Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Meminimalkan waktu henti ElastiCache Multi-AZ dengan menggunakan Valkey dan Redis OSS
Ada sejumlah contoh di mana ElastiCache untuk Valkey dan Redis OSS mungkin perlu mengganti node primer; ini termasuk jenis pemeliharaan terencana tertentu dan kejadian yang tidak mungkin dari node primer atau kegagalan Availability Zone.
Penggantian ini menghasilkan beberapa waktu henti untuk cluster, tetapi jika Multi-AZ diaktifkan, waktu henti diminimalkan. Peran simpul primer akan secara otomatis melakukan failover ke salah satu replika baca. Tidak perlu membuat dan menyediakan simpul utama baru, karena ElastiCache akan menangani ini secara transparan. Failover dan promosi replika ini memastikan Anda dapat melanjutkan penulisan ke primer baru segera setelah promosi selesai.
ElastiCache juga menyebarkan nama Domain Name Service (DNS) dari replika yang dipromosikan. Hal ini dilakukan karena jika aplikasi Anda menulis ke titik akhir primer, tidak perlu ada perubahan titik akhir dalam aplikasi Anda. Jika Anda membaca dari titik akhir individual, pastikan untuk mengubah titik akhir baca dari replika yang dipromosikan menjadi primer ke titik akhir dari replika yang baru.
Jika penggantian simpul terencana dimulai karena pembaruan pemeliharaan atau pembaruan mandiri, perhatikan hal berikut:
Untuk cluster Valkey dan Redis OSS, penggantian node yang direncanakan selesai sementara cluster melayani permintaan tulis yang masuk.
Untuk cluster yang dinonaktifkan mode cluster Valkey dan Redis OSS dengan Multi-AZ enabled yang berjalan pada mesin 5.0.6 atau yang lebih baru, penggantian node yang direncanakan selesai saat cluster melayani permintaan tulis yang masuk.
Untuk cluster yang dinonaktifkan mode cluster Valkey dan Redis OSS dengan Multi-AZ diaktifkan yang berjalan pada mesin 4.0.10 atau sebelumnya, Anda mungkin melihat gangguan penulisan singkat yang terkait dengan pembaruan DNS. Gangguan ini mungkin memakan waktu hingga beberapa detik. Proses ini jauh lebih cepat daripada membuat ulang dan menyediakan primer baru, yang terjadi jika Anda tidak mengaktifkannya. Multi-AZ
Anda dapat mengaktifkan Multi-AZ menggunakan ElastiCache Management Console AWS CLI, the, atau ElastiCache API.
catatan
Durability-enabled cluster: Untuk cluster Valkey 9.0+ dengan daya tahan diaktifkan, perilaku failover berbeda dari skenario yang dijelaskan di bawah ini. Dengan daya tahan, semua data yang berkomitmen disimpan dalam log Multi-AZ transaksional. Selama failover, penulisan sinkron memastikan nol kehilangan data, sementara penulisan asinkron dapat kehilangan hingga 10 detik data yang tidak terikat. Node yang gagal mengembalikan semua data yang dikomit dari log transaksional tanpa memerlukan sinkronisasi penuh dari primer. Untuk informasi selengkapnya, lihat Daya tahan di ElastiCache.
ElastiCache Multi-AZ Mengaktifkan klaster Valkey atau Redis OSS Anda (di API dan CLI, grup replikasi) meningkatkan toleransi kesalahan Anda. Hal ini berlaku terutama dalam kasus di mana klaster read/write utama cluster Anda menjadi tidak dapat dijangkau atau gagal karena alasan apa pun. Multi-AZ hanya didukung pada cluster Valkey dan Redis OSS dengan lebih dari satu node di setiap pecahan.
