Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menyetel parameter memori untuk Aurora PostgreSQL
Di Amazon Aurora PostgreSQL, Anda dapat menggunakan beberapa parameter yang mengontrol jumlah memori yang digunakan untuk berbagai tugas pemrosesan. Jika sebuah tugas membutuhkan lebih banyak memori daripada jumlah yang ditetapkan untuk parameter tertentu, Aurora PostgreSQL akan menggunakan sumber daya lain untuk pemrosesan, seperti dengan menulis ke disk. Hal ini dapat menyebabkan klaster DB Aurora PostgreSQL Anda menjadi lambat atau berpotensi berhenti, dengan kesalahan kehabisan memori.
Pengaturan default untuk setiap parameter memori biasanya dapat menangani tugas pemrosesan yang dimaksudkan. Namun, Anda juga dapat menyetel parameter terkait memori klaster DB Aurora PostgreSQL Anda. Anda melakukan penyetelan ini untuk memastikan bahwa memori yang cukup dialokasikan untuk memproses beban kerja spesifik Anda.
Di bagian berikut ini, Anda dapat menemukan informasi tentang parameter yang mengontrol manajemen memori. Anda juga dapat mempelajari cara menilai pemanfaatan memori.
Memeriksa dan mengatur nilai parameter
Parameter yang dapat Anda atur untuk mengelola memori dan menilai penggunaan memori klaster DB Aurora PostgreSQL Anda meliputi:
work_mem– Menentukan jumlah memori yang digunakan klaster DB Aurora PostgreSQL untuk operasi pengurutan internal dan tabel hash sebelum menulis ke file disk sementara.log_temp_files– Mencatat log pembuatan file sementara, nama file, dan ukuran. Ketika parameter ini diaktifkan, entri log disimpan untuk setiap file sementara yang dibuat. Aktifkan parameter ini untuk melihat seberapa sering klaster DB Aurora PostgreSQL Anda perlu menulis ke disk. Nonaktifkan lagi setelah Anda mengumpulkan informasi tentang pembuatan file sementara klaster DB Aurora PostgreSQL Anda untuk menghindari pencatatan log yang berlebihan.logical_decoding_work_mem— Menentukan jumlah memori (dalam kilobyte) yang akan digunakan oleh setiap buffer penyusun ulang internal sebelum tumpah ke disk. Memori ini digunakan untuk decoding logis, yang merupakan proses untuk membuat replika. Hal ini dilakukan dengan mengkonversi data dari file write-ahead log (WAL) ke output streaming logis yang dibutuhkan oleh target.Nilai parameter ini membuat buffer tunggal dari ukuran yang ditentukan untuk setiap koneksi replikasi. Secara default, nilainya adalah 65536 KB. Setelah buffer ini diisi, kelebihannya akan ditulis ke disk sebagai file. Untuk meminimalkan aktivitas disk, Anda dapat mengatur nilai parameter ini ke nilai yang jauh lebih tinggi daripada
work_mem.
Ini semua adalah parameter dinamis, sehingga Anda dapat mengubahnya untuk sesi saat ini. Untuk melakukannya, hubungkan ke klaster DB Aurora PostgreSQL dengan psql dan menggunakan pernyataan SET, seperti yang ditunjukkan berikut.
SET parameter_name TO parameter_value;Pengaturan sesi hanya berlaku selama sesi berlangsung. Ketika sesi berakhir, parameter akan kembali ke pengaturannya dalam grup parameter klaster DB. Sebelum mengubah parameter apa pun, periksa terlebih dahulu nilai saat ini dengan mengueri tabel pg_settings sebagai berikut.
SELECT unit, setting, max_val FROM pg_settings WHERE name='parameter_name';
Misalnya, untuk menemukan nilai parameter work_mem, hubungkan ke instans penulis klaster DB Aurora PostgreSQL dan jalankan kueri berikut.
SELECT unit, setting, max_val, pg_size_pretty(max_val::numeric) FROM pg_settings WHERE name='work_mem';unit | setting | max_val | pg_size_pretty ------+----------+-----------+---------------- kB | 1024 | 2147483647| 2048 MB (1 row)
Untuk mengubah pengaturan parameter agar dipersistensi, grup parameter klaster DB kustom harus digunakan. Setelah menjalankan klaster DB Aurora PostgreSQL Anda dengan nilai yang berbeda-beda untuk parameter ini menggunakan pernyataan SET, Anda dapat membuat grup parameter kustom dan menerapkannya ke klaster DB Aurora PostgreSQL Anda. Untuk informasi selengkapnya, lihat .
