Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Configuration du SDK X-Ray pour Java
Note
Avis de SDK/Daemon maintenance de X-Ray — Le 25 février 2026, le AWS X-Ray SDKs/Daemon passera en mode maintenance, où les versions du SDK et du Daemon de X-Ray AWS seront limitées uniquement pour résoudre les problèmes de sécurité. Pour plus d'informations sur le calendrier de support, consultezChronologie du support pour le SDK et Daemon X-Ray. Nous vous recommandons de migrer vers OpenTelemetry. Pour plus d'informations sur la migration vers OpenTelemetry, consultez la section Migration de l'instrumentation X-Ray vers OpenTelemetry l'instrumentation.
Le SDK X-Ray pour Java inclut une classe AWSXRay nommée qui fournit l'enregistreur global. Ceci est un TracingHandler que vous pouvez utiliser pour outiller votre code. Vous pouvez configurer l'enregistreur mondial pour personnaliser le AWSXRayServletFilter qui crée des segments pour les appels HTTP entrants.
Sections
Plug-ins de service
Permet plugins d'enregistrer des informations sur le service hébergeant votre application.
Plug-ins
Amazon EC2 :
EC2Pluginajoute l'ID de l'instance, la zone de disponibilité et le groupe de CloudWatch journaux.Elastic
ElasticBeanstalkPluginBeanstalk : ajoute le nom de l'environnement, l'étiquette de version et l'ID de déploiement.Amazon ECS —
ECSPluginajoute l'ID du conteneur.Amazon EKS :
EKSPluginajoute l'ID du conteneur, le nom du cluster, l'ID du pod et le groupe de CloudWatch journaux.
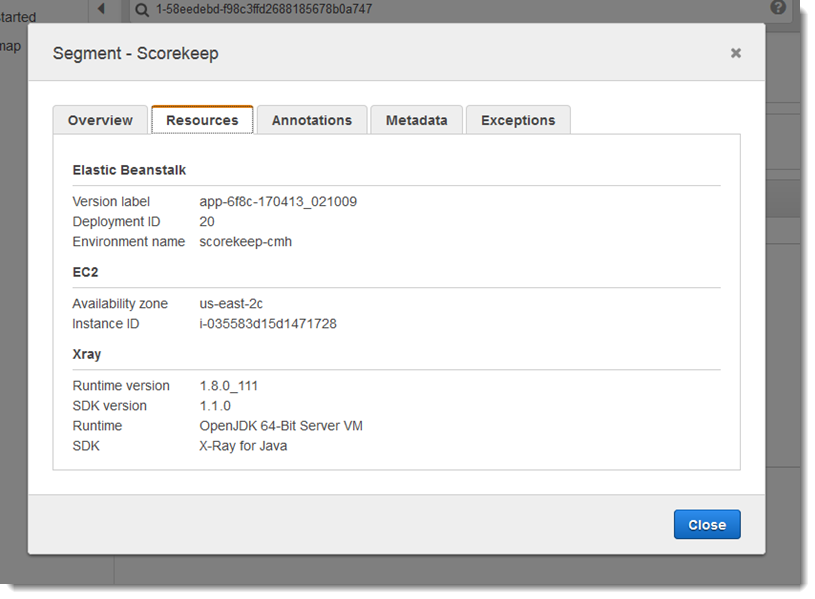
Pour utiliser un plug-in, appelez withPlugin sur votre AWSXRayRecorderBuilder.
Exemple src/main/java/scorekeep/WebConfig.java - enregistreur
import com.amazonaws.xray.AWSXRay;
import com.amazonaws.xray.AWSXRayRecorderBuilder;
import com.amazonaws.xray.plugins.EC2Plugin;
import com.amazonaws.xray.plugins.ElasticBeanstalkPlugin;
import com.amazonaws.xray.strategy.sampling.LocalizedSamplingStrategy;
@Configuration
public class WebConfig {
...
static {
AWSXRayRecorderBuilder builder = AWSXRayRecorderBuilder.standard().withPlugin(new EC2Plugin()).withPlugin(new ElasticBeanstalkPlugin());
URL ruleFile = WebConfig.class.getResource("/sampling-rules.json");
builder.withSamplingStrategy(new LocalizedSamplingStrategy(ruleFile));
AWSXRay.setGlobalRecorder(builder.build());
}
}Le SDK utilise également les paramètres du plugin pour définir le origin champ du segment. Cela indique le type de AWS ressource qui exécute votre application. Lorsque vous utilisez plusieurs plug-ins, le SDK utilise l'ordre de résolution suivant pour déterminer l'origine : ElasticBeanstalk > EKS > ECS > EC2.