Topik
Mengaktifkan Multi-AZ
Anda dapat mengaktifkan Multi-AZ saat membuat atau memodifikasi cluster (API atau CLI, grup replikasi) menggunakan ElastiCache konsol, AWS CLI, atau API. ElastiCache
Anda Multi-AZ hanya dapat mengaktifkan pada cluster Valkey atau Redis OSS (mode cluster dinonaktifkan) yang memiliki setidaknya satu replika baca yang tersedia. Klaster tanpa replika baca tidak menyediakan ketersediaan tinggi atau toleransi kesalahan. Untuk informasi tentang cara membuat klaster dengan replikasi, lihat Membuat grup replikasi Valkey atau Redis OSS. Untuk informasi tentang cara menambahkan replika baca ke klaster dengan replikasi, lihat Menambahkan replika baca untuk Valkey atau Redis OSS (Mode Cluster Dinonaktifkan).
Topik
Mengaktifkan Multi-AZ (Konsol)
Anda dapat mengaktifkan Multi-AZ menggunakan ElastiCache konsol saat membuat cluster Valkey atau Redis OSS baru atau dengan memodifikasi cluster yang ada dengan replikasi.
Multi-AZ diaktifkan secara default pada cluster Valkey atau Redis OSS (mode cluster diaktifkan).
penting
ElastiCache akan secara otomatis mengaktifkan Multi-AZ hanya jika cluster berisi setidaknya satu replika di Availability Zone yang berbeda dari yang utama di semua pecahan.
Mengaktifkan Multi-AZ saat membuat cluster menggunakan konsol ElastiCache
Lihat informasi selengkapnya tentang prosedur ini, lihat Membuat cluster Valkey (mode cluster dinonaktifkan) (Konsol). Pastikan untuk memiliki satu atau lebih replika dan aktifkan Multi-AZ.
Mengaktifkan Multi-AZ pada cluster yang ada (Konsol)
Untuk informasi selengkapnya tentang proses ini, lihat Mengubah Klaster Menggunakan ElastiCache Konsol Manajemen AWS.
Mengaktifkan Multi-AZ (AWS CLI)
Contoh kode berikut menggunakan AWS CLI Multi-AZ untuk mengaktifkan grup redis12 replikasi.
penting
Replikasi grup redis12 harus sudah ada dan memiliki setidaknya satu replika baca yang tersedia.
Untuk Linux, macOS, atau Unix:
aws elasticache modify-replication-group \ --replication-group-idredis12\ --automatic-failover-enabled \ --multi-az-enabled \ --apply-immediately
Untuk Windows:
aws elasticache modify-replication-group ^ --replication-group-idredis12^ --automatic-failover-enabled ^ --multi-az-enabled ^ --apply-immediately
Output JSON dari perintah ini akan terlihat seperti berikut.
{
"ReplicationGroup": {
"Status": "modifying",
"Description": "One shard, two nodes",
"NodeGroups": [
{
"Status": "modifying",
"NodeGroupMembers": [
{
"CurrentRole": "primary",
"PreferredAvailabilityZone": "us-west-2b",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis12-001.v5r9dc.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis12-001"
},
{
"CurrentRole": "replica",
"PreferredAvailabilityZone": "us-west-2a",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis12-002.v5r9dc.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis12-002"
}
],
"NodeGroupId": "0001",
"PrimaryEndpoint": {
"Port": 6379,
"Address": "redis12.v5r9dc.ng.0001.usw2.cache.amazonaws.com"
}
}
],
"ReplicationGroupId": "redis12",
"SnapshotRetentionLimit": 1,
"AutomaticFailover": "enabling",
"MultiAZ": "enabled",
"SnapshotWindow": "07:00-08:00",
"SnapshottingClusterId": "redis12-002",
"MemberClusters": [
"redis12-001",
"redis12-002"
],
"PendingModifiedValues": {}
}
}Untuk informasi selengkapnya, lihat topik ini dalam Referensi Perintah AWS CLI :
-
modify-replication-group dalam Referensi Perintah AWS CLI .