Memahami parameter memori kerja
Parameter memori kerja (work_mem) menentukan jumlah maksimum memori yang dapat digunakan Aurora PostgreSQL untuk memproses kueri kompleks. Kueri kompleks mencakup kueri yang memerlukan operasi pengurutan atau pengelompokan, dengan kata lain, kueri yang menggunakan klausa berikut:
ORDER BY
DISTINCT
GROUP BY
JOIN (MERGE dan HASH)
Perencana kueri secara tidak langsung memengaruhi bagaimana klaster DB Aurora PostgreSQL Anda menggunakan memori kerja. Perencana kueri menghasilkan rencana eksekusi untuk memproses pernyataan SQL. Rencana tertentu dapat memecah kueri kompleks menjadi beberapa unit kerja yang dapat dijalankan secara paralel. Jika memungkinkan, Aurora PostgreSQL akan menggunakan jumlah memori yang ditentukan dalam parameter work_mem untuk setiap sesi sebelum menulis ke disk untuk setiap proses paralel.
Beberapa pengguna basis data yang menjalankan banyak operasi secara bersamaan dan menghasilkan banyak unit kerja secara paralel dapat menghabiskan memori kerja yang dialokasikan untuk klaster DB Aurora PostgreSQL Anda. Hal ini dapat menyebabkan pembuatan file sementara dan disk yang berlebihan I/O, atau lebih buruk lagi, hal itu dapat menyebabkan kesalahan kehabisan memori.
Mengidentifikasi penggunaan file sementara
Setiap kali memori yang diperlukan untuk memproses kueri melebihi nilai yang ditentukan dalam parameter work_mem, data kerja akan dialihkan ke disk dalam file sementara. Anda dapat melihat seberapa sering ini terjadi dengan mengaktifkan parameter log_temp_files. Secara default, parameter ini nonaktif (diatur ke -1). Untuk menangkap semua informasi file sementara, atur parameter ini ke 0. Atur log_temp_files ke bilangan bulat positif lainnya untuk menangkap informasi file sementara untuk file yang sama dengan atau lebih besar dari jumlah data tersebut (dalam kilobyte). Pada gambar berikut, Anda dapat melihat contoh dari Konsol Manajemen AWS.
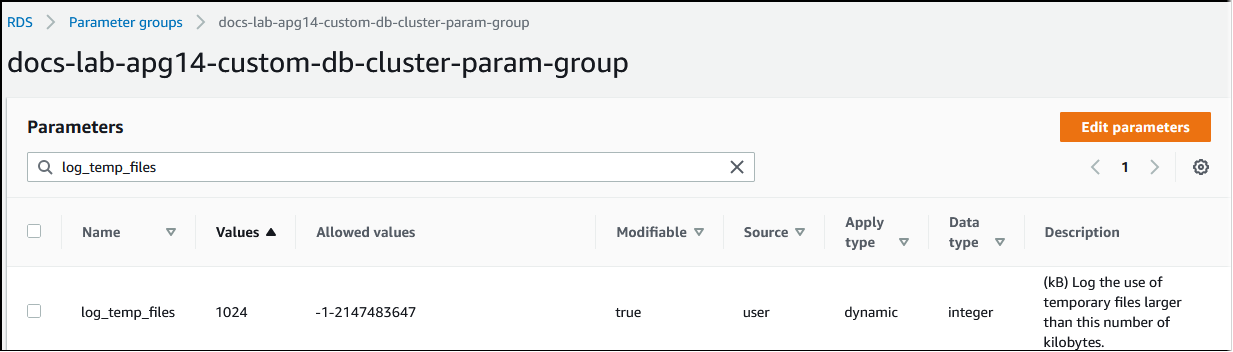
Setelah mengonfigurasi pencatatan log file sementara, Anda dapat menguji dengan beban kerja Anda sendiri untuk melihat apakah pengaturan memori kerja Anda cukup. Anda juga dapat menyimulasikan beban kerja dengan menggunakan pgbench, sebuah aplikasi tolok ukur sederhana dari komunitas PostgreSQL.
Contoh berikut menginisialisasi (-i) pgbench dengan membuat tabel dan baris yang diperlukan untuk menjalankan pengujian. Dalam contoh ini, faktor penskalaan (-s 50) membuat 50 baris dalam tabel pgbench_branches, 500 baris dalam pgbench_tellers, dan 5.000.000 baris dalam tabel pgbench_accounts di basis data labdb.
pgbench -U postgres -h your-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -i -s 50 labdb
Password:
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
5000000 of 5000000 tuples (100%) done (elapsed 15.46 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done in 61.13 s (drop tables 0.08 s, create tables 0.39 s, client-side generate 54.85 s, vacuum 2.30 s, primary keys 3.51 s)Setelah menginisialisasi lingkungan, Anda dapat menjalankan tolok ukur selama waktu (-T) dan jumlah klien (-c) tertentu. Contoh ini juga menggunakan opsi -d untuk menghasilkan informasi debugging seiring transaksi diproses oleh klaster DB Aurora PostgreSQL.
