Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Memantau basis data global Amazon Aurora
Ketika Anda membuat klaster DB Aurora yang membentuk basis data global Aurora Anda, Anda dapat memilih banyak pilihan yang memungkinkan Anda memantau performa DB klaster Anda. Opsi ini mencakup hal berikut:
Amazon RDS Performance Insights — Mengaktifkan skema kinerja di mesin basis data Aurora yang mendasarinya. Untuk mempelajari selengkapnya tentang Wawasan Performa dan basis data global Aurora, lihat Memantau database global Amazon Aurora dengan Amazon Performance Insights RDS.
Pemantauan yang disempurnakan — Menghasilkan metrik untuk proses atau pemanfaatan utas pada. CPU Untuk mempelajari tentang pemantauan yang ditingkatkan, lihat Memantau metrik OS dengan Pemantauan yang Ditingkatkan.
Amazon CloudWatch Logs - Menerbitkan jenis log tertentu ke CloudWatch Log. Log kesalahan diterbitkan secara default, tetapi Anda dapat memilih log lain khusus untuk mesin basis data Aurora Anda.
Untuk klaster Aurora DB SQL berbasis Aurora My, Anda dapat mengekspor log audit, log umum, dan log kueri lambat.
Untuk cluster Aurora DB SQL berbasis Aurora Postgre, Anda dapat mengekspor log Postgre. SQL
Untuk database global SQL berbasis Aurora My, Anda dapat menanyakan
information_schematabel tertentu untuk memeriksa status database global Aurora Anda dan instance-nya. Untuk mempelajari caranya, lihat Memantau Aurora SQL Database global berbasis saya.Untuk database global SQL berbasis Aurora Postgre, Anda dapat menggunakan fungsi tertentu untuk memeriksa status database global Aurora Anda dan instance-nya. Untuk mempelajari caranya, lihat Memantau basis data global berbasis Aurora Postgre SQL.
Tangkapan layar berikut menunjukkan beberapa pilihan yang tersedia pada tab Pemantauan klaster DB Aurora primer dalam basis data global Aurora.
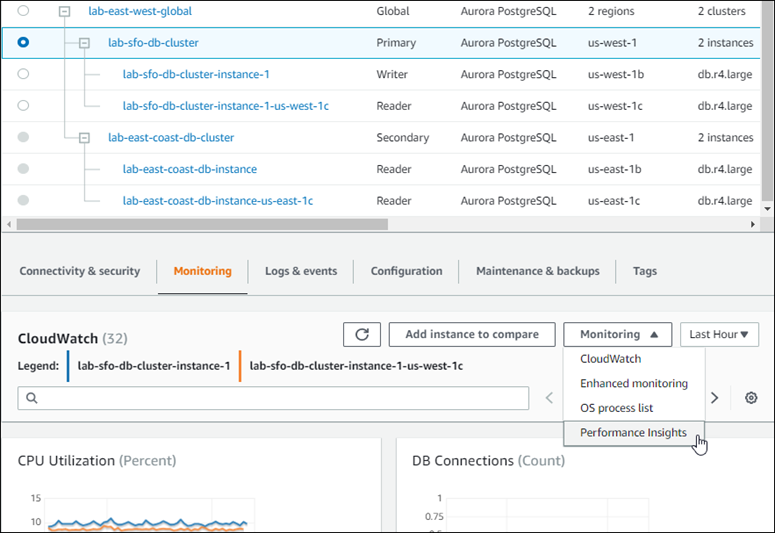
Untuk informasi selengkapnya, lihat Memantau metrik di klaster Amazon Aurora.
Memantau database global Amazon Aurora dengan Amazon Performance Insights RDS
Anda dapat menggunakan Amazon RDS Performance Insights untuk database global Aurora Anda. Anda mengaktifkan fitur ini secara individual, untuk setiap klaster DB Aurora dalam basis data global Aurora Anda. Untuk melakukannya, pilih Aktifkan Wawasan Performa di bagian Konfigurasi tambahan pada halaman Buat basis data. Atau Anda dapat memodifikasi klaster DB Aurora Anda untuk menggunakan fitur ini setelah tersedia dan berjalan. Anda dapat mengaktifkan atau menonaktifkan Wawasan Performa untuk setiap klaster yang merupakan bagian dari basis data global Aurora Anda.
