Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menggunakan CloudWatch metrik Amazon untuk menganalisis penggunaan sumber daya untuk Aurora PostgreSQL
Aurora secara otomatis mengirimkan data metrik ke CloudWatch dalam periode 1 menit. Anda dapat menganalisis penggunaan sumber daya untuk Aurora PostgreSQL menggunakan metrik. CloudWatch Anda dapat mengevaluasi throughput jaringan dan penggunaan jaringan dengan metrik tersebut.
Mengevaluasi throughput jaringan dengan CloudWatch
Ketika penggunaan sistem Anda mendekati batas sumber daya untuk jenis instans Anda, pemrosesan dapat melambat. Anda dapat menggunakan Wawasan CloudWatch Log untuk memantau penggunaan sumber daya penyimpanan Anda dan memastikan bahwa sumber daya yang cukup tersedia. Bila diperlukan, Anda dapat mengubah instans DB ke kelas instans yang lebih besar.
Pemrosesan penyimpanan Aurora mungkin lambat karena:
-
Bandwidth jaringan tidak mencukupi antara instans DB dan klien.
-
Bandwidth jaringan tidak mencukupi untuk subsistem penyimpanan.
-
Beban kerja yang besar untuk jenis instans Anda.
Anda dapat meminta Wawasan CloudWatch Log untuk menghasilkan grafik penggunaan sumber daya penyimpanan Aurora untuk memantau sumber daya. Grafik tersebut menampilkan metrik dan pemanfaatan CPU untuk membantu Anda memutuskan apakah akan menaikkan skala menjadi instans yang lebih besar. Untuk informasi tentang sintaks kueri untuk Wawasan CloudWatch Log, lihat sintaks kueri Wawasan CloudWatch Log