Mengaktifkan Multi-AZ (ElastiCache API)
Contoh kode berikut menggunakan ElastiCache API Multi-AZ untuk mengaktifkan grup redis12 replikasi.
catatan
Untuk menggunakan contoh ini, grup replikasi redis12 harus sudah ada dan memiliki setidaknya satu replika baca dalam keadaan tersedia.
https://elasticache.us-west-2.amazonaws.com/ ?Action=ModifyReplicationGroup &ApplyImmediately=true &AutoFailover=true &MultiAZEnabled=true &ReplicationGroupId=redis12 &Version=2015-02-02 &SignatureVersion=4 &SignatureMethod=HmacSHA256 &Timestamp=20140401T192317Z &X-Amz-Credential=<credential>
Untuk informasi lain, lihat topik ini di Referensi API ElastiCache :
Skenario kegagalan dengan Multi-AZ tanggapan
Sebelum pengenalan Multi-AZ, ElastiCache mendeteksi dan mengganti node gagal cluster dengan membuat ulang dan reprovisioning node gagal. Jika Anda mengaktifkan Multi-AZ, node primer yang gagal gagal ke replika dengan jeda replikasi paling sedikit. Replika yang dipilih akan dipromosikan secara otomatis menjadi primer, yang jauh lebih cepat daripada membuat dan menetapkan kembali simpul primer baru. Proses ini biasanya memakan waktu hanya beberapa detik hingga Anda dapat menulis lagi ke klaster.
Ketika Multi-AZ diaktifkan, ElastiCache terus memonitor keadaan node utama. Jika simpul primer gagal, salah satu tindakan berikut akan dilakukan bergantung pada jenis kegagalan.
Topik
Skenario kegagalan ketika hanya simpul primer yang gagal
Jika hanya simpul primer yang gagal, replika baca dengan lag replikasi terkecil akan dipromosikan menjadi primer. Replika baca pengganti kemudian dibuat dan ditetapkan di Zona Ketersediaan yang sama dengan primer yang gagal.
Ketika hanya node utama yang gagal, ElastiCache Multi-AZ lakukan hal berikut:
Simpul primer yang gagal akan dibuat offline.
Replika baca dengan lag replikasi terkecil akan dipromosikan menjadi primer.
Proses tulis dapat dilanjutkan segera setelah proses promosi selesai, biasanya hanya beberapa detik. Jika aplikasi Anda menulis ke titik akhir primer, Anda tidak perlu mengubah titik akhir untuk tulis atau baca. ElastiCache menyebarkan nama DNS dari replika yang dipromosikan.
Replika baca pengganti diluncurkan dan ditetapkan.
Replika baca pengganti diluncurkan pada Zona Ketersediaan yang sama dengan simpul primer yang gagal sehingga distribusi simpul tetap terpelihara.
Replika melakukan sinkronisasi dengan simpul primer yang baru.
Setelah replika baru tersedia, perhatikan efeknya berikut ini:
-
Titik akhir primer – Anda tidak perlu membuat perubahan apa pun pada aplikasi Anda, karena nama DNS dari simpul primer baru disebarkan ke titik akhir primer.
-
Titik akhir baca – Titik akhir pembaca diperbarui secara otomatis untuk mengarah ke simpul replika yang baru.
Untuk informasi tentang cara menemukan titik akhir klaster, lihat topik berikut:
Skenario kegagalan ketika simpul primer dan beberapa replika baca gagal
Jika primer dan setidaknya satu replika baca gagal, replika yang tersedia dengan lag replikasi terkecil akan dipromosikan menjadi klaster primer. Replika baca yang baru juga dibuat dan ditetapkan di Zona Ketersediaan yang sama dengan simpul yang gagal dan replika yang dipromosikan menjadi primer.
Ketika node utama dan beberapa replika baca gagal, ElastiCache Multi-AZ lakukan hal berikut:
Simpul primer yang gagal dan replika baca yang gagal akan dibuat offline.
Replika yang tersedia dengan lag replikasi terkecil akan dipromosikan menjadi simpul primer.