Pernyataan yang dibuat oleh Wawasan Performa berlaku untuk setiap klaster dalam global basis data. Saat Anda menambahkan sekunder baru Wilayah AWS ke database global Aurora yang sudah menggunakan Performance Insights, pastikan Anda mengaktifkan Performance Insights di cluster yang baru ditambahkan. Klaster tersebut tidak mewarisi pengaturan Wawasan Performa dari basis data global yang sudah ada.
Anda dapat beralih Wilayah AWS saat melihat halaman Performance Insights untuk instance DB yang dilampirkan ke database global. Namun, Anda mungkin tidak melihat informasi kinerja segera setelah beralih Wilayah AWS. Meskipun instans DB mungkin memiliki nama yang identik di masing-masing Wilayah AWS, Performance URL Insights terkait berbeda untuk setiap instans DB. Setelah beralih Wilayah AWS, pilih nama instans DB lagi di panel navigasi Performance Insights.
Untuk instans DB yang dikaitkan dengan global basis data, faktor yang memengaruhi performa mungkin berbeda di setiap Wilayah AWS. Misalnya, instans DB di masing-masing Wilayah AWS mungkin memiliki kapasitas yang berbeda.
Untuk mempelajari lebih lanjut tentang menggunakan Wawasan Performa, lihat Memantau beban DB dengan Performance Insights di Amazon Aurora.
Memantau basis data global Aurora dengan Aliran Aktivitas Basis Data
Dengan menggunakan fitur Aliran Aktivitas Basis Data, Anda dapat memantau dan mengatur alarm untuk aktivitas audit di klaster DB di basis data global Anda. Anda memulai aliran aktivitas basis data pada setiap klaster DB secara terpisah. Setiap klaster mengirimkan data audit ke aliran Kinesis-nya sendiri dalam Wilayah AWS-nya sendiri. Untuk informasi selengkapnya, lihat Memantau Aurora dengan Aliran Aktivitas Database.
Memantau Aurora SQL Database global berbasis saya
Untuk melihat status database global SQL berbasis Aurora My, kueri information_schema.aurora_global_db_status dan information_schema.aurora_global_db_instance_status tabel.
catatan
information_schema.aurora_global_db_instance_statusTabel information_schema.aurora_global_db_status dan hanya tersedia dengan Aurora My SQL versi 3.04.0 dan database global yang lebih tinggi.
Untuk memantau basis data global SQL berbasis Aurora My
-
Connect ke endpoint cluster primer database global menggunakan SQL klien Saya. Untuk informasi selengkapnya tentang cara membuat koneksi, lihat Terhubung ke basis data global Amazon Aurora.
-
Lakukan kueri ke tabel
information_schema.aurora_global_db_statusdalam perintah mysql untuk membuat daftar volume primer dan sekunder. Kueri ini memunculkan waktu lag klaster DB sekunder basis data global, seperti pada contoh berikut.mysql> select * from information_schema.aurora_global_db_status;AWS_REGION | HIGHEST_LSN_WRITTEN | DURABILITY_LAG_IN_MILLISECONDS | RPO_LAG_IN_MILLISECONDS | LAST_LAG_CALCULATION_TIMESTAMP | OLDEST_READ_VIEW_TRX_ID -----------+---------------------+--------------------------------+------------------------+---------------------------------+------------------------ us-east-1 | 183537946 | 0 | 0 | 1970-01-01 00:00:00.000000 | 0 us-west-2 | 183537944 | 428 | 0 | 2023-02-18 01:26:41.925000 | 20806982 (2 rows)Output mencakup baris untuk setiap klaster DB basis data global yang berisi kolom berikut:
-
AWS_ REGION — Di Wilayah AWS mana cluster DB ini berada. Untuk daftar tabel Wilayah AWS berdasarkan mesin, lihat Wilayah dan Zona Ketersediaan.
-
HIGHEST_ LSN _ WRITTEN — Nomor urutan log tertinggi (LSN) yang saat ini ditulis di cluster DB ini.
