Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
ParameterEXPLAINpernyataan menunjukkan rencana eksekusi logis atau didistribusikan dari pernyataan SQL tertentu, atau memvalidasi pernyataan SQL. Anda dapat menampilkan hasil dalam format teks atau dalam format data untuk rendering ke grafik.
catatan
Anda dapat melihat representasi grafis dari rencana logis dan terdistribusi untuk kueri Anda di konsol Athena tanpa menggunakan sintaks. EXPLAIN Untuk informasi selengkapnya, lihat Lihat rencana eksekusi untuk SQL kueri.
EXPLAIN ANALYZEPernyataan tersebut menunjukkan rencana eksekusi terdistribusi dari pernyataan SQL tertentu dan biaya komputasi setiap operasi dalam kueri SQL. Anda dapat menampilkan hasil dalam format teks atau JSON.
Pertimbangan dan batasan
EXPLAIN ANALYZEPernyataan EXPLAIN dan di Athena memiliki batasan sebagai berikut.
-
Karena
EXPLAINpertanyaan tidak memindai data apapun, Athena tidak mengenakan biaya untuk mereka. Namun, karenaEXPLAINkueri melakukan panggilan AWS Glue untuk mengambil metadata tabel, Anda mungkin dikenakan biaya dari Glue jika panggilan melebihi batas tingkat gratis untuklem. -
Karena
EXPLAIN ANALYZEkueri dijalankan, mereka memindai data, dan Athena mengenakan biaya untuk jumlah data yang dipindai. -
Informasi pemfilteran baris atau sel yang ditentukan dalam Lake Formation dan informasi statistik kueri tidak ditampilkan dalam output dan.
EXPLAINEXPLAIN ANALYZE
JELASKAN sintaks
EXPLAIN [ (option[, ...]) ]statement
option dapat berupa salah satu status berikut:
FORMAT { TEXT | GRAPHVIZ | JSON }
TYPE { LOGICAL | DISTRIBUTED | VALIDATE | IO }Jika FORMAT opsi tidak ditentukan, output default ke format. TEXT IOJenis ini memberikan informasi tentang tabel dan skema yang dibaca kueri.
JELASKAN ANALYSIS sintaks
Selain output yang disertakanEXPLAIN, EXPLAIN
ANALYZE output juga mencakup statistik runtime untuk kueri yang ditentukan seperti penggunaan CPU, jumlah baris input, dan jumlah baris output.
EXPLAIN ANALYZE [ (option[, ...]) ]statement
option dapat berupa salah satu status berikut:
FORMAT { TEXT | JSON }Jika FORMAT opsi tidak ditentukan, output default ke format. TEXT Karena semua kueri untuk EXPLAIN ANALYZE adalahDISTRIBUTED, TYPE opsi tidak tersedia untukEXPLAIN ANALYZE.
statement dapat berupa salah satu status berikut:
SELECT CREATE TABLE AS SELECT INSERT UNLOAD
JELASKAN contoh
Contoh berikut untuk EXPLAIN kemajuan dari yang lebih mudah ke yang lebih kompleks.
Dalam contoh berikut, EXPLAIN menunjukkan rencana eksekusi untuk SELECT kueri pada log Elastic Load Balancing. Format default ke output teks.
EXPLAIN
SELECT
request_timestamp,
elb_name,
request_ip
FROM sampledb.elb_logs;Hasil
- Output[request_timestamp, elb_name, request_ip] => [[request_timestamp, elb_name, request_ip]]
- RemoteExchange[GATHER] => [[request_timestamp, elb_name, request_ip]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=sampledb, tableName=elb_logs,
analyzePartitionValues=Optional.empty}] => [[request_timestamp, elb_name, request_ip]]
LAYOUT: sampledb.elb_logs
request_ip := request_ip:string:2:REGULAR
request_timestamp := request_timestamp:string:0:REGULAR
elb_name := elb_name:string:1:REGULARAnda dapat menggunakan konsol Athena untuk membuat grafik rencana kueri untuk Anda. Masukkan SELECT pernyataan seperti berikut ini ke dalam editor kueri Athena, lalu pilih JELASKAN.