Untuk menggunakannya CloudWatch, Anda perlu mengekspor file log Aurora PostgreSQL Anda ke file log. CloudWatch Anda juga dapat memodifikasi klaster yang ada untuk mengekspor log ke CloudWatch. Untuk informasi tentang mengekspor log ke CloudWatch, lihatMengaktifkan opsi untuk menerbitkan log ke Amazon CloudWatch.
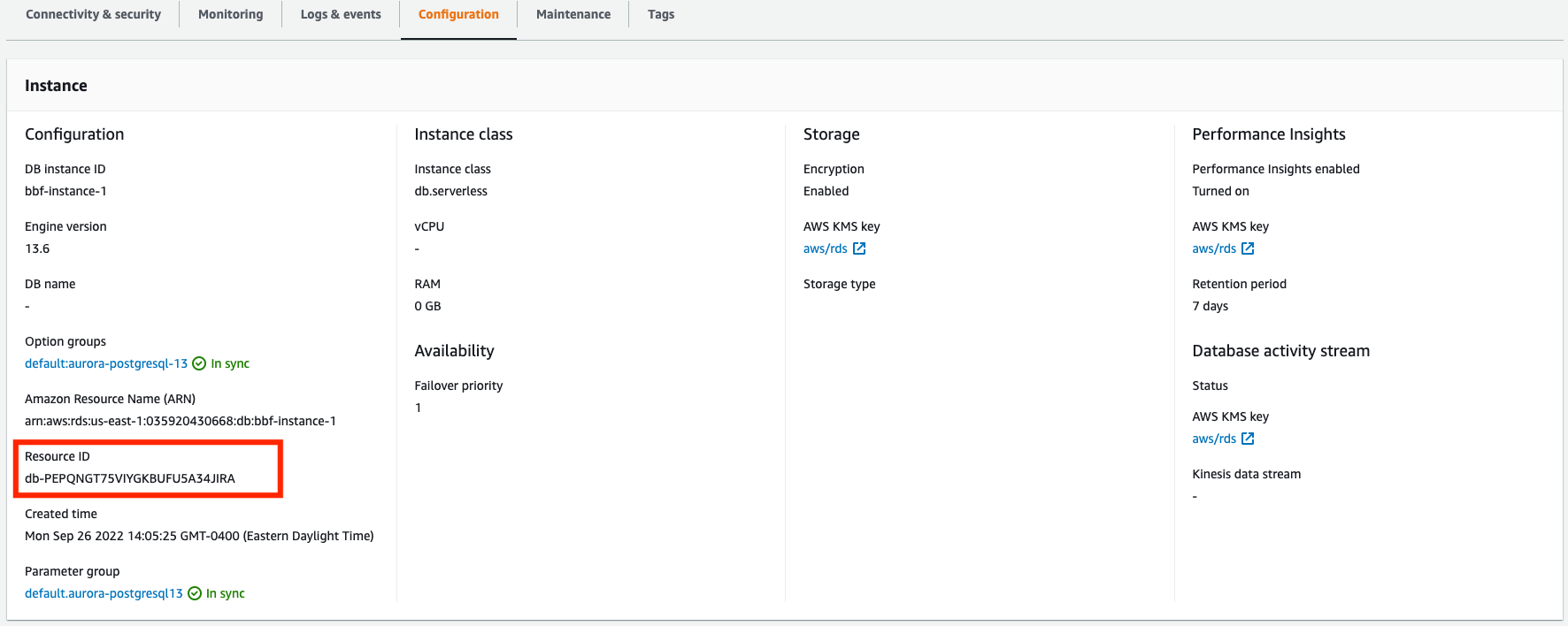
Anda memerlukan ID Sumber Daya instans DB Anda untuk menanyakan Wawasan CloudWatch Log. ID Sumber Daya tersedia di tab Konfigurasi di konsol Anda:
Untuk mengueri file log Anda untuk metrik penyimpanan sumber daya:
Buka CloudWatch konsol di https://console.aws.amazon.com/cloudwatch/
. Halaman beranda CloudWatch ikhtisar muncul.
-
Jika perlu, ubah Wilayah AWS. Di bilah navigasi, pilih Wilayah AWS tempat AWS sumber daya Anda berada. Untuk informasi selengkapnya, lihat Wilayah dan titik akhir.
-
Di panel navigasi, pilih Log, lalu Wawasan Log.
Halaman Wawasan Log muncul.
-
Pilih file log dari daftar tarik-turun untuk menganalisis.
-
Masukkan kueri berikut di bidang, ganti
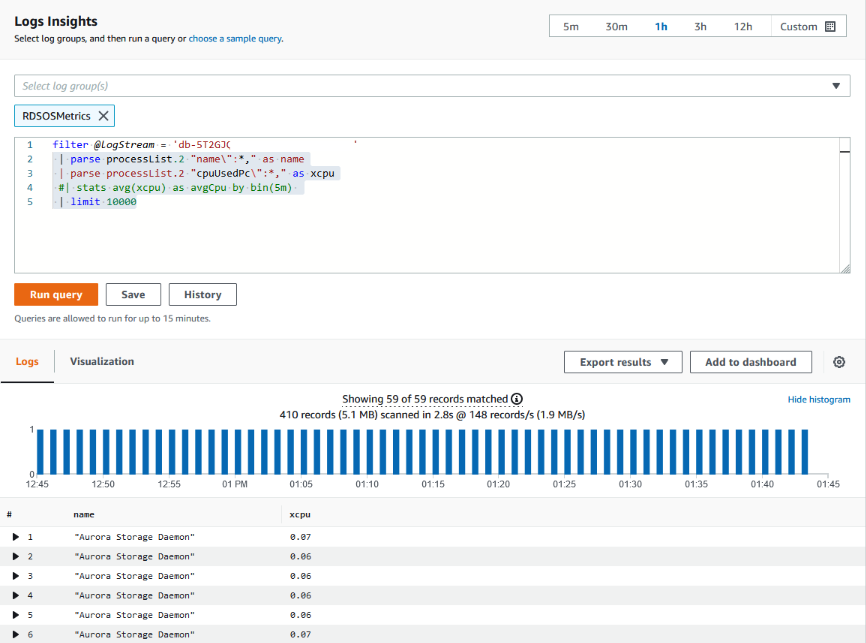
<resource ID>dengan ID sumber daya klaster DB Anda:filter @logStream = <resource ID> | parse @message "\"Aurora Storage Daemon\"*memoryUsedPc\":*,\"cpuUsedPc\":*," as a,memoryUsedPc,cpuUsedPc | display memoryUsedPc,cpuUsedPc #| stats avg(xcpu) as avgCpu by bin(5m) | limit 10000 -
Klik Jalankan kueri.