Règles d'échantillonnage
Le SDK utilise les règles d'échantillonnage que vous définissez dans la console X-Ray pour déterminer les demandes à enregistrer. La règle par défaut suit la première demande chaque seconde, et 5 % de toutes les demandes supplémentaires provenant de tous les services envoient des traces à X-Ray. Créez des règles supplémentaires dans la console X-Ray pour personnaliser la quantité de données enregistrées pour chacune de vos applications.
Le SDK applique les règles personnalisées dans l'ordre dans lequel elles sont définies. Si une demande correspond à plusieurs règles personnalisées, le SDK applique uniquement la première règle.
Note
Si le SDK ne parvient pas à accéder à X-Ray pour obtenir des règles d'échantillonnage, il revient à une règle locale par défaut concernant la première demande chaque seconde, et 5 % de toutes les demandes supplémentaires par hôte. Cela peut se produire si l'hôte n'est pas autorisé à appeler sampling APIs ou ne peut pas se connecter au daemon X-Ray, qui agit comme un proxy TCP pour les appels d'API effectués par le SDK.
Vous pouvez également configurer le SDK pour charger des règles d'échantillonnage à partir d'un document JSON. Le SDK peut utiliser les règles locales comme solution de rechange dans les cas où l'échantillonnage X-Ray n'est pas disponible, ou utiliser exclusivement les règles locales.
Exemple sampling-rules.json
{
"version": 2,
"rules": [
{
"description": "Player moves.",
"host": "*",
"http_method": "*",
"url_path": "/api/move/*",
"fixed_target": 0,
"rate": 0.05
}
],
"default": {
"fixed_target": 1,
"rate": 0.1
}
}Cet exemple définit une règle personnalisée et une règle par défaut. La règle personnalisée applique un taux d'échantillonnage de 5 % sans nombre minimum de demandes à suivre pour les chemins sous-jacents. /api/move/ La règle par défaut suit la première demande chaque seconde et 10 % des demandes supplémentaires.
L'inconvénient de définir des règles localement est que la cible fixe est appliquée par chaque instance de l'enregistreur indépendamment, au lieu d'être gérée par le service X-Ray. Au fur et à mesure que vous déployez de nouveaux hôtes, le taux fixe est multiplié, ce qui complique le contrôle de la quantité de données enregistrées.
Activé AWS Lambda, vous ne pouvez pas modifier le taux d'échantillonnage. Si votre fonction est appelée par un service instrumenté, les appels ayant généré des demandes échantillonnées par ce service seront enregistrés par Lambda. Si le suivi actif est activé et qu'aucun en-tête de suivi n'est présent, Lambda prend la décision d'échantillonnage.
Pour fournir des règles de sauvegarde dans Spring, configurez l'enregistreur mondial avec une stratégie CentralizedSamplingStrategy dans une classe de configuration.
Exemple src/main/java/myapp/WebConfig.java - configuration de l'enregistreur
import com.amazonaws.xray.AWSXRay;
import com.amazonaws.xray.AWSXRayRecorderBuilder;
import com.amazonaws.xray.javax.servlet.AWSXRayServletFilter;
import com.amazonaws.xray.plugins.EC2Plugin;
import com.amazonaws.xray.strategy.sampling.LocalizedSamplingStrategy;
@Configuration
public class WebConfig {
static {
AWSXRayRecorderBuilder builder = AWSXRayRecorderBuilder.standard().withPlugin(new EC2Plugin());
URL ruleFile = WebConfig.class.getResource("/sampling-rules.json");
builder.withSamplingStrategy(new CentralizedSamplingStrategy(ruleFile));
AWSXRay.setGlobalRecorder(builder.build());
}Pour Tomcat, ajoutez un écouteur qui étend ServletContextListener et enregistrez l'écouteur dans le descripteur de déploiement.