SELECT
c.c_custkey,
o.o_orderkey,
o.o_orderstatus
FROM tpch100.customer c
JOIN tpch100.orders o
ON c.c_custkey = o.o_custkey Halaman Jelaskan editor kueri Athena terbuka dan menunjukkan kepada Anda rencana terdistribusi dan rencana logis untuk kueri tersebut. Grafik berikut menunjukkan rencana logis untuk contoh.
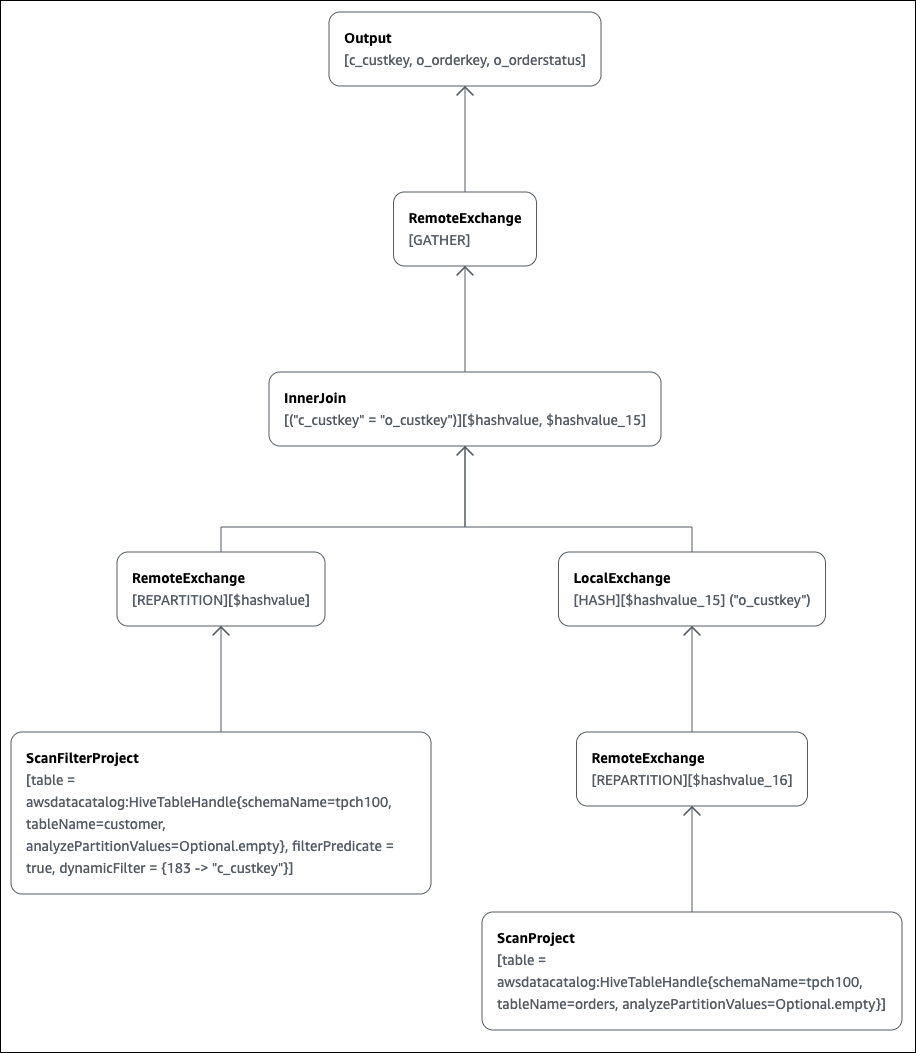
penting
Saat ini, beberapa filter partisi mungkin tidak terlihat di grafik pohon operator bersarang meskipun Athena menerapkannya ke kueri Anda. Untuk memverifikasi efek filter tersebut, jalankan EXPLAIN atau EXPLAIN
ANALYZE pada kueri Anda dan lihat hasilnya.
Untuk informasi selengkapnya tentang menggunakan fitur grafik paket kueri di konsol Athena, lihat. Lihat rencana eksekusi untuk SQL kueri
Anda dapat menggunakan konsol Athena untuk membuat grafik rencana kueri untuk Anda. Masukkan SELECT pernyataan seperti berikut ini ke dalam editor kueri Athena, lalu pilih JELASKAN.