Operasi tulis dapat dilanjutkan segera setelah proses promosi selesai, biasanya hanya beberapa detik. Jika aplikasi Anda menulis ke titik akhir utama, tidak perlu mengubah titik akhir untuk menulis. ElastiCache menyebarkan nama DNS dari replika yang dipromosikan.
Replika pengganti dibuat dan ditetapkan.
Replika pengganti dibuat di Zona Ketersediaan dari simpul yang gagal sehingga distribusi simpul tetap terpelihara.
Semua klaster melakukan sinkronisasi dengan simpul primer baru.
Lakukan perubahan berikut pada aplikasi Anda setelah simpul yang baru tersedia:
-
Titik akhir primer – Jangan membuat perubahan apa pun pada aplikasi Anda. Nama DNS dari simpul primer baru disebarkan ke titik akhir primer.
-
Titik akhir baca – Titik akhir baca diperbarui secara otomatis untuk mengarah ke simpul replika yang baru.
Untuk informasi tentang menemukan titik akhir grup replikasi, lihat topik berikut:
Skenario kegagalan ketika seluruh klaster gagal
Jika semuanya gagal, semua simpul dibuat kembali dan ditetapkan pada Zona Ketersediaan yang sama dengan simpul asli.
Dalam skenario ini, semua data dalam klaster akan hilang karena kegagalan dari setiap simpul dalam klaster. Kasus ini jarang terjadi.
Ketika seluruh cluster gagal, ElastiCache Multi-AZ lakukan hal berikut:
Simpul primer dan replika baca yang gagal akan dibuat offline.
Simpul primer pengganti dibuat dan ditetapkan.
Replika pengganti dibuat dan ditetapkan.
Penggantinya dibuat di Zona Ketersediaan dari simpul yang gagal sehingga distribusi simpul tetap dipertahankan.
Karena seluruh klaster gagal, data menjadi hilang dan semua simpul baru akan melakukan cold start.
Karena setiap simpul pengganti memiliki titik akhir yang sama dengan simpul yang digantikannya, Anda tidak perlu membuat perubahan titik akhir pada aplikasi Anda.
Untuk informasi tentang menemukan titik akhir grup replikasi, lihat topik berikut:
Sebaiknya buat simpul primer dan replika baca di Zona Ketersediaan yang berbeda untuk meningkatkan tingkat toleransi kesalahan Anda.
Menguji failover otomatis
Setelah mengaktifkan failover otomatis, Anda dapat mengujinya menggunakan ElastiCache konsol, file AWS CLI, dan ElastiCache API.
Saat menguji, perhatikan hal berikut:
-
Anda dapat menggunakan operasi ini untuk menguji failover otomatis hingga 15 pecahan (disebut grup simpul di ElastiCache API dan AWS CLI) dalam periode 24 jam bergulir apa pun.
-
Jika Anda memanggil operasi ini pada serpihan di klaster yang berbeda (disebut grup replikasi pada API dan CLI), Anda dapat membuat panggilan secara konkuren.
-
Dalam beberapa kasus, Anda mungkin memanggil operasi ini beberapa kali pada pecahan yang berbeda di grup replikasi Valkey atau Redis OSS (mode cluster enabled) yang sama. Dalam kasus tersebut, penggantian simpul pertama harus selesai sebelum panggilan berikutnya dapat dibuat.
-
Untuk menentukan apakah penggantian node selesai, periksa peristiwa menggunakan ElastiCache konsol Amazon, API AWS CLI, atau ElastiCache API. Cari peristiwa yang berkaitan dengan failover otomatis, yang tercantum berikut ini dalam urutan kemungkinan kemunculannya:
-
Pesan grup replikasi:
Test Failover API called for node group <node-group-id> -
Pesan klaster cache:
Failover from primary node <primary-node-id> to replica node <node-id> completed -
Pesan grup replikasi:
Failover from primary node <primary-node-id> to replica node <node-id> completed -
Pesan klaster cache:
Recovering cache nodes <node-id> -
Pesan klaster cache:
Finished recovery for cache nodes <node-id>
Untuk informasi lain, lihat hal berikut:
-
Melihat ElastiCache acara di Panduan Pengguna ElastiCache
-
DescribeEvents di Referensi API ElastiCache
-
describe-events dalam Referensi Perintah AWS CLI .