Exemple src/com/myapp/web/Startup.java
import com.amazonaws.xray.AWSXRay;
import com.amazonaws.xray.AWSXRayRecorderBuilder;
import com.amazonaws.xray.plugins.EC2Plugin;
import com.amazonaws.xray.strategy.sampling.LocalizedSamplingStrategy;
import java.net.URL;
import javax.servlet.ServletContextEvent;
import javax.servlet.ServletContextListener;
public class Startup implements ServletContextListener {
@Override
public void contextInitialized(ServletContextEvent event) {
AWSXRayRecorderBuilder builder = AWSXRayRecorderBuilder.standard().withPlugin(new EC2Plugin());
URL ruleFile = Startup.class.getResource("/sampling-rules.json");
builder.withSamplingStrategy(new CentralizedSamplingStrategy(ruleFile));
AWSXRay.setGlobalRecorder(builder.build());
}
@Override
public void contextDestroyed(ServletContextEvent event) { }
}Exemple WEB-INF/web.xml
...
<listener>
<listener-class>com.myapp.web.Startup</listener-class>
</listener>Pour utiliser les règles local uniquement, remplacez CentralizedSamplingStrategy par LocalizedSamplingStrategy.
builder.withSamplingStrategy(newLocalizedSamplingStrategy(ruleFile));
Logging
Par défaut, le SDK envoie des messages de ERROR niveau B dans les journaux de vos applications. Vous pouvez activer la journalisation au niveau du débogage sur le SDK pour générer des journaux plus détaillés dans le fichier journal de votre application. Les niveaux de journalisation valides sont DEBUG INFOWARN,,ERROR, etFATAL. FATALle niveau du journal fait taire tous les messages de journal car le SDK ne se connecte pas au niveau fatal.
Exemple application.properties
Définissez le niveau de journalisation avec la propriété logging.level.com.amazonaws.xray.
logging.level.com.amazonaws.xray = DEBUGUtilisez les journaux de débogage pour identifier les problèmes, tels que des sous-segments ouverts, lorsque vous générez manuellement des sous-segments.
Injection d'ID de suivi dans les journaux
Pour exposer l'ID de trace complet actuel à vos instructions de journal, vous pouvez l'injecter dans le contexte de diagnostic mappé (MDC). À l'aide de l'interface SegmentListener, les méthodes sont appelées à partir de l'enregistreur X-Ray lors des événements du cycle de vie des segments. Lorsqu'un segment ou un sous-segment commence, l'ID de trace qualifié est injecté dans le MDC avec la clé AWS-XRAY-TRACE-ID. Lorsque ce segment se termine, la clé est supprimée du MDC. Ceci expose l'ID de trace à la bibliothèque de journalisation en cours d'utilisation. Lorsqu'un sous-segment se termine, son ID parent est injecté dans le MDC.
Exemple ID de trace complet
L'ID complet est affiché au format TraceID@EntityID
1-5df42873-011e96598b447dfca814c156@541b3365be3dafc3Cette fonctionnalité fonctionne avec les applications Java instrumentées avec le SDK AWS X-Ray pour Java et prend en charge les configurations de journalisation suivantes :
-
SLF4API frontale J avec backend Logback
-
SLF4API frontale J avec backend Log4J2
-
API frontale Log4J2 avec backend Log4J2
Consultez les onglets suivants pour connaître les besoins de chaque frontal et de chaque backend.
Exemple d'injection d'ID de trace
Ce qui suit montre une chaîne PatternLayout modifiée pour inclure l'ID de trace. L'ID de trace est imprimé après le nom du thread (%t) et avant le niveau du journal (%-5p).
Exemple PatternLayout avec injection d'ID
%d{HH:mm:ss.SSS} [%t]%X{AWS-XRAY-TRACE-ID}%-5p %m%n
AWS X-Ray imprime automatiquement la clé et l'identifiant de trace dans l'instruction du journal pour faciliter l'analyse. Ce qui suit montre une instruction de journal à l'aide de la modification de PatternLayout.
Exemple Instruction de journalisation avec injection d'ID
2019-09-10 18:58:30.844 [nio-5000-exec-4]AWS-XRAY-TRACE-ID: 1-5d77f256-19f12e4eaa02e3f76c78f46a@1ce7df03252d99e1 WARN 1 -Your logging message here
Le message de journalisation lui-même est hébergé dans le modèle %m et est défini lors de l'appel de l'enregistreur.
Écouteurs de segment
Les écouteurs de segments sont une interface permettant d'intercepter les événements du cycle de vie tels que le début et la fin des segments produits par le. AWSXRayRecorder L'implémentation d'une fonction d'événement d'écouteur de segment peut consister à ajouter la même annotation à tous les sous-segments lorsqu'ils sont créés avec onBeginSubsegment, à journaliser un message une fois que chaque segment est envoyé au démon à l'aide de afterEndSegment, ou à enregistrer les requêtes envoyées par les intercepteurs SQL à l'aide de beforeEndSubsegment pour vérifier si le sous-segment représente une requête SQL, en ajoutant des métadonnées supplémentaires dans ce cas.