SELECT
c.c_custkey,
o.o_orderkey,
o.o_orderstatus
FROM tpch100.customer c
JOIN tpch100.orders o
ON c.c_custkey = o.o_custkey Halaman Jelaskan editor kueri Athena terbuka dan menunjukkan kepada Anda rencana terdistribusi dan rencana logis untuk kueri tersebut. Grafik berikut menunjukkan rencana logis untuk contoh.
penting
Saat ini, beberapa filter partisi mungkin tidak terlihat di grafik pohon operator bersarang meskipun Athena menerapkannya ke kueri Anda. Untuk memverifikasi efek filter tersebut, jalankan EXPLAIN atau EXPLAIN
ANALYZE pada kueri Anda dan lihat hasilnya.
Untuk informasi selengkapnya tentang menggunakan fitur grafik paket kueri di konsol Athena, lihat. Lihat rencana eksekusi untuk SQL kueri
Saat Anda menggunakan predikat penyaringan pada bukti kunci dipartisi untuk kueri tabel dipartisi, mesin permintaan berlaku predikat untuk bukti kunci dipartisi untuk mengurangi jumlah data yang dibaca.
Contoh berikut menggunakanEXPLAINquery untuk memverifikasi partisi pemangkasan untukSELECTquery pada tabel dipartisi. Pertama,CREATE TABLEpernyataan menciptakantpch100.orders_partitionedtabel. Tabel dipartisi pada kolomo_orderdate.
CREATE TABLE `tpch100.orders_partitioned`(
`o_orderkey` int,
`o_custkey` int,
`o_orderstatus` string,
`o_totalprice` double,
`o_orderpriority` string,
`o_clerk` string,
`o_shippriority` int,
`o_comment` string)
PARTITIONED BY (
`o_orderdate` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://amzn-s3-demo-bucket/<your_directory_path>/'Parametertpch100.orders_partitionedtabel memiliki beberapa partisi padao_orderdate, seperti yang ditunjukkan olehSHOW PARTITIONSPerintah.
SHOW PARTITIONS tpch100.orders_partitioned;
o_orderdate=1994
o_orderdate=2015
o_orderdate=1998
o_orderdate=1995
o_orderdate=1993
o_orderdate=1997
o_orderdate=1992
o_orderdate=1996BerikutEXPLAINquery memverifikasi partisi pemangkasan pada ditentukanSELECT.
EXPLAIN
SELECT
o_orderkey,
o_custkey,
o_orderdate
FROM tpch100.orders_partitioned
WHERE o_orderdate = '1995'Hasil
Query Plan
- Output[o_orderkey, o_custkey, o_orderdate] => [[o_orderkey, o_custkey, o_orderdate]]
- RemoteExchange[GATHER] => [[o_orderkey, o_custkey, o_orderdate]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=tpch100, tableName=orders_partitioned,
analyzePartitionValues=Optional.empty}] => [[o_orderkey, o_custkey, o_orderdate]]
LAYOUT: tpch100.orders_partitioned
o_orderdate := o_orderdate:string:-1:PARTITION_KEY
:: [[1995]]
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULARTeks tebal dalam hasil menunjukkan bahwa predikato_orderdate =
'1995'diterapkan padaPARTITION_KEY.
BerikutEXPLAINmemeriksa kueriSELECTperintah bergabung pernyataan dan bergabung jenis. Gunakan kueri seperti ini untuk memeriksa penggunaan memori kueri sehingga Anda dapat mengurangi kemungkinan mendapatkanEXCEEDED_LOCAL_MEMORY_LIMITkesalahan.