Grafik pemanfaatan penyimpanan ditampilkan.
Gambar berikut menyediakan halaman Wawasan Log dan tampilan grafik.
Mengevaluasi penggunaan instans DB untuk Aurora CloudWatch PostgreSQL dengan metrik
Anda dapat menggunakan CloudWatch metrik untuk melihat throughput instans dan mengetahui apakah kelas instans menyediakan sumber daya yang memadai untuk aplikasi Anda. Untuk informasi tentang batas kelas instans DB Anda, buka Spesifikasi perangkat keras kelas instans DB untuk Aurora dan cari spesifikasi untuk kelas instans DB Anda guna menemukan performa jaringan.
Jika penggunaan instans DB Anda mendekati batas kelas instans, maka performa mungkin mulai melambat. CloudWatch Metrik dapat mengonfirmasi situasi ini sehingga Anda dapat merencanakan untuk meningkatkan skala secara manual ke kelas instance yang lebih besar.
Gabungkan nilai CloudWatch metrik berikut untuk mengetahui apakah Anda mendekati batas kelas instance:
-
NetworkThroughput— Jumlah throughput jaringan yang diterima dan ditransmisikan oleh klien untuk setiap instance di cluster Aurora DB. Throughput ini tidak mencakup lalu lintas jaringan di antara instans dalam klaster DB dan volume klaster.
-
StorageNetworkThroughput— Jumlah throughput jaringan yang diterima dan dikirim ke subsistem penyimpanan Aurora oleh setiap instance di cluster Aurora DB.
Tambahkan ke NetworkThroughputStorageNetworkThroughputuntuk menemukan throughput jaringan yang diterima dari dan dikirim ke subsistem penyimpanan Aurora oleh setiap instance di cluster Aurora DB Anda. Batas kelas instans untuk instans Anda harus lebih besar dari jumlah kedua metrik gabungan ini.
Anda dapat menggunakan metrik berikut untuk meninjau detail tambahan lalu lintas jaringan dari aplikasi klien Anda saat mengirim dan menerima:
-
NetworkReceiveThroughput— Jumlah throughput jaringan yang diterima dari klien oleh setiap instance di cluster DB PostgreSQL Aurora. Throughput ini tidak mencakup lalu lintas jaringan di antara instans dalam klaster DB dan volume klaster.
-
NetworkTransmitThroughput— Jumlah throughput jaringan yang dikirim ke klien oleh setiap instance di cluster Aurora DB. Throughput ini tidak mencakup lalu lintas jaringan di antara instans dalam klaster DB dan volume klaster.
-
StorageNetworkReceiveThroughput— Jumlah throughput jaringan yang diterima dari subsistem penyimpanan Aurora oleh setiap instance di cluster DB.
-
StorageNetworkTransmitThroughput— Jumlah throughput jaringan yang dikirim ke subsistem penyimpanan Aurora oleh setiap instance di cluster DB.
Tambahkan semua metrik ini bersama-sama untuk mengevaluasi bagaimana penggunaan jaringan Anda dibandingkan dengan batas kelas instans. Batas kelas instans harus lebih besar dari jumlah metrik gabungan ini.
Batas jaringan dan pemanfaatan CPU untuk penyimpanan saling berkaitan. Ketika throughput jaringan meningkat, maka pemanfaatan CPU juga meningkat. Pemantauan penggunaan CPU dan jaringan memberikan informasi tentang bagaimana dan mengapa sumber daya habis.
Untuk membantu meminimalkan penggunaan jaringan, Anda dapat mempertimbangkan:
-
Menggunakan kelas instans yang lebih besar.
-
Menggunakan strategi partisi
pg_partman. -
Membagi permintaan tulis dalam batch untuk mengurangi keseluruhan transaksi.
-
Mengarahkan beban kerja hanya-baca ke instans hanya-baca.
-
Menghapus indeks yang tidak digunakan.
-
Memeriksa objek bloat dan VACUUM. Dalam kasus bloat parah, gunakan ekstensi
pg_repackPostgreSQL. Untuk informasi selengkapnya tentangpg_repack, lihat Menata ulang tabel di basis data PostgreSQL dengan kunci minimal.
