lorsque vous instrumentez une fonction Lambda, vous n'utilisez pas le SDK pour créer un segment pour les demandes entrantes. Lambda fournit le segment, et vous utilisez le SDK pour instrumenter les clients et écrire des sous-segments.
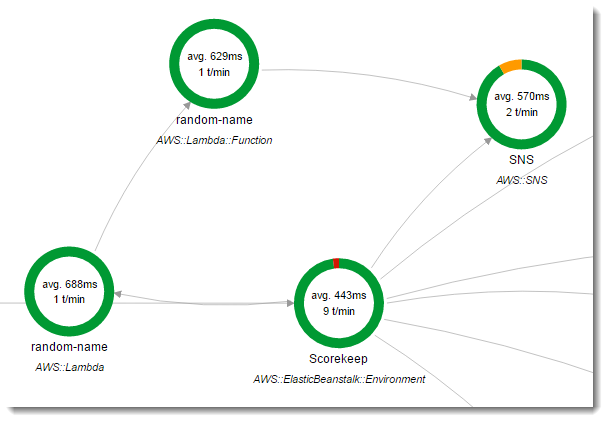
La random-name fonction est implémentée dans Node.js. Il utilise le SDK pour entrer pour JavaScript Node.js envoyer des notifications avec Amazon SNS, et X-Ray le SDK Node.js pour AWS instrumenter le client du SDK. Pour écrire des annotations, la fonction crée un sous-segment personnalisé avec AWSXRay.captureFunc, et écrit des annotations dans la fonction instrumentée. Dans Lambda, vous ne pouvez pas écrire d'annotations directement dans le segment de fonction, mais uniquement dans un sous-segment que vous créez.
Exemple function/index.js
var AWSXRay = require('aws-xray-sdk-core');
var AWS = AWSXRay.captureAWS(require('aws-sdk'));
AWS.config.update({region: process.env.AWS_REGION});
var Chance = require('chance');
var myFunction = function(event, context, callback) {
var sns = new AWS.SNS();
var chance = new Chance();
var userid = event.userid;
var name = chance.first();
AWSXRay.captureFunc('annotations', function(subsegment){
subsegment.addAnnotation('Name', name);
subsegment.addAnnotation('UserID', event.userid);
});
// Notify
var params = {
Message: 'Created randon name "' + name + '"" for user "' + userid + '".',
Subject: 'New user: ' + name,
TopicArn: process.env.TOPIC_ARN
};
sns.publish(params, function(err, data) {
if (err) {
console.log(err, err.stack);
callback(err);
}
else {
console.log(data);
callback(null, {"name": name});
}
});
};
exports.handler = myFunction;Cette fonction est créée automatiquement lorsque vous déployez l'exemple d'application pour Elastic Beanstalk. La xray branche inclut un script permettant de créer une fonction Lambda vide. Les fichiers de configuration contenus dans le .ebextensions dossier créent le package de fonctions npm install pendant le déploiement, puis mettent à jour la fonction Lambda avec la CLI AWS .
Nœuds
La fonction de travail instrumentée est fournie dans sa propre branche, xray-workercar elle ne peut s'exécuter que si vous créez d'abord la fonction de travail et les ressources connexes. Consultez le fichier readme de la branche
La fonction est déclenchée par un événement Amazon CloudWatch Events groupé toutes les 5 minutes. Lorsqu'elle s'exécute, la fonction extrait un élément d'une file d'attente Amazon SQS gérée par Scorekeep. Chaque message contient des informations sur un jeu terminé.
Le travail extrait l'enregistrement et les documents du jeu des autres tables auxquelles cet enregistrement fait référence. Par exemple, l'enregistrement de jeu dans DynamoDB inclut une liste des mouvements exécutés pendant le jeu. Cette liste ne contient pas les déplacements en eux-mêmes, mais plutôt l'ID des déplacements qui sont stockés dans une table distincte.
Les sessions et les états sont également stockés en tant que références. Cela évite que les entrées conservées dans la table du jeu soient trop volumineuses, mais nécessite des appels supplémentaires pour obtenir toutes les informations sur le jeu. Le travailleur déréférence toutes ces entrées et construit un enregistrement complet du jeu sous forme de document unique dans Amazon S3. Lorsque vous souhaitez effectuer des analyses sur les données, vous pouvez exécuter des requêtes directement dans Amazon S3 avec Amazon Athena sans effectuer de migrations de données fastidieuses pour extraire vos données de DynamoDB.
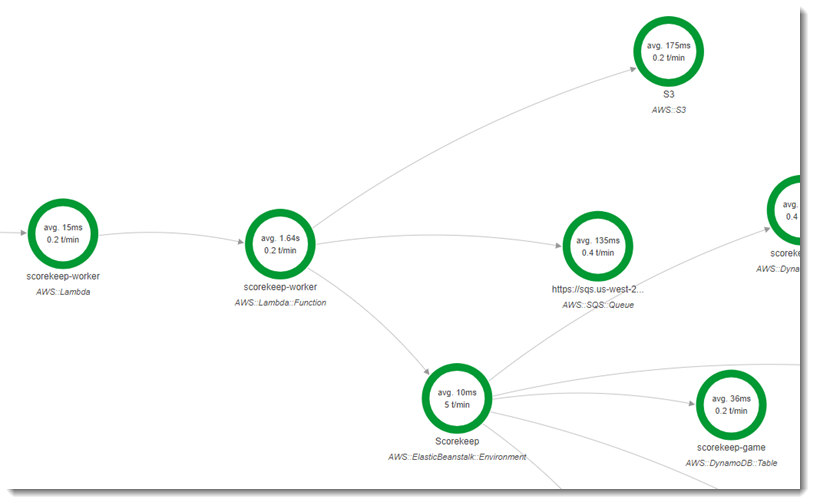
Le suivi actif est activé dans la configuration de la fonction de travail, dans AWS Lambda. Contrairement à la fonction de nom aléatoire, le travailleur ne reçoit pas de demande d'une application instrumentée et AWS Lambda ne reçoit donc pas d'en-tête de suivi. Avec le traçage actif, Lambda crée l'ID de trace et prend les décisions d'échantillonnage.
Le X-Ray SDK pour Python se trouve juste à quelques lignes en haut de la fonction qui importe le SDK et exécute sa patch_all fonction pour patcher les clients HTTP AWS SDK pour Python (Boto) et HTTP qu'il utilise pour appeler Amazon SQS et Amazon S3. Lorsque le travail exécute l'API Scorekeep, le SDK ajoute l'en-tête de suivi à la demande pour suivre les appels via l'API.
Exemple_lambda/scorekeep- worker/scorekeep -worker.py
import os
import boto3
import json
import requests
import time
from aws_xray_sdk.core import xray_recorder
from aws_xray_sdk.core import patch_all
patch_all()
queue_url = os.environ['WORKER_QUEUE']
def lambda_handler(event, context):
# Create SQS client
sqs = boto3.client('sqs')
s3client = boto3.client('s3')
# Receive message from SQS queue
response = sqs.receive_message(
QueueUrl=queue_url,
AttributeNames=[
'SentTimestamp'
],
MaxNumberOfMessages=1,
MessageAttributeNames=[
'All'
],
VisibilityTimeout=0,
WaitTimeSeconds=0
)
...