Nomor urutan log (LSN) adalah nomor urut unik yang mengidentifikasi catatan dalam log transaksi database. LSNsdipesan sedemikian rupa sehingga yang lebih besar LSN mewakili transaksi selanjutnya.
-
DURABILITY_ LAG _IN_ MILLISECONDS — Perbedaan nilai stempel waktu antara
HIGHEST_LSN_WRITTENpada cluster DB sekunder danHIGHEST_LSN_WRITTENpada cluster DB primer. Nilai ini selalu 0 pada klaster DB primer basis data global Aurora. -
RPO_ LAG _IN_ MILLISECONDS — Tujuan titik pemulihan (RPO) tertinggal. RPOKelambatan adalah waktu yang dibutuhkan untuk transaksi pengguna terbaru COMMIT untuk disimpan di cluster DB sekunder setelah disimpan di cluster DB utama dari database global Aurora. Nilai ini selalu 0 pada klaster DB primer basis data global Aurora.
Secara sederhana, metrik ini menghitung tujuan titik pemulihan untuk setiap cluster Aurora SQL My DB di database global Aurora, yaitu, berapa banyak data yang mungkin hilang jika ada pemadaman. Seperti halnya lag, RPO diukur dalam waktu.
-
LAST_ LAG _ CALCULATION _ TIMESTAMP — Stempel waktu yang menentukan kapan nilai terakhir dihitung untuk dan.
DURABILITY_LAG_IN_MILLISECONDSRPO_LAG_IN_MILLISECONDSNilai waktu seperti1970-01-01 00:00:00+00berarti ini adalah klaster DB primer. -
OLDEST_ READ _ VIEW _ TRX _ID — ID transaksi tertua yang dapat dibersihkan oleh instans DB penulis.
-
-
Lakukan kueri ke tabel
information_schema.aurora_global_db_instance_statusuntuk membuat daftar semua instans DB sekunder baik untuk klaster DB primer maupun klaster DB sekunder.mysql> select * from information_schema.aurora_global_db_instance_status;SERVER_ID | SESSION_ID | AWS_REGION | DURABLE_LSN | HIGHEST_LSN_RECEIVED | OLDEST_READ_VIEW_TRX_ID | OLDEST_READ_VIEW_LSN | VISIBILITY_LAG_IN_MSEC ---------------------+--------------------------------------+------------+-------------+----------------------+-------------------------+----------------------+------------------------ ams-gdb-primary-i2 | MASTER_SESSION_ID | us-east-1 | 183537698 | 0 | 0 | 0 | 0 ams-gdb-secondary-i1 | cc43165b-bdc6-4651-abbf-4f74f08bf931 | us-west-2 | 183537689 | 183537692 | 20806928 | 183537682 | 0 ams-gdb-secondary-i2 | 53303ff0-70b5-411f-bc86-28d7a53f8c19 | us-west-2 | 183537689 | 183537692 | 20806928 | 183537682 | 677 ams-gdb-primary-i1 | 5af1e20f-43db-421f-9f0d-2b92774c7d02 | us-east-1 | 183537697 | 183537698 | 20806930 | 183537691 | 21 (4 rows)Output mencakup baris untuk setiap instans DB basis data global yang berisi kolom berikut:
-
SERVER_ID — Pengidentifikasi server untuk instance DB.
-
SESSION_ID — Pengenal unik untuk sesi saat ini. Nilai
MASTER_SESSION_IDmengidentifikasi instans DB Penulis (primer). -
AWS_ REGION — Di Wilayah AWS mana instans DB ini berada. Untuk daftar tabel Wilayah AWS berdasarkan mesin, lihat Wilayah dan Zona Ketersediaan.
-
DURABLE_ LSN — LSN Dibuat tahan lama dalam penyimpanan.
-
HIGHEST_ LSN _ RECEIVED — Tertinggi yang LSN diterima oleh instans DB dari instans DB penulis.
-
OLDEST_ READ _ VIEW _ TRX _ID — ID transaksi tertua yang dapat dibersihkan oleh instans DB penulis.