-
API ini dirancang untuk menguji perilaku aplikasi Anda jika terjadi ElastiCache failover. Hal ini tidak dirancang untuk menjadi alat operasional untuk memulai failover guna mengatasi masalah dengan klaster. Selain itu, dalam kondisi tertentu seperti peristiwa operasional skala besar, AWS dapat memblokir API ini.
Topik
Menguji failover otomatis menggunakan Konsol Manajemen AWS
Gunakan prosedur berikut untuk menguji failover otomatis dengan konsol.
Untuk menguji failover otomatis
-
Masuk ke Konsol Manajemen AWS dan buka ElastiCache konsol di https://console.aws.amazon.com/elasticache/
. -
Di panel navigasi, pilih Valkey atau Redis OSS.
-
Dari daftar cluster, pilih kotak di sebelah kiri cluster yang ingin Anda uji. Klaster ini harus memiliki setidaknya satu simpul replika baca.
-
Di area Detail, konfirmasikan bahwa cluster ini Multi-AZ diaktifkan. Jika klaster tidak Multi-AZ diaktifkan, pilih cluster yang berbeda atau modifikasi cluster ini untuk mengaktifkan Multi-AZ. Untuk informasi selengkapnya, lihat Menggunakan ElastiCache Konsol Manajemen AWS.
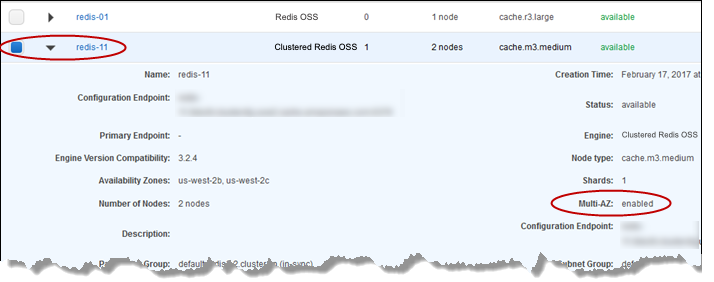
Untuk Valkey atau Redis OSS (mode cluster dinonaktifkan), pilih nama cluster.
Untuk Valkey atau Redis OSS (mode cluster diaktifkan), lakukan hal berikut:
-
Pilih nama klaster.
-
Di halaman Serpihan, untuk serpihan (disebut grup simpul pada API dan CLI) yang ingin Anda uji failover-nya, pilih nama serpihan ini.
-
-
Di halaman Simpul, pilih Failover Primer.
-
Pilih Lanjutkan untuk melakukan failover primer, atau Batalkan untuk membatalkan failover simpul primer.
Selama proses failover, konsol terus menunjukkan status simpul sebagai tersedia. Untuk memantau progres pengujian failover Anda, pilih Peristiwa dari panel navigasi konsol. Di tab Peristiwa, perhatikan peristiwa yang menunjukkan failover Anda telah dimulai (
Test Failover API called) dan selesai (Recovery completed).
Menguji failover otomatis menggunakan AWS CLI
Anda dapat menguji failover otomatis pada cluster yang Multi-AZ diaktifkan menggunakan AWS CLI operasitest-failover.
Parameter
-
--replication-group-id– Wajib. Grup replikasi (di konsol, klaster) yang akan diuji. -
--node-group-id– Wajib. Nama grup simpul yang ingin diuji failover otomatis. Anda dapat menguji maksimal 15 grup node dalam periode 24 jam bergulir.
Contoh berikut menggunakan AWS CLI untuk menguji failover otomatis pada grup redis00-0003 node di Valkey atau Redis OSS (mode cluster enabled) cluster. redis00
contoh Menguji failover otomatis
Untuk Linux, macOS, atau Unix:
aws elasticache test-failover \ --replication-group-idredis00\ --node-group-idredis00-0003
Untuk Windows:
aws elasticache test-failover ^ --replication-group-idredis00^ --node-group-idredis00-0003
Output dari perintah sebelumnya akan terlihat seperti berikut.