pgbench -h -U postgresyour-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -d -T 60 -c 10labdbPassword:*******pgbench (14.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 10 number of threads: 1 duration: 60 s number of transactions actually processed: 1408 latency average = 398.467 ms initial connection time = 4280.846 ms tps = 25.096201 (without initial connection time)
Untuk informasi selengkapnya tentang pgbench, lihat pgbench
Anda dapat menggunakan perintah metacommand psql (\d) untuk membuat daftar relasi seperti tabel, tampilan, dan indeks yang dibuat oleh pgbench.
labdb=>\d pgbench_accountsTable "public.pgbench_accounts" Column | Type | Collation | Nullable | Default ----------+---------------+-----------+----------+--------- aid | integer | | not null | bid | integer | | | abalance | integer | | | filler | character(84) | | | Indexes: "pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
Seperti yang ditunjukkan pada output, tabel pgbench_accounts diindeks pada kolom aid. Untuk memastikan bahwa kueri berikutnya menggunakan memori kerja, jalankan kueri terhadap kolom yang tidak diindeks, seperti yang ditunjukkan pada contoh berikut.
postgres=>SELECT * FROM pgbench_accounts ORDER BY bid;
Periksa log apakah ada file sementara. Untuk melakukannya, buka Konsol Manajemen AWS, pilih instance cluster Aurora PostgreSQL DB, lalu pilih tab Logs & Events. Lihat log di konsol atau unduh untuk analisis lebih lanjut. Seperti yang ditunjukkan pada gambar berikut, ukuran file sementara yang diperlukan untuk memproses kueri menunjukkan bahwa Anda harus mempertimbangkan untuk meningkatkan jumlah yang ditentukan untuk parameter work_mem.
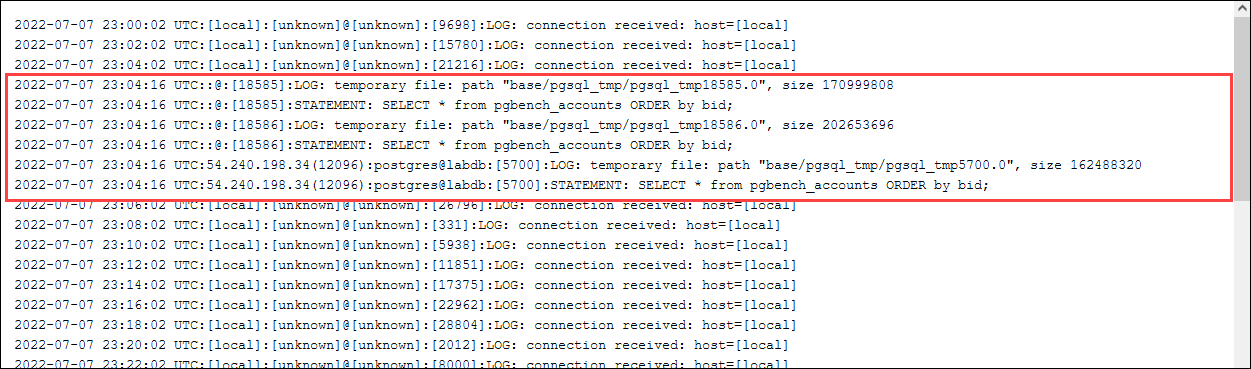
Anda dapat mengonfigurasi parameter ini secara berbeda untuk individu dan grup, berdasarkan kebutuhan operasional Anda. Misalnya, Anda dapat mengatur parameter work_mem ke 8 GB untuk peran bernamadev_team.
postgres=>ALTER ROLEdev_teamSET work_mem=‘8GB';
Dengan pengaturan untuk work_mem ini, peran apa pun yang merupakan anggota peran dev_team akan diberi alokasi hingga 8 GB memori kerja.
Menggunakan indeks untuk waktu respons yang lebih cepat
Jika kueri Anda terlalu lama untuk memberikan hasil, Anda dapat memverifikasi bahwa indeks Anda digunakan seperti yang diharapkan. Pertama, aktifkan \timing, metacommand psql, sebagai berikut.
postgres=>\timing on
Setelah mengaktifkan pewaktuan, gunakan pernyataan SELECT sederhana.
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 3119.049 ms (00:03.119)
Seperti yang ditunjukkan pada output, kueri ini membutuhkan waktu lebih dari 3 detik untuk diselesaikan. Untuk mempersingkat waktu respons, buat indeks di pgbench_accounts sebagai berikut.
postgres=>CREATE INDEX ON pgbench_accounts(bid);CREATE INDEX
Jalankan kembali kueri, dan perhatikan waktu respons yang lebih cepat. Dalam contoh ini, kueri selesai sekitar 5 kali lebih cepat, dalam waktu sekitar setengah detik.