-
OLDEST_ READ _ VIEW _ LSN — Yang tertua LSN digunakan oleh instans DB untuk membaca dari penyimpanan.
-
VISIBILITY_ LAG _IN_ MSEC — Untuk pembaca di cluster DB primer, seberapa jauh instance DB ini tertinggal dari instance DB penulis dalam milidetik. Untuk pembaca di DB klaster sekunder, seberapa jauh DB instans ini tetap tertinggal di belakang volume sekunder dalam milidetik.
-
Untuk melihat perubahan nilai ini dari waktu ke waktu, pertimbangkan blok transaksi berikut di mana sisipan tabel memakan waktu satu jam.
mysql> BEGIN;
mysql> INSERT INTO table1 SELECT Large_Data_That_Takes_1_Hr_To_Insert;
mysql> COMMIT;Dalam beberapa kasus, mungkin terdapat pemutusan jaringan antara klaster DB primer dan klaster DB sekunder setelah pernyataan BEGIN. Jika demikian, MILLISECONDS nilai DURABILITY_ LAG _IN_ cluster DB sekunder mulai meningkat. Di akhir INSERT pernyataan, MILLISECONDS nilai DURABILITY_ LAG _IN_ adalah 1 jam. Namun, MILLISECONDS nilai RPO_ LAG _IN_ adalah 0 karena semua data pengguna yang dilakukan antara cluster DB primer dan cluster DB sekunder masih sama. Segera setelah COMMIT pernyataan selesai, nilai RPO_ LAG _IN_ meningkat MILLISECONDS.
Memantau basis data global berbasis Aurora Postgre SQL
Untuk melihat status database global SQL berbasis Aurora Postgre, gunakan dan fungsi. aurora_global_db_status aurora_global_db_instance_status
catatan
Hanya Aurora Postgre yang SQL mendukung dan fungsi. aurora_global_db_status aurora_global_db_instance_status
Untuk memantau basis data global berbasis Aurora Postgre SQL
-
Connect ke endpoint cluster primer database global menggunakan SQL utilitas Postgre seperti psql. Untuk informasi selengkapnya tentang cara membuat koneksi, lihat Terhubung ke basis data global Amazon Aurora.
-
Gunakan fungsi
aurora_global_db_statusdalam perintah psql untuk mencantumkan volume primer dan sekunder. Ini menunjukkan waktu lag klaster DB sekunder global basis data.postgres=> select * from aurora_global_db_status();aws_region | highest_lsn_written | durability_lag_in_msec | rpo_lag_in_msec | last_lag_calculation_time | feedback_epoch | feedback_xmin ------------+---------------------+------------------------+-----------------+----------------------------+----------------+--------------- us-east-1 | 93763984222 | -1 | -1 | 1970-01-01 00:00:00+00 | 0 | 0 us-west-2 | 93763984222 | 900 | 1090 | 2020-05-12 22:49:14.328+00 | 2 | 3315479243 (2 rows)Output mencakup baris untuk setiap klaster DB basis data global yang berisi kolom berikut:
-
aws_region - Tempat cluster DB ini berada Wilayah AWS . Untuk daftar tabel Wilayah AWS berdasarkan mesin, lihat Wilayah dan Zona Ketersediaan.
-
highest_lsn_written — Nomor urutan log tertinggi (LSN) saat ini ditulis pada cluster DB ini.
Nomor urutan log (LSN) adalah nomor urut unik yang mengidentifikasi catatan dalam log transaksi database. LSNsdipesan sedemikian rupa sehingga yang lebih besar LSN mewakili transaksi selanjutnya.
-
durability_lag_in_msec – Perbedaan stempel waktu antara log sequence number tertinggi pada klaster DB sekunder (
highest_lsn_written) danhighest_lsn_writtenpada klaster DB primer. -
rpo_lag_in_msec — Tujuan titik pemulihan () lag. RPO Lag ini adalah perbedaan waktu antara transaksi pengguna terbaru yang disimpan di DB klaster sekunder dan transaksi pengguna terbaru yang disimpan di DB klaster primer.