{
"ReplicationGroup": {
"Status": "available",
"Description": "1 shard, 3 nodes (1 + 2 replicas)",
"NodeGroups": [
{
"Status": "available",
"NodeGroupMembers": [
{
"CurrentRole": "primary",
"PreferredAvailabilityZone": "us-west-2c",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis1x3-001.7ekv3t.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis1x3-001"
},
{
"CurrentRole": "replica",
"PreferredAvailabilityZone": "us-west-2a",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis1x3-002.7ekv3t.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis1x3-002"
},
{
"CurrentRole": "replica",
"PreferredAvailabilityZone": "us-west-2b",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis1x3-003.7ekv3t.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis1x3-003"
}
],
"NodeGroupId": "0001",
"PrimaryEndpoint": {
"Port": 6379,
"Address": "redis1x3.7ekv3t.ng.0001.usw2.cache.amazonaws.com"
}
}
],
"ClusterEnabled": false,
"ReplicationGroupId": "redis1x3",
"SnapshotRetentionLimit": 1,
"AutomaticFailover": "enabled",
"MultiAZ": "enabled",
"SnapshotWindow": "11:30-12:30",
"SnapshottingClusterId": "redis1x3-002",
"MemberClusters": [
"redis1x3-001",
"redis1x3-002",
"redis1x3-003"
],
"CacheNodeType": "cache.m3.medium",
"DataTiering": "disabled",
"PendingModifiedValues": {}
}
}Untuk melacak kemajuan failover Anda, gunakan AWS CLI describe-events operasi.
Untuk informasi selengkapnya, lihat berikut ini:
-
test-failover dalam Referensi Perintah AWS CLI .
-
describe-events dalam Referensi Perintah AWS CLI .
Menguji failover otomatis menggunakan API ElastiCache
Anda dapat menguji failover otomatis pada klaster mana pun yang diaktifkan dengan Multi-AZ menggunakan operasi ElastiCache TestFailover API.
Parameter
-
ReplicationGroupId– Wajib. Grup replikasi (di konsol, klaster) yang akan diuji. -
NodeGroupId– Wajib. Nama grup simpul yang ingin diuji failover otomatis. Anda dapat menguji maksimal 15 grup node dalam periode 24 jam bergulir.
Contoh berikut menguji failover otomatis pada grup simpul redis00-0003 pada grup replikasi (pada konsol, klaster) redis00.
contoh Menguji failover otomatis
https://elasticache.us-west-2.amazonaws.com/ ?Action=TestFailover &NodeGroupId=redis00-0003 &ReplicationGroupId=redis00 &Version=2015-02-02 &SignatureVersion=4 &SignatureMethod=HmacSHA256 &Timestamp=20140401T192317Z &X-Amz-Credential=<credential>
Untuk melacak kemajuan failover Anda, gunakan operasi ElastiCache DescribeEvents API.
Untuk informasi selengkapnya, lihat berikut ini:
-
TestFailoverdi Referensi ElastiCache API
-
DescribeEventsdi Referensi ElastiCache API
Batasan pada Multi-AZ
Waspadai batasan berikut untuk Multi-AZ:
-
Multi-AZ didukung pada Valkey, dan pada Redis OSS versi 2.8.6 dan yang lebih baru.
-
Multi-AZ tidak didukung pada tipe node T1.
-
Replikasi Valkey dan Redis OSS tidak sinkron. Oleh karena itu, saat simpul primer melakukan failover ke replika, sejumlah kecil data mungkin hilang karena lag replikasi. Untuk cluster dengan daya tahan diaktifkan, batasan ini tidak berlaku — semua data yang berkomitmen dipulihkan dari log Multi-AZ transaksional.