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 567.095 ms
Menyesuaikan memori kerja untuk pendekodean logis
Replikasi logis telah tersedia di semua versi Aurora PostgreSQL sejak diperkenalkan di PostgreSQL versi 10. Saat Anda mengonfigurasi replikasi logis, Anda juga dapat mengatur parameter logical_decoding_work_mem untuk menentukan jumlah memori yang dapat digunakan proses pendekodean logis untuk proses pendekodean dan streaming.
Selama pendekodean logis, catatan write-ahead log (WAL) dikonversi menjadi pernyataan SQL yang kemudian dikirim ke target lain untuk replikasi logis atau tugas lain. Ketika transaksi ditulis ke WAL lalu dikonversi, seluruh transaksi harus sesuai dengan nilai yang ditentukan untuk logical_decoding_work_mem. Secara default, parameter ini diatur ke 65536 KB. Setiap kelebihan akan ditulis ke disk. Artinya data tersebut harus dibaca ulang dari disk sebelum dapat dikirim ke tujuannya, sehingga memperlambat prosesnya secara keseluruhan.
Anda dapat menilai jumlah kelebihan transaksi dalam beban kerja Anda saat ini pada titik waktu tertentu dengan menggunakan fungsi aurora_stat_file seperti yang ditunjukkan pada contoh berikut.
SELECT split_part (filename, '/', 2) AS slot_name, count(1) AS num_spill_files, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM aurora_stat_file() WHERE filename like '%spill%' GROUP BY 1;slot_name | num_spill_files | slot_total_bytes | slot_total_size ------------+-----------------+------------------+----------------- slot_name | 590 | 411600000 | 393 MB (1 row)
Kueri ini menghasilkan jumlah dan ukuran spill file pada klaster DB Aurora PostgreSQL Anda saat kueri diinvokasi. Beban kerja yang berjalan lebih lama mungkin belum memiliki spill file pada disk. Untuk membuat profil beban kerja yang berjalan lama, sebaiknya Anda membuat tabel untuk menangkap informasi spill file saat beban kerja berjalan. Anda dapat membuat tabel sebagai berikut.
CREATE TABLE spill_file_tracking AS SELECT now() AS spill_time,* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
Untuk melihat bagaimana spill file digunakan selama replikasi logis, siapkan penerbit dan pelanggan lalu mulai replikasi sederhana. Untuk informasi selengkapnya, lihat Menyiapkan replikasi logis untuk klaster DB Aurora PostgreSQL Anda. Dengan replikasi yang sedang berlangsung, Anda dapat membuat pekerjaan yang menangkap hasil yang ditetapkan dari fungsi spill file aurora_stat_file() sebagai berikut.
INSERT INTO spill_file_tracking SELECT now(),* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
Gunakan perintah psql berikut untuk menjalankan pekerjaan sekali per detik.
\watch 0.5
Saat pekerjaan sedang berjalan, hubungkan ke instans penulis dari sesi psql lain. Gunakan rangkaian pernyataan berikut untuk menjalankan beban kerja yang melebihi konfigurasi memori dan menyebabkan Aurora PostgreSQL membuat spill file.
labdb=>CREATE TABLE my_table (a int PRIMARY KEY, b int);CREATE TABLElabdb=>INSERT INTO my_table SELECT x,x FROM generate_series(0,10000000) x;INSERT 0 10000001labdb=>UPDATE my_table SET b=b+1;UPDATE 10000001
Pernyataan ini membutuhkan waktu beberapa menit untuk selesai. Setelah selesai, tekan tombol Ctrl dan tombol C bersama-sama untuk menghentikan fungsi pemantauan. Kemudian, gunakan perintah berikut untuk membuat tabel untuk menyimpan informasi tentang penggunaan spill file klaster DB Aurora PostgreSQL.
SELECT spill_time, split_part (filename, '/', 2) AS slot_name, count(1) AS spills, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM spill_file_tracking GROUP BY 1,2 ORDER BY 1;spill_time | slot_name | spills | slot_total_bytes | slot_total_size ------------------------------+-----------------------+--------+------------------+----------------- 2022-04-15 13:42:52.528272+00 | replication_slot_name | 1 | 142352280 | 136 MB 2022-04-15 14:11:33.962216+00 | replication_slot_name | 4 | 467637996 | 446 MB 2022-04-15 14:12:00.997636+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:03.030245+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:05.059761+00 | replication_slot_name | 5 | 618410996 | 590 MB 2022-04-15 14:12:07.22905+00 | replication_slot_name | 5 | 640585316 | 611 MB (6 rows)
Output ini menunjukkan bahwa contoh yang dijalankan telah membuat lima spill file yang menggunakan memori 611 MB. Untuk menghindari penulisan ke disk, kami menyarankan agar mengatur parameter logical_decoding_work_mem ke ukuran memori tertinggi berikutnya, 1024.
