Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Pola bucket tujuan umum umum untuk membangun aplikasi di Amazon S3
Saat membuat aplikasi di Amazon S3, Anda dapat menggunakan bucket tujuan umum yang unik untuk memisahkan kumpulan data atau beban kerja yang berbeda. Saat Anda membuat aplikasi yang melayani pengguna akhir atau grup pengguna yang berbeda, gunakan pola desain praktik terbaik kami untuk membangun aplikasi yang dapat memanfaatkan fitur dan skalabilitas Amazon S3 dengan sebaik-baiknya.
penting
Kami menyarankan Anda membuat nama bucket tujuan umum yang tidak dapat diprediksi. Jangan menulis kode dengan asumsi nama bucket pilihan Anda tersedia kecuali Anda telah membuat bucket. Sebaiknya buat bucket di namespace regional akun Anda untuk memastikan bahwa hanya akun Anda yang dapat memiliki nama bucket ini, lihat. Ruang nama untuk ember tujuan umum Untuk informasi selengkapnya tentang aturan penamaan bucket tujuan umum, lihatAturan penamaan bucket tujuan umum.
Multi-tenant pola ember tujuan umum
Dengan bucket multi-tenant, Anda membuat satu bucket tujuan umum untuk tim atau beban kerja. Anda menggunakan awalan S3 unik untuk mengatur objek yang Anda simpan di ember. Prefiks adalah string karakter di bagian awal nama kunci objek. Prefiks dapat memiliki panjang berapa pun, tergantung pada panjang maksimum dari nama kunci objek (1.024 byte). Anda dapat menganggap prefiks sebagai cara untuk mengatur data Anda dengan cara yang mirip dengan direktori. Namun, prefiks bukan direktori.
Misalnya, untuk menyimpan informasi tentang kota, Anda dapat mengaturnya berdasarkan benua, lalu berdasarkan negara, lalu berdasarkan provinsi atau negara bagian. Karena nama-nama ini biasanya tidak mengandung tanda baca, Anda dapat menggunakan garis miring (/) sebagai pembatas. Contoh berikut menunjukkan awalan yang digunakan untuk mengatur nama kota berdasarkan benua, negara, dan kemudian provinsi atau negara bagian, menggunakan pembatas garis miring (/).
-
Europe/France/NouvelleA-Aquitaine/Bordeaux
-
Utara America/Canada/Quebec/Montreal
-
Utara America/USA/Washington/Bellevue
-
Utara America/USA/Washington/Seattle
Pola ini berskala baik ketika Anda memiliki ratusan kumpulan data unik dalam ember tujuan umum. Dengan awalan, Anda dapat dengan mudah mengatur dan mengelompokkan kumpulan data ini.
Namun, satu kelemahan potensial pada pola bucket tujuan umum multi-tenant adalah bahwa banyak fitur tingkat ember S3 seperti enkripsi bucket default, S3 Versioning, dan S3 Requester Pays ditetapkan pada tingkat ember dan bukan level awalan. Jika kumpulan data yang berbeda dalam bucket multi-tenant memiliki persyaratan unik, fakta bahwa Anda tidak dapat mengonfigurasi banyak fitur tingkat ember S3 di tingkat awalan dapat menyulitkan Anda untuk menentukan pengaturan yang benar untuk setiap kumpulan data. Selain itu, dalam bucket multi-tenant, alokasi biaya dapat menjadi kompleks saat Anda bekerja untuk memahami penyimpanan, permintaan, dan transfer data yang terkait dengan awalan tertentu.
Bucket-per-use pola
Dengan pola bucket-per-use, Anda membuat bucket tujuan umum untuk setiap kumpulan data, pengguna akhir, atau tim yang berbeda. Karena Anda dapat mengonfigurasi fitur tingkat ember S3 untuk masing-masing bucket ini, Anda dapat menggunakan pola ini untuk mengonfigurasi pengaturan tingkat ember yang unik. Misalnya, Anda dapat mengonfigurasi fitur seperti enkripsi bucket default, S3 Versioning, dan S3 Requester Pays dengan cara yang disesuaikan dengan kumpulan data di setiap bucket. Menggunakan satu bucket untuk setiap kumpulan data, pengguna akhir, atau tim yang berbeda juga dapat membantu Anda menyederhanakan manajemen akses dan strategi alokasi biaya.
Kelemahan potensial dari strategi ini adalah Anda perlu mengelola ribuan ember yang berpotensi. Semua Akun AWS memiliki kuota default 10.000 bucket tujuan umum. Anda dapat menambah kuota bucket untuk akun dengan mengirimkan permintaan kenaikan kuota. Untuk meminta peningkatan bucket tujuan umum, kunjungi konsol Service Quotas
Untuk mengelola pola bucket-per-use Anda dan menyederhanakan manajemen infrastruktur Anda, Anda dapat menggunakannya. AWS CloudFormation Anda dapat membuat CloudFormation template khusus untuk pola Anda yang sudah mendefinisikan semua pengaturan yang Anda inginkan untuk bucket tujuan umum S3 Anda sehingga Anda dapat dengan mudah menerapkan dan melacak setiap perubahan pada infrastruktur Anda. Untuk informasi selengkapnya, lihat AWS: :S3: :Bucket di Panduan Pengguna.AWS CloudFormation
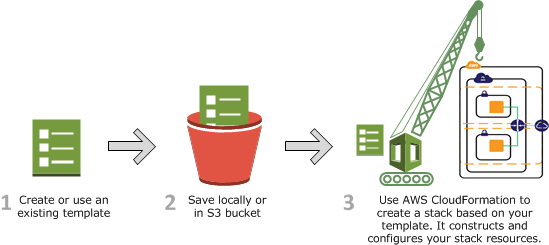
Saat membuat beban kerja dengan pola bucket-per-use, sebaiknya Anda membuat bucket di namespace regional akun Anda. Dengan membuat bucket di namespace regional akun Anda, Anda menghindari persaingan untuk nama bucket dengan yang lain dan memiliki jaminan bahwa hanya akun Anda yang dapat membuat bucket dengan konvensi penamaan yang Anda pilih. Untuk informasi selengkapnya tentang ruang nama regional akun, lihat. Ruang nama untuk ember tujuan umum