EXPLAIN (TYPE DISTRIBUTED)
SELECT
c.c_custkey,
o.o_orderkey,
o.o_orderstatus
FROM tpch100.customer c
JOIN tpch100.orders o
ON c.c_custkey = o.o_custkey
WHERE c.c_custkey = 123Hasil
Query Plan
Fragment 0 [SINGLE]
Output layout: [c_custkey, o_orderkey, o_orderstatus]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- Output[c_custkey, o_orderkey, o_orderstatus] => [[c_custkey, o_orderkey, o_orderstatus]]
- RemoteSource[1] => [[c_custkey, o_orderstatus, o_orderkey]]
Fragment 1 [SOURCE]
Output layout: [c_custkey, o_orderstatus, o_orderkey]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- CrossJoin => [[c_custkey, o_orderstatus, o_orderkey]]
Distribution: REPLICATED
- ScanFilter[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("c_custkey" = 123)] => [[c_custkey]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
- LocalExchange[SINGLE] () => [[o_orderstatus, o_orderkey]]
- RemoteSource[2] => [[o_orderstatus, o_orderkey]]
Fragment 2 [SOURCE]
Output layout: [o_orderstatus, o_orderkey]
Output partitioning: BROADCAST []
Stage Execution Strategy: UNGROUPED_EXECUTION
- ScanFilterProject[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=orders, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("o_custkey" = 123)] => [[o_orderstatus, o_orderkey]]
LAYOUT: tpch100.orders
o_orderstatus := o_orderstatus:string:2:REGULAR
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULARContoh kueri dioptimalkan menjadi silang bergabung untuk performa yang lebih baik. Hasil menunjukkan bahwatpch100.ordersakan didistribusikan sebagaiBROADCASTdistribusi jenis. Ini berarti bahwatpch100.orderstabel akan didistribusikan ke semua simpul yang melakukan operasi bergabung. ParameterBROADCASTjenis distribusi akan mengharuskan semua hasil disaring daritpch100.orderstabel masuk ke dalam memori dari setiap simpul yang melakukan bergabung operasi.
Namun,tpch100.customertabel lebih kecil daritpch100.orders. Karenatpch100.customermembutuhkan lebih sedikit memori, Anda dapat menulis ulang kueri keBROADCAST
tpch100.customerSebagai gantinyatpch100.orders. Ini mengurangi kemungkinan kueri menerimaEXCEEDED_LOCAL_MEMORY_LIMITkesalahan. Strategi ini mengasumsikan poin-poin berikut:
-
Parameter
tpch100.customer.c_custkeyunik ditpch100.customertabel. -
Ada hubungan one-to-many pemetaan antara
tpch100.customerdantpch100.orders.
Contoh berikut menunjukkan kueri ditulis ulang.
SELECT
c.c_custkey,
o.o_orderkey,
o.o_orderstatus
FROM tpch100.orders o
JOIN tpch100.customer c -- the filtered results of tpch100.customer are distributed to all nodes.
ON c.c_custkey = o.o_custkey
WHERE c.c_custkey = 123Anda dapat menggunakanEXPLAINquery untuk memeriksa efektivitas penyaringan predikat. Anda dapat menggunakan hasil untuk menghapus predikat yang tidak berpengaruh, seperti dalam contoh berikut.
EXPLAIN
SELECT
c.c_name
FROM tpch100.customer c
WHERE c.c_custkey = CAST(RANDOM() * 1000 AS INT)
AND c.c_custkey BETWEEN 1000 AND 2000
AND c.c_custkey = 1500Hasil
Query Plan
- Output[c_name] => [[c_name]]
- RemoteExchange[GATHER] => [[c_name]]
- ScanFilterProject[table =
awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty},
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" =
CAST(("random"() * 1E3) AS int)))] => [[c_name]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
c_name := c_name:string:1:REGULARParameterfilterPredicatedalam hasil menunjukkan bahwa optimizer menggabungkan tiga predikat asli menjadi dua predikat dan mengubah urutan aplikasi mereka.
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" = CAST(("random"() * 1E3) AS int)))
Karena hasil menunjukkan bahwa predikatAND c.c_custkey BETWEEN
1000 AND 2000tidak berpengaruh, Anda dapat menghapus predikat ini tanpa mengubah hasil kueri.
Untuk informasi tentang istilah yang digunakan dalam hasilEXPLAINkueri, lihatMemahami hasil pernyataan Athena EXPLAIN.
JELASKAN CONTOH ANALISIS
Contoh berikut menunjukkan contoh EXPLAIN ANALYZE query dan output.
Dalam contoh berikut, EXPLAIN ANALYZE menunjukkan rencana eksekusi dan biaya komputasi untuk SELECT kueri pada CloudFront log. Format default ke output teks.