Saat memilih replika untuk dipromosikan ke primer, ElastiCache pilih replika dengan jeda replikasi paling sedikit. Dengan kata lain, yang dipilih adalah replika yang terkini. Hal ini membantu meminimalkan jumlah data yang hilang. Replika dengan lag replikasi terkecil dapat berada di Zona Ketersediaan yang sama atau berbeda dari simpul primer yang gagal.
-
Saat Anda mempromosikan replika baca secara manual ke primer di cluster Valkey atau Redis OSS dengan mode cluster dinonaktifkan, Anda hanya dapat melakukannya ketika Multi-AZ dan failover otomatis dinonaktifkan. Untuk mempromosikan replika baca menjadi primer, lakukan langkah berikut:
-
Nonaktifkan Multi-AZ pada cluster.
-
Nonaktifkan failover otomatis pada klaster. Anda dapat melakukan ini melalui konsol dengan membersihkan kotak centang Auto failover untuk grup replikasi. Anda juga dapat melakukan ini menggunakan AWS CLI dengan mengatur
AutomaticFailoverEnabledpropertifalsesaat memanggilModifyReplicationGroupoperasi. -
Promosikan replika baca menjadi primer.
-
Re-enable Multi-AZ.
-
-
ElastiCache untuk Redis OSS Multi-AZ dan append-only file (AOF) saling eksklusif. Jika Anda mengaktifkan salah satunya, Anda tidak dapat mengaktifkan yang lain.
-
Kegagalan simpul dapat disebabkan oleh peristiwa langka saat seluruh Zona Ketersediaan gagal. Dalam kasus ini, replika untuk menggantikan primer yang gagal akan dibuat hanya saat Zona Ketersediaan sudah dipulihkan. Misalnya, pertimbangkan grup replikasi dengan primer in AZ-a dan replika di dan. AZ-b AZ-c Jika primer gagal, replika dengan lag replikasi terkecil akan dipromosikan menjadi klaster primer. Kemudian, ElastiCache buat replika baru di AZ-a (di mana primer yang gagal berada) hanya saat AZ-a cadangan dan tersedia.
-
Boot ulang primer yang dilakukan oleh pelanggan tidak memicu failover otomatis. Boot ulang lain dan kegagalan akan memicu failover otomatis.
-
Saat primer di-booting ulang, data dihapus dari primer saat primer kembali online. Saat replika baca melihat klaster primer yang bersih tanpa data, replika baca akan menghapus salinan datanya, yang menyebabkan hilangnya data.
-
Setelah replika baca dipromosikan, replika lain melakukan sinkronisasi dengan primer yang baru. Setelah sinkronisasi awal, konten replikasi dihapus dan replika menyinkronkan data dari primer yang baru. Proses sinkronisasi ini menyebabkan gangguan singkat, sehingga replika tidak dapat diakses. Proses sinkronisasi juga menyebabkan peningkatan beban sementara pada primer pada saat melakukan sinkronisasi dengan replika. Perilaku ini asli Valkey dan Redis OSS dan tidak unik untuk. ElastiCache Multi-AZ Untuk detail tentang perilaku ini, lihat Replikasi
di situs web Valkey. Untuk cluster dengan daya tahan diaktifkan, replika memulihkan dari log transaksional secara independen tanpa memaksakan beban pada primer.
penting
Untuk Valkey 7.2.6 dan yang lebih baru atau Redis OSS versi 2.8.22 dan yang lebih baru, Anda tidak dapat membuat replika eksternal.
Untuk versi Redis OSS sebelum 2.8.22, sebaiknya Anda tidak menghubungkan replika eksternal ke cluster yang ElastiCache diaktifkan. Multi-AZ Konfigurasi yang tidak didukung ini dapat membuat masalah yang ElastiCache mencegah terjadinya failover dan pemulihan dengan benar. Untuk menghubungkan replika eksternal ke ElastiCache cluster, pastikan itu Multi-AZ tidak diaktifkan sebelum Anda membuat koneksi.