-
last_lag_calculation_time – Stempel waktu ketika nilai terakhir dihitung untuk
durability_lag_in_msecdanrpo_lag_in_msec. -
feedback_epoch – Masa yang digunakan klaster DB sekunder saat menghasilkan informasi hot standby.
Hot standby adalah ketika klaster DB dapat terhubung dan mengueri saat server berada dalam mode pemulihan atau mode siaga. Umpan balik hot standby adalah informasi tentang klaster DB saat dalam status hot standby. Untuk informasi selengkapnya, lihat Siaga panas di dokumentasi
SQL Postgre. -
feedback_xmin – ID transaksi aktif minimum (terlama) yang digunakan oleh klaster DB sekunder.
-
-
Gunakan fungsi
aurora_global_db_instance_statusuntuk membuat daftar semua instans DB sekunder baik untuk klaster DB primer maupun klaster DB sekunder.postgres=> select * from aurora_global_db_instance_status();server_id | session_id | aws_region | durable_lsn | highest_lsn_rcvd | feedback_epoch | feedback_xmin | oldest_read_view_lsn | visibility_lag_in_msec --------------------------------------------+--------------------------------------+------------+-------------+------------------+----------------+---------------+----------------------+------------------------ apg-global-db-rpo-mammothrw-elephantro-1-n1 | MASTER_SESSION_ID | us-east-1 | 93763985102 | | | | | apg-global-db-rpo-mammothrw-elephantro-1-n2 | f38430cf-6576-479a-b296-dc06b1b1964a | us-east-1 | 93763985099 | 93763985102 | 2 | 3315479243 | 93763985095 | 10 apg-global-db-rpo-elephantro-mammothrw-n1 | 0d9f1d98-04ad-4aa4-8fdd-e08674cbbbfe | us-west-2 | 93763985095 | 93763985099 | 2 | 3315479243 | 93763985089 | 1017 (3 rows)Output mencakup baris untuk setiap instans DB basis data global yang berisi kolom berikut:
-
server_id – Pengidentifikasi server untuk instans DB.
-
session_id – Pengidentifikasi unik untuk sesi saat ini.
-
aws_region — Wilayah AWS Instance DB ini berada. Untuk daftar tabel Wilayah AWS berdasarkan mesin, lihat Wilayah dan Zona Ketersediaan.
-
durable_lsn — Dibuat tahan lama dalam penyimpanan. LSN
-
highest_lsn_rcvd — Tertinggi yang LSN diterima oleh instans DB dari instance DB penulis.
-
feedback_epoch – Masa yang digunakan instans DB saat menghasilkan informasi hot standby.
Hot standby adalah ketika instans DB dapat terhubung dan mengueri saat server berada dalam mode pemulihan atau mode siaga. Umpan balik hot standby adalah informasi tentang instans DB saat dalam status hot standby. Untuk informasi selengkapnya, lihat SQL dokumentasi Postgre di Hot
standby. -
feedback_xmin – ID transaksi aktif minimum (terlama) yang digunakan oleh instans DB.
-
oldest_read_view_lsn — Yang tertua LSN digunakan oleh instans DB untuk membaca dari penyimpanan.
-
visibility_lag_in_msec – Seberapa jauh instans DB ini tertinggal di belakang instans DB penulis.
-
Untuk melihat perubahan nilai ini dari waktu ke waktu, pertimbangkan blok transaksi berikut di mana sisipan tabel memakan waktu satu jam.
psql> BEGIN;
psql> INSERT INTO table1 SELECT Large_Data_That_Takes_1_Hr_To_Insert;
psql> COMMIT;Dalam beberapa kasus, mungkin terdapat pemutusan jaringan antara klaster DB primer dan klaster DB sekunder setelah pernyataan BEGIN. Jika ya, nilai durability_lag_in_msec klaster DB sekunder mulai meningkat. Pada akhir pernyataan INSERT, nilai durability_lag_in_msec adalah 1 jam. Namun, nilai rpo_lag_in_msec adalah 0 karena semua data pengguna yang di-commit antara klaster DB primer dan klaster DB sekunder masih sama. Segera setelah pernyataan COMMIT selesai, nilai rpo_lag_in_msec akan meningkat.