EXPLAIN ANALYZE SELECT FROM cloudfront_logs LIMIT 10Hasil
Fragment 1
CPU: 24.60ms, Input: 10 rows (1.48kB); per task: std.dev.: 0.00, Output: 10 rows (1.48kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer,\
os, browser, browserversion]
Limit[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 10.00 rows, Input std.dev.: 0.00%
LocalExchange[SINGLE] () => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 0.00ns (0.00%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
RemoteSource[2] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
Fragment 2
CPU: 3.83s, Input: 998 rows (147.21kB); per task: std.dev.: 0.00, Output: 20 rows (2.95kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]
LimitPartial[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 5.00ms (0.13%), Output: 20 rows (2.95kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
TableScan[awsdatacatalog:HiveTableHandle{schemaName=default, tableName=cloudfront_logs,\
analyzePartitionValues=Optional.empty},
grouped = false] => [[date, time, location, bytes, requestip, method, host, uri, st
CPU: 3.82s (99.82%), Output: 998 rows (147.21kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
LAYOUT: default.cloudfront_logs
date := date:date:0:REGULAR
referrer := referrer:string:9:REGULAR
os := os:string:10:REGULAR
method := method:string:5:REGULAR
bytes := bytes:int:3:REGULAR
browser := browser:string:11:REGULAR
host := host:string:6:REGULAR
requestip := requestip:string:4:REGULAR
location := location:string:2:REGULAR
time := time:string:1:REGULAR
uri := uri:string:7:REGULAR
browserversion := browserversion:string:12:REGULAR
status := status:int:8:REGULARContoh berikut menunjukkan rencana eksekusi dan biaya komputasi untuk SELECT kueri pada CloudFront log. Contoh menentukan JSON sebagai format output.
EXPLAIN ANALYZE (FORMAT JSON) SELECT * FROM cloudfront_logs LIMIT 10Hasil
{
"fragments": [{
"id": "1",
"stageStats": {
"totalCpuTime": "3.31ms",
"inputRows": "10 rows",
"inputDataSize": "1514B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host,\
uri, status, referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "Limit",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 10.0,
"nodeInputRowsStdDev": 0.0
}]
},
"children": [{
"name": "LocalExchange",
"identifier": "[SINGLE] ()",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": [{
"name": "RemoteSource",
"identifier": "[2]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": []
}]
}]
}]
}
}, {
"id": "2",
"stageStats": {
"totalCpuTime": "1.62s",
"inputRows": "500 rows",
"inputDataSize": "75564B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host, uri, status,\
referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "LimitPartial",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": [{
"name": "TableScan",
"identifier": "[awsdatacatalog:HiveTableHandle{schemaName=default,\
tableName=cloudfront_logs, analyzePartitionValues=Optional.empty},\
grouped = false]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "LAYOUT: default.cloudfront_logs\ndate := date:date:0:REGULAR\nreferrer :=\
referrer: string:9:REGULAR\nos := os:string:10:REGULAR\nmethod := method:string:5:\
REGULAR\nbytes := bytes:int:3:REGULAR\nbrowser := browser:string:11:REGULAR\nhost :=\
host:string:6:REGULAR\nrequestip := requestip:string:4:REGULAR\nlocation :=\
location:string:2:REGULAR\ntime := time:string:1: REGULAR\nuri := uri:string:7:\
REGULAR\nbrowserversion := browserversion:string:12:REGULAR\nstatus :=\
status:int:8:REGULAR\n",
"distributedNodeStats": {
"nodeCpuTime": "1.62s",
"nodeOutputRows": 500,
"nodeOutputDataSize": "75564B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": []
}]
}]
}
}]
}Sumber daya tambahan
Untuk informasi tambahan, lihat sumber daya berikut.
-
Lihat statistik dan detail eksekusi untuk kueri yang diselesaikan
-
Dokumentasi Trino
EXPLAIN -
Dokumentasi Trino
EXPLAIN ANALYZE -
Optimalkan Kinerja Kueri Federasi menggunakan JELASKAN dan JELASKAN ANALISIS di Amazon
Athena di Blog AWS Big Data.