Pour consulter la liste complète des SegmentListener fonctions, consultez la documentation de l'API AWS X-Ray Recorder SDK for Java.
L'exemple suivant montre comment ajouter une annotation cohérente à tous les sous-segments lors de la création avec onBeginSubsegment et comment imprimer un message de journal à la fin de chaque segment avec afterEndSegment.
Exemple MySegmentListener.java
import com.amazonaws.xray.entities.Segment;
import com.amazonaws.xray.entities.Subsegment;
import com.amazonaws.xray.listeners.SegmentListener;
public class MySegmentListener implements SegmentListener {
.....
@Override
public void onBeginSubsegment(Subsegment subsegment) {
subsegment.putAnnotation("annotationKey", "annotationValue");
}
@Override
public void afterEndSegment(Segment segment) {
// Be mindful not to mutate the segment
logger.info("Segment with ID " + segment.getId());
}
}Cet écouteur de segment personnalisé est ensuite référencé lors de la génération de AWSXRayRecorder.
Exemple AWSXRayRecorderBuilder déclaration
AWSXRayRecorderBuilder builder = AWSXRayRecorderBuilder
.standard().withSegmentListener(new MySegmentListener());Variables d’environnement
Vous pouvez utiliser des variables d'environnement pour configurer le SDK X-Ray pour Java. Le kit SDK prend en charge les variables suivantes.
AWS_XRAY_CONTEXT_MISSING— Réglé surRUNTIME_ERRORpour générer des exceptions lorsque votre code instrumenté tente d'enregistrer des données alors qu'aucun segment n'est ouvert.Valeurs valides
-
RUNTIME_ERROR— Lance une exception d'exécution. -
LOG_ERROR— Enregistrez une erreur et continuez (par défaut). -
IGNORE_ERROR— Ignorez l'erreur et continuez.
Des erreurs liées à des segments ou sous-segments manquants peuvent se produire lorsque vous essayez d'utiliser un client instrumenté dans un code de démarrage qui s'exécute lorsqu'aucune demande n'est ouverte, ou dans un code qui génère un nouveau thread.
-
AWS_XRAY_DAEMON_ADDRESS— Définissez l'hôte et le port de l'écouteur du daemon X-Ray. Par défaut, le SDK utilise à la fois127.0.0.1:2000les données de trace (UDP) et l'échantillonnage (TCP). Utilisez cette variable si vous avez configuré le démon pour qu'il écoute sur un port différent ou s'il s'exécute sur un autre hôte.Format
-
Même port —
address:port -
Différents ports —
tcp:address:portudp:address:port
-
-
AWS_LOG_GROUP— Définissez le nom d'un groupe de journaux sur le groupe de journaux associé à votre application. Si votre groupe de journaux utilise le même AWS compte et la même région que votre application, X-Ray recherchera automatiquement les données de segment de votre application à l'aide de ce groupe de journaux spécifié. Pour plus d'informations sur les groupes de journaux, consultez la section Utilisation des groupes de journaux et des flux. -
AWS_XRAY_TRACING_NAME— Définissez un nom de service que le SDK utilise pour les segments. Remplace le nom de service que vous définissez sur la stratégie d'attribution de noms de segment du filtre servlet.
Les variables d'environnement remplacent les propriétés de système et les valeurs équivalentes définies dans le code.
Propriétés système
Vous pouvez utiliser les propriétés de système en tant qu'alternative JVM aux variables d'environnement. Le kit SDK prend en charge les propriétés suivantes :
-
com.amazonaws.xray.strategy.tracingName— Équivalent àAWS_XRAY_TRACING_NAME. -
com.amazonaws.xray.emitters.daemonAddress— Équivalent àAWS_XRAY_DAEMON_ADDRESS. -
com.amazonaws.xray.strategy.contextMissingStrategy— Équivalent àAWS_XRAY_CONTEXT_MISSING.
Si une propriété système et la variable d'environnement équivalente sont toutes les deux définies, c'est la valeur de la variable d'environnement qui est utilisée. Les deux méthodes remplacent les valeurs définies dans le code.
